Exercises The following set of exercises runs through the set of steps needed to create a basic physical environment. Each step requires that you have completed all subsequent steps and are thus better done in sequential order. 3.1 Creating a Database In Exercise 3.1, you create a database with two data files and a single log file. The exercise makes the assumption that SQL Server 2000 has been installed into the default locations and uses this location for all files. You might want to alter the actual file locations. Estimated Time: 5 minutes -
If the SQL Query Analyzer is not already open , load it to enable you to create a database using T-SQL commands. Supply the logon connection information if requested . -
Select the Master database from the database drop-down list box from the toolbar. -
Type the following command to create the database and accompanying files: CREATE DATABASE Sample ON PRIMARY (NAME = 'SampleData', FILENAME = 'c:\Program Files\Microsoft SQL Server \MSSQL\Data\SampData.mdf', SIZE = 10, MAXSIZE = 50, FILEGROWTH = 5), FILEGROUP Archive (Name = 'ArchiveData', FILENAME = 'c:\Program Files\Microsoft SQL Server \MSSQL\Data\ArchData.ndf', SIZE = 10, MAXSIZE = 50, FILEGROWTH = 5) LOG ON (NAME = 'LogStore', FILENAME = 'c:\Program Files\Microsoft SQL Server \MSSQL\Data\SampLog.ldf', SIZE = 1MB, MAXSIZE = 5MB, FILEGROWTH = 1MB) Go -
Execute the query. Check the Windows environment using the Explorer to ensure the files were actually created. You can check for the existence of the database and ensure the associated database properties were set up by running the sp_helpdb stored procedure. Note that when the database is created that there are two resulting filegroups. The Primary filegroup is used for data storage and the Archive filegroup is used for the storage of noncurrent data. 3.2 Creating a Table In Exercise 3.2, you create three tables within the database. One table contains contact information; the second is a table to list events in the upcoming year; the third table is for holding archive data for events that have already passed. Estimated Time: 10 minutes -
If the SQL Query Analyzer is not already open, load it to allow for the creation of the tables. Supply the logon connection information if requested. -
Select the Sample database created in Exercise 3.1 from the database drop-down list box from the toolbar. -
Type the following command to create the database and accompanying files: CREATE TABLE Contacts (ContactID smallint NOT NULL CONSTRAINT PKContact PRIMARY KEY CLUSTERED, FirstName varchar(25) NOT NULL, LastName varchar(25) NOT NULL, PhoneNo varchar(15) NULL, StreetAddress varchar(25) NULL, City varchar(25) NULL, ZipCode varchar(15) NULL) CREATE TABLE Events (EventID smallint NOT NULL CONSTRAINT PKEvent PRIMARY KEY CLUSTERED, EventName varchar(50) NOT NULL, EventLocation varchar(50) NOT NULL, ContactID smallint NOT NULL, EventAddress varchar(25) NULL, City varchar(25) NULL, ZipCode varchar(15) NULL) CREATE TABLE EventArchive (EventID smallint NOT NULL CONSTRAINT PKEventArch PRIMARY KEY CLUSTERED, EventName varchar(50) NOT NULL, EventLocation varchar(50) NOT NULL, ContactID smallint NOT NULL, EventAddress varchar(25) NULL, City varchar(25) NULL, ZipCode varchar(15) NULL) ON Archive -
Execute the query. Check the Object Browser to ensure the files were actually created. Execute sp_help with the table name to ensure that each table was appropriately created as follows : sp_help Contacts Go sp_help Events Go sp_help EventArchive Go Note that by supplying the ON clause for the EventArchive table that the table was placed onto a separate filegroup whereas the other tables were placed onto the PRIMARY file group . Also notice the existence of the Primary Key and an associated clustered index. 3.3 Setting Up Referential Integrity In Exercise 3.3, you alter the tables so that the Contact IDs of the Event table become Foreign Keys pointing to the Contact ID in the Contacts table. Estimated Time: 5 minutes -
If the SQL Query Analyzer is not already open, load it to allow for the creation of the tables. Supply the logon connection information if requested. -
Select the Sample database created in the previous exercise from the database drop-down list box from the toolbar. -
Type the following command to create the database and accompanying files: ALTER TABLE Events ADD CONSTRAINT FKEventContactID FOREIGN KEY (ContactID) REFERENCES Contacts(ContactID) ALTER TABLE EventArchive ADD CONSTRAINT FKArchContactID FOREIGN KEY (ContactID) REFERENCES Contacts(ContactID) -
Execute the query. Check the Object Browser to ensure the constraints were actually created. Execute sp_help with the table name to ensure each table was modified correctly: sp_help Events Go sp_help EventArchive Go Note that new constraints were added that reference the appropriate column in the Contacts table. Review Questions | 1: | How would you design a set of tables in a circumstance where the deletion of one record should cause the deletion of records in related tables? | | A1: | Configuring a Cascading Delete Action causes the deletion of a record to propagate deletions throughout the underlying related table. This option should be configured with caution, because the deletion of underlying data might not be desired. You need to set two tables up in a parent-child relationship, using appropriate Primary and Foreign Keys. Cascading Update Action performs a similar operation when key values are changed, propagating the new values to underlying child tables. | | 2: | What are the storage considerations in an extremely limited budget? What basic configuration requirements would be set up to ensure optimum data recoverability in the event of data corruption? | | A2: | First, put the log files onto a volume other than where the data is stored to ensure optimum recoverability. If possible, use a mirror on the OS volume to minimize downtime in a system failure. If the data volume becomes corrupt, a restore can be performed to get that data back. Having the log on a separate volume means that you can recover additional data because the log volume should be unaffected by the damage to the data. | | 3: | How do you use SQL Server 2000 technologies to maintain data integrity? | | A3: | Referential integrity is used to create a link between two related tables. A Foreign Key in one table references a Primary Key or unique index in the other table. Any entry to the table in which the Foreign Key resides must have a matching record in the table containing the Primary Key. Rules, constraints, triggers, and defaults all participate in maintaining data integrity. | | 4: | If data and indexes are stored in two different filegroups, what considerations are there for performing backups ? | | A4: | Both filegroups must be backed up within the same backup set whenever the indexes are separated from the data. Care must be taken so that the indexes always maintain pointers to the corresponding data. | | 5: | For what purposes does the term "schema" apply? | | A5: | In SQL Server, there are several uses of the term "schema." Information, Database, XML, and Warehouse all use schema to define the structure of elements, whether they be statistics, data dictionaries, data structures, or cube dimensions. | Exam Questions | 1: | You are working for a large international organization that supplies packaging materials for companies that require custom commercial designs. The number of products is becoming too large for the current computer system to handle and you need to provide a solution that will spread the load over the current server and a new machine coming into the system. Queries need to be performed over a wide variety of products and there is no predictable pattern to the queries. What is an appropriate technique to implement the changes? -
Configure replication using the new machine as a subscriber and the original machine as the publisher/distributor to balance the workload. -
Separate the table into two smaller tables and place one table on each server. Configure a partitioned view and appropriate constraints on each of the machines. -
Implement multi-server clustering so that each of the two servers can respond to data activities, thus achieving a balanced workload. -
Configure log shipping on both servers to have a copy of the data on each of the servers and propagate all changes to the alternate machine. | | A1: | B. This is a perfect example of where partitioning a table into two smaller objects enables you to use two machines to help reduce the load on the overall application. Remember that failover clustering is the only form of clustering supported by SQL and therefore does not actually reduce the load; it only assists in obtaining an around-the-clock operation. Log shipping assists in offloading query load, but does little to reduce update load because it leaves the second server in a read-only state. Merge replication may enable updates to span many servers, but the associated overhead and data latency makes it a less than desirable alternative. For more information, see "Partitioning to Achieve a Balance." | | 2: | As a developer for a large healthcare provider, you are assigned the task of developing a process for updating a patient database. When a patient is transferred from one floor to another, an internal identifier, CurrentRoomID , which is used as the Primary Key, needs to be altered while the original key, AdmittanceRoomID , is still maintained. If a patient is moved more than once, only the original key and the current key need to be maintained . Several underlying tables have been configured for referential integrity against the patient table. These underlying tables must change in an appropriate manner to match with one or the other of the room keys in the patient table. These relationships will be altered based upon different situations in other tables. Figure 3.11 illustrates the PatientTracker table design exhibit. What method would you use to accommodate the update? -
Use the Cascade Update Related Fields option to have changes in the Primary Key automatically update the keys in all referenced tables. -
Use an indexed view to enable the user to make changes to multiple tables concurrently. -
Disable the Enforce Relationship for INSERT s and DELETE s option to enable an AFTER TRIGGER to handle the necessary changes. -
Define an INSTEAD OF UPDATE TRIGGER to perform the necessary updates to all related tables. Figure 3.11. PatientTracker table design exhibit. 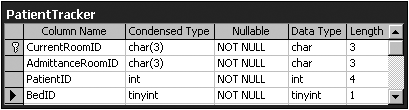 | | A2: | D. The INSTEAD OF trigger was designed specifically for this type of situation and also to handle complicated updates where columns are defined as Timestamp, Calculated, or Identity. Cascade operations are inappropriate because the updated key is not always stored. Indexed views by themselves do not allow for the type of alteration desired and would have to be complemented with the actions of a trigger. Disabling referential integrity is a poor solution to any problem, especially considering the medical nature of this application and the possible ramifications . For more information, see "Trigger Utilization." | | 3: | A large organization needs to maintain IMAGE data on a database server. The data is scanned in from documents received from the federal government. Updates to the images are infrequent. When a change occurs, usually the old row of data is archived out of the system and the new document takes its place. Other column information that contains key identifiers about the nature of the document is frequently queried by an OLAP system. Statistical information on how the data was queried is also stored in additional columns. The actual document itself is rarely needed except in processes that print the image. Which of the following represents an appropriate storage configuration? -
Place the IMAGE data into a filegroup of its own, but on the same volume as the remainder of the data. Place the log onto a volume of its own. -
Place all the data onto one volume in a single file. Configure the volume as a RAID parity set and place the log into a volume of its own. -
Place the IMAGE onto one volume in a file of its own and place the data and log files together on a second volume. -
Place the IMAGE into a separate filegroup with the log on one volume and the remainder of the data on a second volume. | | A3: | D. Because the IMAGE data will seldom be accessed, it makes sense to get the remainder of the data away from the images while moving the log away from the data. This will help to improve performance while providing optimum recoverability in the event of a failure. For more information, see "Using Filegroups." | | 4: | You are the administrator of a SQL Server 2000 computer. The server contains your company's Accounts database. Hundreds of users access the database each day. You have been experiencing power interruptions, and you want to protect the physical integrity of the Accounts database. You do not want to slow down server operations. What should you do? -
Enable the torn page detection database option for each database. -
Disable write caching on all disk controllers. -
Create a database maintenance plan to check database integrity and make repairs each night. -
Ensure that the write caching disk controllers have battery backups. | | A4: | D. Good controllers suitable for database use will have a battery backup. The battery should be regularly tested under controlled circumstances. Disabling caching if currently in place is likely to affect performance, as will enabling torn page detection. Torn page detection might help point out whether data is being corrupted because of failures. A maintenance plan is recommended, although it is not an entire solution in its own right. | | 5: | An Internet company sells outdoor hardware online to over 100,000 clients in various areas of the globe. Servicing the web site is a SQL Server whose performance is barely adequate to meet the needs of the site. You would like to apply a business rule to the existing system that will limit the outstanding balance of each customer. The outstanding balance is maintained as a denormalized column within the customer table. Orders are collected in a second table containing a trigger that updates the customer balance based on INSERT , UPDATE , and DELETE activity. Up to this point, care has been taken to remove any data from the table if the client balance is too high, so all data should meet the requirements of your new process. How would you apply the new data check? -
Modify the existing trigger so that an order that allows the balance to exceed the limit is not permitted. -
Create a check constraint with the No Check option enabled on the customer table, so that any inappropriate order is refused . -
Create a rule that doesn't permit an order that exceeds the limit and bind the rule to the Orders table. -
Create a new trigger on the Orders table that refuses an order that causes the balance to exceed the maximum. Apply the new trigger to only INSERT and UPDATE operations. | | A5: | A. Because a trigger is already in place, it can easily be altered to perform the additional data check. A rule cannot provide the required functionality because you cannot compare the data. The CHECK constraint may be a viable solution but you would have to alter the trigger to check for an error and provide for nested operations. The number of triggers firing should be kept to a minimum. To accommodate additional triggers, you would have to check the order in which they are being fired and again set properties of the server and database accordingly . For more information, see "Trigger Utilization." | | 6: | An existing sales catalog database structure exists on a system within your company. The company sells inventory from a single warehouse location that is across town from where the computer systems are located. The product table has been created with a non-clustered index based on the product ID, which is also the Primary Key. Non-clustered indexes exist on the product category column and also the storage location column. Most of the reporting done is ordered by product category. How would you change the existing index structure? -
Change the definition of the Primary Key so that it is a clustered index. -
Create a new clustered index based on the combination of storage location and product category. -
Change the definition of the product category so that it is a clustered index. -
Change the definition of the storage location so that it is a clustered index. | | A6: | C. Because the majority of the reporting is going to be performed using the storage location, it would be the likely candidate. The clustered index represents the physical order of the data and would minimize sorting operations when deriving the output. For more information, see "Index Organization." | | 7: | You are the sole IT person working in a small branch office for a non-profit organization that deals with natural resource conservation issues. A non-critical database is maintained on the data base server. You have been given the task of configuring appropriate database properties that would allow for a minimum use of execution time and storage resources. Which of the following set of properties is most appropriate? -
Full Recovery, Auto Shrink, Torn Page Detection -
Bulk Recovery, Auto Shrink, Single User -
Simple Recovery, Auto Close, Auto Shrink -
Simple Recovery, Auto Shrink, Single User -
Bulk Recovery, Auto Close, Auto Shrink | | A7: | C. Simple Recovery uses the least amount of log space for recording changes to the database. Full recovery uses the most space because it fully logs any bulk operations. Bulk recovery represents a mid-point between the two. Auto Close frees up resources at the earliest possible point during process execution, and Auto Shrink minimizes the space used in the file system by periodically reducing the files when there is too much unused space. For more information, see "Use of Recovery Models." | | 8: | You are designing an application that will provide data entry clerks the capability of updating the data in several tables. You would like to ease entry and provide common input so the clerks need not enter data into all fields or enter redundant values. What types of technologies could you use to minimize the amount of input needed? Select all that apply. -
Foreign Key -
Cascading Update -
Identity Column -
Default -
NULL -
Primary Key -
Unique Index | | A8: | B, C, D, E. All these options have activities that provide or alter data so that it does not have to be performed as an entry operation. In the case of NULL , data need not be provided, possibly because the column contains non-critical information. For more information, see "Table Characteristics." | | 9: | A database that you are working on is experiencing reduced performance. The database is used almost exclusively for reporting, with a large number of inserts occurring on a regular basis. Data is cycled out of the system four times a year as part of quarter-ending procedures. It is always impor tant to be able to attain a point-in-time restoration process. You would like to minimize the maintenance needed to accommodate increases and decreases in file storage space. Which option would assist the most in accomplishing the task? -
SIMPLE RECOVERY -
AUTOSHRINK -
MAXSIZE -
AUTOGROW -
COLLATE | | A9: | D. Use AUTOGROW to set the system so that the files will grow as needed for the addition of new data. You may want to perform a planned shrinkage of the database as part of the quarter-ending process and save on overhead by leaving the AUTOSHRINK option turned off. For more information, see "Creating Database Files and Filegroups." | | 10: | You are the administrator of a SQL Server 2000 computer. The server contains a database named Inventory . Users report that several storage locations in the UnitsStored field contain negative numbers. You examine the database's table structure. You correct all the negative numbers in the table. You must prevent the database from storing negative numbers . You also want to minimize use of server resources and physical I/O. Which statement should you execute? -
ALTER TABLE dbo.StorageLocations ADD CONSTRAINT CK_StorageLocations_UnitsStored CHECK (UnitsStored >= 0) -
CREATE TRIGGER CK_UnitsStored On StorageLocations FOR INSERT, UPDATE AS IF INSERTED.UnitsStored < 0 ROLLBACK TRAN -
CREATE RULE CK_UnitsStored As @Units >= 0 GO sp_bindrule 'CK_UnitsStored' 'StorageLocations.UnitsStored' GO -
CREATE PROC UpdateUnitsStored (@StorageLocationID int, @UnitsStored bigint) AS IF @UnitsStored < 0 RAISERROR (50099, 17) ELSE UPDATE StorageLocations SET UnitsStored = @UnitsStored WHERE StorageLocationID = @StorageLocationID | | A10: | A. You need to add a constraint to prevent negative data entry. The best method of implementing this functionality is a constraint. A trigger has too much overhead and the RULE is not accurately implemented. A procedure could handle the process but is normally only used for processes requiring more complex logic. For more information, see "Table Characteristics." | | 11: | You are the administrator of a SQL Server 2000 computer. The server contains a database named Inventory . In this database, the Parts table has a Primary Key that is used to identify each part stored in the company's warehouse. Each part has a unique UPC code that your company's accounting department uses to identify it. You want to maintain the referential integrity between the Parts table and the OrderDetails table. You want to minimize the amount of physical I/O that is used within the database. Which two T-SQL statements should you execute? (Each correct answer represents part of the solution. Choose two.) -
CREATE UNIQUE INDEX IX_UPC On Parts(UPC) -
CREATE UNIQUE INDEX IX_UPC On OrderDetails(UPC) -
CREATE TRIGGER UPCRI On OrderDetails FOR INSERT, UPDATE As If Not Exists (Select UPC From Parts Where Parts.UPC = inserted.UPC) BEGIN ROLLBACK TRAN END -
CREATE TRIGGER UPCRI On Parts FOR INSERT, UPDATE As If Not Exists (Select UPC From Parts Where OrderDetails.UPC = inserted.UPC) BEGIN ROLLBACK TRAN END -
ALTER TABLE dbo.OrderDetails ADD CONSTRAINT FK_OrderDetails_Parts FOREIGN KEY(UPC) REFERENCES dbo.Parts(UPC) -
ALTER TABLE dbo.Parts ADD CONSTRAINT FK_Parts_OrderDetails FOREIGN KEY (UPC) REFERENCES dbo.Parts(UPC) | | A11: | A, E. The UNIQUE constraint on the Parts table UPC column is required first, so that the FOREIGN KEY constraint can be applied from the OrderDetails.UPC column referencing Parts.UPC. This achieves the referential integrity requirement. It also reduces I/O required during joins between Parts and OrderDetails, which make use of the FOREIGN KEY constraint defined. For more information, see "Maintaining Referential Integrity." | | 12: | You are the database developer for a leasing company. Your database includes a table that is defined as follows: CREATE TABLE Lease (Id Int IDENTITY NOT NULL CONSTRAINT pk_lesse_id PRIMARY KEY NONCLUSTERED, Lastname varchar(50) NOT NULL, FirstName varchar(50) NOT NULL, SSNo char(9) NOT NULL, Rating char(10) NULL, Limit money NULL) Each SSNo must be unique. You want the data to be physically stored in SSNo sequence. Which constraint should you add to the SSNo column on the Lease table? -
UNIQUE CLUSTERED constraint -
UNIQUE UNCLUSTERED constraint -
PRIMARY KEY CLUSTERED constraint -
PRIMARY KEY UNCLUSTERED constraint | | A12: | A. To obtain the physical storage sequence of the data, you must use a clustered constraint or index. Although a Primary Key would also provide for the level of uniqueness, it is not the desired key for this table. For more information, see "Unique Indexing"in Chapter 10. | | 13: | You are building a database and you want to eliminate duplicate entry and minimize data storage wherever possible. You want to track the following information for employees and managers: First name, middle name, last name, employee identification number, address, date of hire, department, salary, and name of manager. Which table design should you use? -
Table1: EmpID, MgrID, Firstname, Middlename, Lastname, Address, Hiredate, Dept, Salary. Table2: MgrID, Firstname, Middlename, Lastname. -
Table1: EmpID, Firstname, Middlename, Lastname, Address, Hiredate, Dept, Salary. Table2: MgrID, Firstname, Middlename, Lastname. Table3: EmpID, MgrID. -
Table1: EmpID, MgrID, Firstname, Middlename, Lastname, Address, Hiredate, Dept, Salary. -
Table1: EmpID, Firstname, Middlename, Lastname, Address, Hiredate, Dept, Salary. Table2: EmpID, MgrID Table3: MgrID. | | A13: | C. A single table could provide all the necessary information with no redundancy. The table could easily be represented using a self-join operation to provide the desired reporting. Join operations will be discussed in detail in the next chapter. | | 14: | You are developing an application and need to create an inventory table on each of the databases located in New York, Detroit, Paris, London, Los Angeles, and Hong Kong. To accommodate a distributed environment, you must ensure that each row entered into the inventory table is unique across all locations. How can you create the inventory table? -
Supply Identity columns using a different sequential starting value for each location and use an increment of 6. -
Use the identity function. At first location, use IDENTITY(1,1) , at second location use IDENTITY(100000,1) , and so on. -
Use a Uniqueidentifier as the key at each location. -
Use TIMESTAMP column as the key at each location. | | A14: | A. Using identities in this fashion enables records to be entered that have no overlap. One location would use entry values 1, 7, 13, 19; the next would have 2, 8, 14, 20; the third 3, 9, 15, 21, and so on. For more information, see "Application of Integrity Options." | | 15: | You are building a new database for a company with ten departments. Each department contains multiple employees. In addition, each employee might work for several departments. How should you logically model the relationship between the department entity and the employee entity? -
A mandatory one-to-many relationship between department and employee. -
An optional one-to-many relationship between department and employee. -
Create a new entry; create a one-to-many relationship from the employee to the new entry; and create a one-to-many relationship from the department entry to the new entry. -
Create a new entry; create a one-to-many relationship from the new entry to the employee entry; then create a one-to-many relationship from the entry to the department entry. | | A15: | C. This is a many-to-many relationship scenario, which in SQL Server is implemented using three tables. The center table, often referred to as the connecting or joining table, is on the many side of both of the relationships to the other base table. For more information, see "Maintaining Referential Integrity." | Suggested Readings and Resources -
Inside SQL Server 2000 Kalen Delaney (www.insidesqlserver.com) Not a beginner book, but it fills in many of the gaps left out of the SQL Server Books Online documentation. Explains fully how SQL Server stores and processes data internally. -
SQL Server 2000 Books Online -
Creating and Maintaining Databases (Look particularly at the sections on indexes, views, and triggers.) -
Transact-SQL Reference (Use this as a resource for the specific syntax requirements of each statement, as well as some code examples.) -
Optimizing Database Performance (Focus on Database and Application Design.) -
Troubleshooting: Server and Database Troubleshooting -
MSDN Online Internet Reference (http://msdn.microsoft.com) -
Transact SQL Overview ( /library/psdk/sql/ts_tsqlcon_6lyk.htm ) -
Transact SQL Syntax Conventions ( /library/psdk/sql/ts_syntaxc_9kvn.htm ) -
Transact SQL Tips ( /library/psdk/sql/ac_8_qd_14_2kc3.htm ) |