Concurrency and Locking
| One of the hallmarks of a true database management system is whether it has the capability to handle more than one user performing simultaneous data modifications. The problem is that when several users in a database make changes, it's likely that they eventually will all want to update the same record at the same time. To avoid the problems that this would cause, SQL Server and most database management systems provide a locking mechanism. A locking mechanism provides a way to "check out" a particular row or set of rows from the database, marking them so they cannot be changed by another user until the connection is finished and the changes are made. For connections that are reading data, locking provides a mechanism to prevent other connections from changing the data for the duration of the read or longer. There are two basic types of locks: shared locks and exclusive locks. A shared lock happens when a user is trying to read a row of data; for some duration, depending on the transaction isolation level (which is covered later in this chapter), the user owns a shared lock on the table. Because the user is just trying to read the record, there can be several shared locks on the row, so many people can read the same record at the same time. Users obtain exclusive locks when the user needs to change the row. Exclusive locks are not shared; there can be only one user with an exclusive lock on a row at any given time. Lock ContentionIf a user needs to acquire an exclusive lock to a row that is already locked by another user, the result is lock contention . Some level of contention is normal in a database that is being frequently updated. Typically, an application waits for some arbitrary amount of time for the locks to clear and the transaction to complete. This results in an apparent slowdown of the application and the server, and excessive amounts of contention lead to performance degradation and possibly user complaints. There are a few things you can do to reduce lock contention.
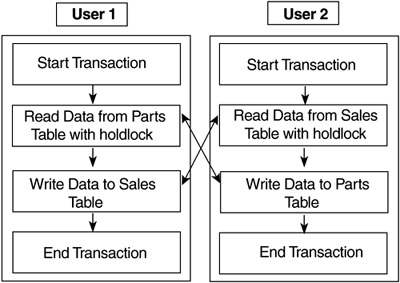
DeadlocksDeadlocks occur when two or more transactions cannot complete because of mutual locks. For example, if User A needs to update a row in the Deposit table and then a row in the Withdrawal table, whereas User B needs to update the Withdrawal table and then the Deposit table, there will be an instant in time when User A has an exclusive lock on the Deposit table and to complete his transaction he needs a lock on the Withdrawal table. Contrarily, User B has a lock on the record that User A needs in the Withdrawal table and needs a lock on the record in the Deposit table that User A already has locked. In this case, SQL Server detects the deadlock and more or less randomly kills one of the user processes. NOTE Who Lives and Who Dies? Which process is killed in a deadlock isn't exactly random. If one user is the System Administrator and the other one is just a normal user, the normal user's process is terminated. Otherwise, SQL Server picks the user that has the least to lose from having its transaction terminated . If they're both equal, then SQL Server picks one at random. It's also possible to set a connection-level parameter with SET DEADLOCK_PRIORITY LOW to tell SQL Server that the transaction can be terminated if it is involved in a deadlock. Deadlocking is very important, so the next few paragraphs repeat a lot of what you just read, but from a different angle, just to make sure you've got it down. In Figure 6.1, you can see that there are two users: User 1 and User 2. User 1 wants to do two things: read a record from the Parts table and write a record to the Sales table. User 2 wants to do two similar things, but he's going to read from the Sales table and write to the Parts table. Figure 6.1. This is an example of a set of transactions that could cause a deadlock. Now, step through what happens if both transactions start at the same time:
To avoid deadlocks, make sure that all the objects are always accessed in the same order. Make sure that in cases where a series of updates to different tables are done, they are always done in the same order. Keep transactions as short as possible, prevent user interaction within transactions, and set a low isolation level. What's an isolation level? Good question. Isolation LevelsSQL Server knows that sometimes it's critical that the data you are reading from the database is absolutely one hundred percent committed data, whereas at other times you want the data to be read quickly, and incomplete or uncommitted transactions just don't matter. To accommodate this, SQL Server supports four different transaction isolation levels:
There is one more aspect of locking to discuss. SQL Server also has the capability to lock objects at different levels to increase performance. This is called lock granularity . Lock GranularityIn addition to shared and exclusive locks, SQL Server also locks objects at different levels. SQL Server can lock a single row of a table, a single data page, or an entire table. Typically, SQL Server operates in the page lock mode, where it locks the data pages being requested . After a certain amount of blocking is noticed, SQL Server slips into a row locking mode, where single rows are locked. On the other end of the scale, when a connection attempts to update a certain percentage of a table, SQL Server automatically escalates to a table lock, where it automatically locks the entire table either exclusively (in the case of a full table update), or shared (in the case of a full table read). SQL Server also determines lock escalation based on the activity occurring in the table at the time of the lock request. If the activity level is low, it saves itself some time by just escalating the lock sooner because it will have less effect on other users. That means there are shared page locks, shared row locks, and shared table locks for reads, along with exclusive page locks, exclusive row locks, and exclusive table locks for writes . |
EAN: N/A
Pages: 228