Creating and Altering Indexes
Before you can implement an indexing strategy, you must know how to create indexes. Indexes can be created using both the Enterprise Manager or through T-SQL code. The syntax of the CREATE INDEX statement is as follows : CREATE [UNIQUE][CLUSTEREDNONCLUSTERED] INDEX index_name ON {tableview}(column[ASCDESC][,...n]) [WITH<index_option>[,...n]] [ON filegroup] <index_option >::={PAD_INDEXFILLFACTOR = fillfactor IGNORE_DUP_KEYDROP_EXISTING STATISTICS_NORECOMPUTESORT_IN_TEMPDB} The CREATE INDEX command has a variety of options that can be used to define the particulars of the index. Those options are as follows:
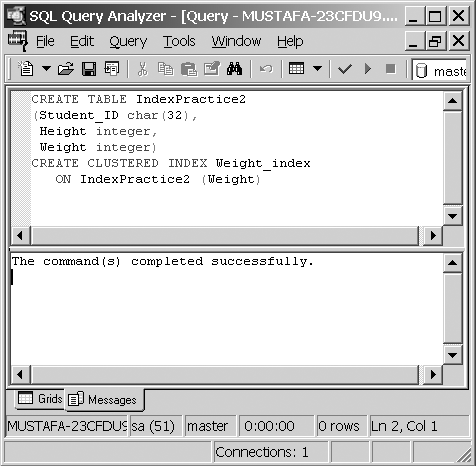
When you create a clustered index, an identical copy of the original table is taken, and then rows from that table are sorted. SQL Server then takes the original table and deletes it. The index created in Step by Step 10.1 will be used throughout the chapter.
You can also create indexes on the fly using the Enterprise Manager. A general summary of steps involved in doing this is outlined in Step by Step 10.2.
Creating nonclustered indexes is pretty much similar to the creation of clustered ones. To create a nonclustered index, follow Step by Step 10.3.
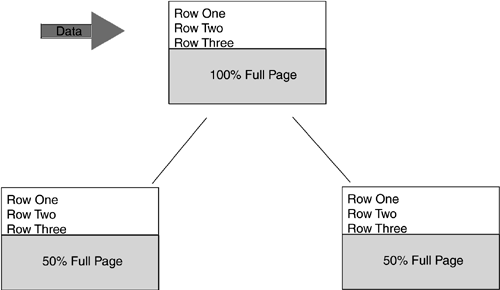
NOTE Finding Special Index Information Information on indexes is located in every database in the sysindexes system table. To find more information about indexes in your database, query the sysindexes table using SELECT * from sysindexes . For instance, the indid column in the resultset tells whether the index is clustered, nonclustered, or the columns contain image or text data. A value of indid >1 means that the index is nonclustered; indid=1 means that the index is clustered; indid=255 means that the table contains image or text data. The dpages column is the count of the data pages used for the index if the indid value is 0 or 1. If the indid value is 255, dpages = 0. If the value of indid is not 0, 1, or 255, then dpages is the count of the nonclustered index pages used by the index. Between 2 249 is nonclustered, 1 = clustered, 0 = heap. Composite indexes can be created on two or more columns. To create a composite index, specify two or more column names in the CREATE INDEX statement. The columns listed for composite indexes should be listed in sort-priority order. Composite indexes are best utilized when two or more columns are searched on a single unit. Columns involved in a composite index must be in the same table. A composite index can include 16 separate columns, up to a 900-byte limit. With so many options available, SQL Server indexing is flexible yet intricate to manage. Indexes need to be designed using the most appropriate indexing mechanisms required by an application. EXAM TIP Automatically Maintained Statistics Remember that statistics are automatically maintained on only the first column of a compound index, and in these cases the creation of addition statistics on all columns may give improved queries. UNIQUE IndexingA unique index ensures that the indexed column does not contain duplicate values. Unique is not actually a type of index but rather a property; thus, both clustered and nonclustered indexes can be defined as Unique . It only makes sense to use a unique index when the data on a column is to be unique, as in a Social Security Number (SSN) column. If you create an index on the SSN column of an Employee table, and a user types in an indistinct value for SSN , the table does not save the value and an error is generated. NOTE Automatically Created Clustered Index Creating a PRIMARY KEY or UNIQUE constraint automatically creates a unique clustered index on the specified columns in the table. The PRIMARY KEY constraint defaults to clustered unique; UNIQUE constraint defaults to nonclustered unique. Creating unique indexes is as simple as adding an extra word to the normal CREATE INDEX statement. After you have decided on creating a unique index, you can set the option IGNORE_DUP_KEY when calling the CREATE INDEX statement. If IGNORE_DUP_KEY was specified for the index and an INSERT statement that creates a duplicate key is executed, SQL Server issues a warning and ignores the duplicate row. IGNORE_DUP_KEY can be set for only unique clustered or unique nonclustered indexes. NOTE Unique Indexes It is betterand a more efficient processto create unique indexes rather than non-unique indexes, because all rows in a unique index are distinct. When SQL Server finds a row, it can stop the search (because there can never be two rows of the same value). Exploring FILLFACTORSimply put, the FILLFACTOR option specifies how full SQL Server should make each page when it creates a new index using existing data. The FILLFACTOR option is applied only when an index is being created or when maintenance activities reset the fill factor. Specify FILLFACTOR to leave extra space and reserve a percentage of free space on each leaf-level page of the index to accommodate future expansion in the storage of the table's data. EXAM TIP Setting the Fillfactor One topic that is sure to appear on the exam is setting the fillfactor for a page. Simply put, the FILLFACTOR option specifies how full SQL Server should make each page when it creates a new index using existing data. The FILLFACTOR option does not hold empty space over time, and the space will be taken up as data is inserted. Values can be set from 1100, expressed as a percent of the page to fill. The default value is 0; however, this does not mean SQL Server fills the page 0% full. With a value set to 0, SQL Server allows for a clustered index in which all data pages are full and for a nonclustered index in which all leaf pages are full. If 100 is specified as the fillfactor, SQL Server creates the indexes with each page 100% full, allowing minimal amount of storage space. Information concerning indexes can be viewed by using the sp_helpindex stored procedure. You may need to find out which columns are indexed on a particular table or how much database space indexes are taking. Step by Step 10.4 shows you how to do this. sp_helpindex 'objectname' NOTE Setting the FILLFACTOR Option The reason FILLFACTOR is specified is to increase performance. A smaller value for the FILLFACTOR means that the data pages will take more storage space and page splits will be minimized. On the other hand, a large value is suitable for read-only tables only, because low amounts of additional storage is consumed. SQL Server is more likely to perform page splits, firing back on performance. Page splits are shown in Figure 10.5. In deciding on an appropriate FILLFACTOR , you have to look for a balance between the needs of the users rendering data versus the needs of those making insertions. Figure 10.5. How a page split due to excessive inserts occurs. Where 'objectname' is the name of the object (view or table) from which you want to find index information.
Many commands assist in providing information about SQL Server objects. Other commands are covered later in the chapter during the discussion of index maintenance. After indexes are created, alterations may need to be made to have the index better suit needs. Altering Existing IndexesPeriodically, for maintenance reasons or to change some of the index properties, you are going to want to rebuild your indexes. In SQL Server 2000, rebuilding an index using the DROP_EXISTING clause of the CREATE INDEX statement can be efficient if you want to re-create the index in a single step, rather than delete the old index and then create the same index again. This is useful for both clustered and nonclustered indexes. Indexes can be created and altered through the Enterprise Manager, through CREATE INDEX operations, or through CREATE TABLE or ALTER TABLE statements. If you ever need to rename indexes, you can accomplish this by using the sp_rename stored procedure, as follows: sp_rename [ @objname = ] 'object_name' , [@Newname = ] 'New_name' [, [@Objtype =] 'object_type'] Where
Creation of tables is often performed through T-SQL using the CREATE TABLE statement with a full definition. A fully defined table would normally have entries included for Primary Key as well as other potential entries for UNIQUE constraints. Both these options create accompanying indexes. Index DrawbacksWith all the talk about indexes, you may think that indexes are virtually flawless. Nevertheless, this is not the case; improper use of indexes may result in excessive memory usage and hard disk space consumption, which cause undesirable results. Indexes have to be balanced; too many indexes may very well make processing slow; too few indexes may make database searches a time-killing process that is hard on you and your organization. It is a little tricky, at best, to select an appropriate indexing strategy, and maintaining it in the face of ongoing changes inherent in a database life cycle is even more of a challenge. Index maintainance over time is the next consideration. REVIEW BREAK: Review of Creating and Altering IndexesIndex creation and alteration are two necessary mechanisms in any indexing strategy. A database goes through a life cycle and will undergo size changes, application uses, and other growth. Any database system is in a constant state of flux as data is always being added, changed, removed, or otherwise affected by change. A solid indexing strategy is the first step in achieving success. Appropriate creation of indexes without using unnecessary additional ones is an involved process. Often other activities, such as table creations and other schema alterations, can also affect the number and types of indexes used. After the initial indexes are created and modifications have been made in testing, it is time for the real test: the end user. Indexing needs to be monitored to ensure that goals set for performance and response time are being met. Other system activity may also need to be monitored because indexing isn't the only technology affecting performance. Chapter 12, "Monitoring SQL Server," looks further into other performance tuning activity. |
EAN: N/A
Pages: 228
- Assessing Business-IT Alignment Maturity
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Technical Issues Related to IT Governance Tactics: Product Metrics, Measurements and Process Control
- Governance in IT Outsourcing Partnerships
- The Evolution of IT Governance at NB Power