6.3 Availability Across Geographies: Disaster Tolerance and Recovery
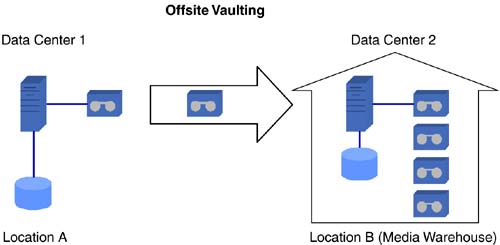
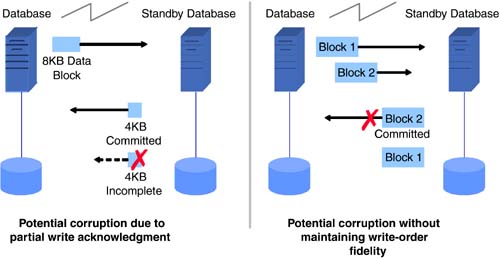
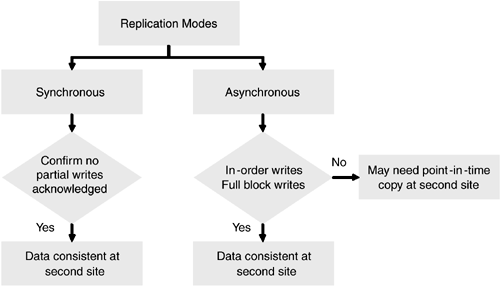
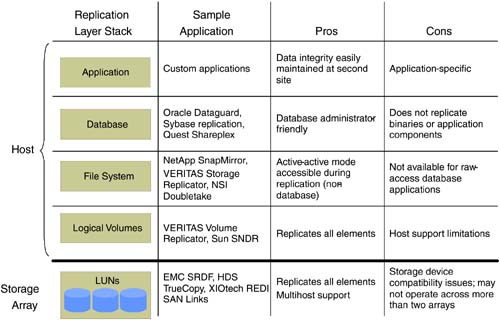
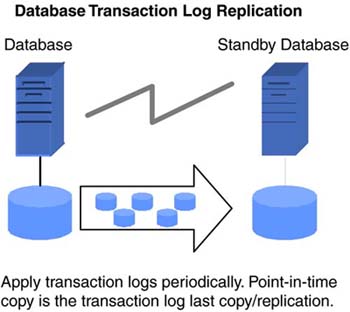
| The location of a secondary data center merits concern when planning for business continuance in the event of a data center outage . To minimize the possibility of simultaneous outages of the primary and secondary data centers, location choices include factors such as not sharing a single power grid and not being in the same earthquake zone. This usually leads to primary and secondary data centers in geographic locations separated by hundreds, if not thousands, of miles. Solutions discussed in the previous sections ”disk redundancy through RAID, clustering, and high availability ”have inherent distance limitations and may not be suitable for business continuance of most applications across geographies. Latencies imposed by distance and bandwidth considerations play a major role in the choice of disaster tolerance and disaster recovery solutions, some of which are discussed in this section. 6.3.1 Offsite Media Vaulting and RecoveryNot only do backups provide a fundamental level of availability within the data center, they are also the last line of defense in case of a disaster. A vast majority of disaster recovery implementations for business applications today solely rely on recovery from media backups . Backup media designated for disaster recovery are usually stored in an offsite location that does not share risk factors with the primary data center location. Often, third-party vendors in offsite media storage contract for this purpose. Services include backup media pickup from the data center, storage of media in temperature-and humidity-controlled vaults, media inventory management, and return delivery of expired backup media. See Figure 6-7. Figure 6-7. Offsite vaulting delivers geographic disaster tolerance. The offsite vaulting process starts with the formulation of backup and offsite retention policies. A sample backup policy could require full backups once a week and incremental backups once a day. In addition, the policy could require full backups on month-ends and year-end. The offsite retention policy could be retention of the daily incremental backups for two weeks, the weekly full backups for two months, the month-end backups for two years, and the year-end backups for 10 years . The backup and offsite retention policies should be based on the recovery point and recovery time objectives. In addition to storing backup media offsite, keeping extra copies of backup media in the data center avoids time and management overhead to recall media for simple day-to-day data restore events. This requires creating duplicate copies before shipping out the backup media to an offsite vault. Duplicate media copies can be created in parallel during the backup process using parallel backup streams, or they can be created at a later time from the primary backup set. The choice often depends on factors such as available backup hardware and duplication features provided by the backup software. Creating backup copies in parallel allows the media to be sent offsite upon backup completion. Running a duplication process after the first set of backups delays sending the media offsite. If a disaster were to occur during this process, causing both sets of copies to be destroyed , the most recent backup media available for recovery could be at least a day older. Before sending the backup media offsite, pick lists containing information on the media, contents, vault site slot locations, retention periods, and recall dates must be recorded. This information is usually shared between the data center customer and the offsite vault vendor. The process of duplicating media, ejecting the appropriate media from libraries, and creating pick lists can be automated either through the vaulting features available in certain backup software or through customized scripts, reducing the possibility of human error. Simple mistakes like ejecting the wrong media or setting incorrect retention can cause the disaster recovery efforts to fail. To ensure successful recovery in the event of a data center outage, detailed recovery procedures must be documented and the procedures periodically and comprehensively tested at secondary sites. In addition to fine-tuning and debugging the recovery procedures and validating the integrity of backups, frequent recovery tests also enable the responsible recovery personnel to attain a level of comfort and a degree of familiarity with the necessary steps for successful execution when it really matters. Depending on the amount of data to be restored, complete system recovery from backup media at a secondary site could take considerable time, and a large portion of data may need reentering or regenerating. In general, applications with RPOs and RTOs of a few days can employ offsite media vaulting and recovery as the primary means of business continuance. Even though applications with more stringent RPOs and RTOs have to look to other continuity methods , offsite vaulting provides added insurance. 6.3.2 Remote Mirroring and FailoverIn campus environments, buildings just a few kilometers away are often chosen as secondary disaster recovery data center sites. In most cases, these are chosen to supplement another disaster recovery site much farther away or as an initial phase in the implementation of a strategy that ultimately involves a site at a greater distance. The proximity of a secondary campus site makes issues of bandwidth and latency relatively insignificant and enables easy access to the primary data center personnel for maintenance and recovery. The proximity also makes it possible to explore the use of availability technologies used within a data center for cross-campus availability. Disk mirroring and failover technologies, discussed earlier for application availability inside a data center, generally require the host machine to be connected to the data storage devices through parallel SCSI cables or through a Fibre Channel-based network. Both interconnects impose distance limitations ”a few meters in the case of parallel SCSI and a few kilometers for Fibre Channel. Hence, Fibre Channel is better suited than SCSI for cross-campus availability. Providing disk redundancy between campus buildings typically involves a host machine at the primary data center connected to two storage arrays via Fibre Channel ”one in the primary data center building and the other in the secondary building. Volume management software on the host mirrors the two arrays. Adding a host at the secondary site, connecting it to the two arrays, and adding redundant heartbeat links provides key components for implementing automated failover between buildings using high-availability software. Fibre Channel extenders and other devices based on FCIP, iFCP, and iSCSI technologies make it possible for a host at the primary data center to be connected to storage at a secondary data center located hundreds or even thousands of kilometers away. Extending disk mirroring, high-availability, and clustering solutions beyond the campus environment using these devices is impacted by latency, but often less than expected, as outlined in Chapter 10, "Long-Distance Storage networking Applications." For certain applications using mostly read-only and performing fewer write operations, these solutions are worth exploring. The latency issues can be addressed by volume managers with a preferred mirror read feature that enables all reads to be performed using the mirror at the primary site while still completing writes at both sites. Remote mirroring and failover solutions, when used in a campus environment, provide application and data availability if the primary data center building suffers an outage. 6.3.3 Data ReplicationAs discussed earlier, most disaster recovery implementations require the separation of primary and secondary data centers at reasonably large distances. In addition, most business-critical applications perform a significant number of write operations. As a result, solutions using local mirroring and failover techniques across remote distances require exploration. Technologies based on replicating data between hosts over WANs, which provide various methods of addressing latency and bandwidth issues, are generally better suited for disaster tolerance and availability of business applications. 6.3.3.1 Modes of ReplicationData replication can be categorized into three modes: synchronous, asynchronous, and periodic. In all three modes, the application's read operations operate on the primary storage. While write operations have to be written at both the primary and secondary sites for all three modes, they differ in terms of when and how the write operations are performed. A write operation, in synchronous replication, is performed on the primary storage and simultaneously sent over a WAN to the secondary site. A successful write operation completes when both the primary and secondary storage acknowledge successful commits. As a result, the secondary site data always remains up to date with the data at the primary site. Activating the secondary site in the event of a primary site outage ensures that no data has been lost. However, the round-trip latency involved in committing the write at the secondary site can potentially impact application performance. Also, a network outage or hardware failure on the secondary site can cause write operations for the application at the primary site to be suspended when replicating in a synchronous mode. Writes, under asynchronous replication, operate on primary storage and are also queued at the primary site for transmission. Once these operations are complete, the application receives acknowledgment of a successful write. Depending on the available bandwidth, outstanding writes are then sent asynchronously to the secondary site. This eliminates the performance impact due to round-trip network latency. Also, a temporary network outage or hardware failure at the secondary site does not impact application writes at the primary site. Most applications stagger write activity. In other words, the write activity has peaks and valleys, without a steady stream of data blocks at a uniform rate. For example, an ERP application can write several megabytes per second during year-end processing, whereas it may write only a few kilobytes per second during nonpeak hours. With asynchronous replication, depending on the activity levels and available network bandwidth, both sites can be up to date or the primary site could have a number of outstanding writes not yet committed at the secondary site. As a result, in the event of a primary data center outage, activating the secondary site could result in lost data. The basic principles of asynchronous replication are shown in Figure 6-8. Figure 6-8. Intelligence required to avoid corruption during asynchronous replication. In periodic replication, data at the secondary site is updated at periodic intervals using data from the primary site. Just as in the case of asynchronous replication, application writes complete after acknowledgment from primary storage. Assuming local connection to the primary storage, no network round-trip latency is introduced. Periodic replication has the same exposure as asynchronous replication in terms of data loss at the secondary site. The main difference between the two modes lies in the usage of network bandwidth. The asynchronous mode attempts to replicate data continuously, using the available network bandwidth, while periodic mode starts the data replication at defined intervals. Asynchronous mode generally provides better data currency at the secondary site when compared to periodic replication. In order to ensure data integrity at the secondary site, especially for databases, logical application writes should be committed in their entirety, and write-order fidelity must be maintained within the application data set. Committing partial application data blocks or committing data blocks out of order in an application data set can result in data corruption. This rarely occurs in synchronous replication, since most implementations ensure primary and secondary site write completion before successful acknowledgment. However, implementations of asynchronous and periodic modes vary. Some implementations faithfully queue and replicate every logical write in its entirety and also maintain write ordering at the secondary, while other implementations may not be able to guarantee these attributes. Products in the latter category typically provide ways to periodically create and maintain consistent point-in-time copies of the data at the secondary. In the event of a primary site outage, recovery at the secondary site uses these point-in-time copies. Implementations that preserve write sizes and ordering at the secondary tend to provide better RPOs, since the more current replicated data set can be used for recovery instead of relying on an older point-in-time copy. The data consistency chart in Figure 6-9 helps put the replication modes in perspective. Figure 6-9. Data consistency chart. 6.3.3.2 Methods of ReplicationA significant number of business applications reside on databases. Data writes for such applications generally pass through various layers before being physically written to a storage device. Some of the typical layers are shown in the "stack" in Figure 6-10. Figure 6-10. Stack layers for various replication technologies. As data can be replicated at any layer in the stack, we explore each of these possibilities in more detail.
6.3.4 Secondary Site: Recovery and Other ConsiderationsBeyond the geographic location, several other factors require consideration for secondary sites. Some organizations have fully functional data centers located in different geographies, each potentially providing services for different applications. In such cases, each data center, while being the primary for its own applications, can also act as a secondary site for applications housed at another data center. For organizations with a single data center, the first step in disaster recovery planning starts with selection of a suitable secondary site. Apart from building and maintaining a secondary site with the required infrastructure, a hot-site can be leased from third-party vendors who also typically provide equipment and related site services for disaster recovery. Regardless of the ownership decision, periodic testing to ensure disaster tolerance and recoverability at the secondary site should be an integral part of the business-continuance plan. The testing process has to be as comprehensive as possible. It is not uncommon for some organizations to fail over application services on a regular basis and run them from secondary sites for an extended period. An additional benefit of being able to fail over to a secondary site is the flexibility to perform potentially disruptive maintenance tasks like hardware, software, and other infrastructure upgrades with minimal application downtime. When using data replication for disaster tolerance, hosts at the secondary site don't always need to be passive. For example, when replicating databases at the volume or storage array levels, second-site point-in-time copies can be activated for backup and reporting functions. This not only alleviates load on the primary system but also provides a mechanism for offsite tape storage without requiring physical transport. Activating application and data services from a secondary site in the event of a primary data center outage involves several steps. One of the first steps triggers an outage notification alert to one or more responsible personnel. The outage itself could range from an application service being unavailable for an extended period to complete inaccessibility of the entire data center. Since migrating applications and activating them from remote data centers is complex, a decision has to be made on the switchover. If the decision is to migrate, the process could involve promoting the secondary hosts to primary status and performing all the necessary tasks of activating volumes, mounting file systems, starting up the database, and activating applications. These tasks can be performed manually using written policies and procedures, or they can be automated using scripts or through commercially deployed software enabling wide-area failover. Automation is generally preferred, since it makes regular testing and the occasional migration for maintenance easier. More importantly, it provides a measure of predictability for disaster recovery and tolerance. |
EAN: 2147483647
Pages: 108