Modeling the Web Service
|
|
As we saw in Chapter 5, the first step we should take in designing our Web service is to define our model. Through this exercise we will examine the presentation, interface, and security models to make certain we have thought through all of our options before we start designing and developing.
The Presentation Model
The first component of our model to define is our presentation. This is where we determine how robust we want to make responses and how much assistance we want to provide for consumers. The first step to accomplishing this is determining our service's exposure level.
Since we are looking at a very user-interactive process, we will probably not use a masked service. Since a user must go through the availability service prior to making a reservation, this is not conducive to a back end process. That leaves us with the possibilities of an isolated service or an embedded service. To make this determination, we really need to identify our target consumers.
I mentioned earlier that we want to reach a broad grouping of consumers: ranging from travel sites to dedicated event sites. We are not targeting a specific travel site, but rather want to provide a service that appeals to all of them. The same goes for the event sites. This presents a bit of a challenge because we will likely be working with the two extremes of consumers in terms of experience and focus. The travel site will be working with several hotels and will probably expect us to match its requirements in terms of search criteria, response data, and any peripheral content. The event site may be very dependent on us, not only because they have fewer resources, but also because we may be the only Web service they are working with. The event coordinators are much more likely to give us control of the process and the entire experience related to the room reservation.
To reach these two targets, we should probably develop two different processes. Don't worry about duplication, because we will reuse much of the process in both. However, we need to think of each individually because of their very different needs.
In the case of the travel sites, the service will almost certainly be embedded in their existing application. They will want to own the entire user experience and maintain control over the process. For the event site consumers we will need to do much more handholding. That might go as far as being an isolated service and thus driving and owning the entire process. Let's say for the sake of argument that we don't want to miss any business opportunities with the events for which we establish discount agreements and will therefore take on that responsibility. That leaves us with one instance of our service capable of being embedded and another that can be isolated in an application.
The next step is to determine the amount of presentation information or assistance we want to provide. Again, we need to identify the type of consumer that we are targeting with our service to come up with an accurate answer.
In the case of the event site, we already determined that you need to provide an isolated service, and that means providing an entire presentation of our result information. Additionally, we need to provide user interface (UI) information for collecting both the search criteria and the user information for making the reservations. The next step, then, is to assemble a storyboard of the entire user experience for our isolated service. (See Figure 7-1.) The keys here are to identify the necessary information to capture and to create an interface that can interact effectively with users. Later we will actually design the interface in detail.
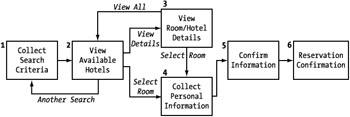
Figure 7-1: Storyboard for the isolated service user interface
| Note | Keep in mind that the storyboard design for your services is closely related to your process flow, discussed shortly. The two will impact each other, so don't consider this storyboard complete until you complete your process diagrams, and vice versa. |
For our travel site consumers, the presentation will be fairly light. We will provide some image references to views of our hotels and links to our site and further information, which they can use at their discretion, but for the most part the response will consist of the raw data without a lot of extraneous information. This translates into providing instruction-oriented content. No style data will be provided to the consumers. They are also not likely to need any assistance from us in collecting any of the user inputs, so there is no need to develop a story-board; our process flow will be sufficient.
The Interface Model
In defining the interface for our Web service model, we must look at the process we are exposing and the payloads that define our interaction with consumers. First we need to develop the process flow for our service. Just as we did in Chapter 5, start with the basic flow defined by the business requirements. (See Figure 7-2.)
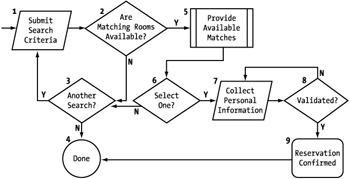
Figure 7-2: Baseline reservation system business process flow
Identifying the Process Flow
We first need to identify the process flow of the entire system without regard to how we will deploy this functionality. This process flow should define the workflow independent of whether it is to be developed into an application, a Web service, or another mechanism.
This process flow identifies the various states of the process and how they can be altered based on results or actions. This serves as our baseline, which we can modify to meet our intended output mechanism(s).
In this instance, we want to expose this functionality through a Web service. However, we have two different Web service models to target: isolated and embedded. The specific process flow for these two models will differ because different functionality relies on different owners. Whenever you have a scenario where you provide both an embedded and isolated service, you are better off designing the embedded service process first because it contains the core functionality of the Web service. Since the consumer is assuming responsibility for providing the process UI, less functionality is required of the Web service, and there is a less complex process flow. (See Figure 7-3.) Afterwards, the functionality specific to the isolated service can then be added to the embedded Web service.
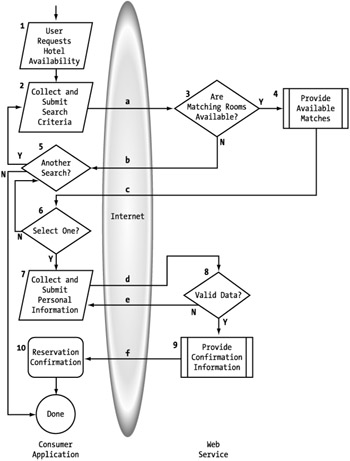
Figure 7-3: Modified process flow for embedded service consumers
Let's walk through this flow to make sure we have the process captured correctly. When the user initiates the process (Figure 7-3, step 1), the consumer collects the search criteria (2) and submits it to the Web service (a). The Web service runs a search based on the criteria (3) to determine if there are any matches. If a match is found, the service assembles the appropriate data on the available rooms (4) and responds to the consumer (c). If a match is not found, the consumer asks the user whether to execute another search (5). This may involve a slight modification or a completely new set of inputs. The distinction does not matter for this process or to the service. If the user finds an available room and wants to reserve it (6), the consumer proceeds to collect the personal information necessary to make the reservation request (7). If the user is not happy with the returned matches, the user again has the option to run another search with different criteria. When the appropriate information has been collected, it is submitted to the service for validation (8). If it cannot be validated, the service makes the appropriate response (e), and the consumer can attempt to collect the information again. If the information is validated, the appropriate confirmation information is assembled by the service (9) and sent back to the consumer (f), which displays it (10) and completes the process.
You should be able to tell from this diagram of the process that we are essentially looking at two requests (a and d) with dynamic responses (b, c and e, f). I will take a closer look at this in the next section when we define our payloads.
There is much more communication between the consumer and provider in the isolated process flow. This is necessary to facilitate the functionality exposed by the provider's service because the provider is assuming more ownership of the entire process. The consumer is taking a hands-off approach to the whole process and is simply giving the provider a space in which to execute its processes. (See Figure 7-4.)
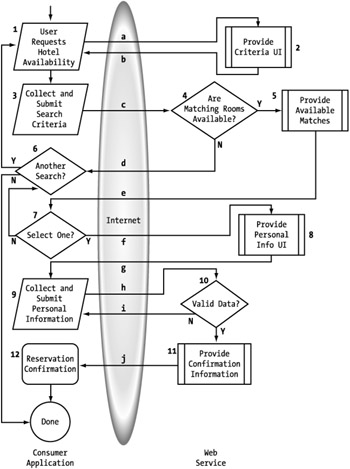
Figure 7-4: Modified process flow for isolated service consumers
The process is still essentially the same. The provider simply provides some extra functionality (or services) around the user experience. In some cases this is manifested through more robust payloads in the responses we have already defined. However, as you can see in Figure 7-4, this also usually requires additional interaction through requests and responses.
For most processes, this approach requires an extra request to establish the initial UI to begin the process. For our hotel availability service, this means defining the hotel search criteria presentation to the end user (2). The other extra functionality necessary for the isolated model of our service is the reservation request UI (8). You can see that each of these is a static request and response, and so the additional development effort required for this functionality is oriented more toward creativity than toward programming. Recognizing this will help you to determine the ROI for such functionality.
-
ROI-return on investment-is often a key business criterion when determining whether to invest money and resources in a proposed effort.
You'll also notice that, aside from the extra requests to the Web service, the consumer side of the process flow remains unaltered. The functionality we provide does not reduce the number of steps necessary on the consumer's part, but does reduce the amount of effort necessary for each step that interacts with the user.
Reconciling with the Presentation Model
Before defining the payload, it is imperative that you reconcile your process flow with your presentation model. A Web services process is not completely defined until it provides all the functionality demanded of the presentation model. Likewise, the presentation model must match the workflow defined by the process model.
This might strike some traditional developers or managers as being an unnecessary step if all participants fill their roles appropriately. This process will serve as a sanity check for the convergence of these two models. Developers with a UI-centric background and focus often define the presentation model. They should be thinking about the user's interaction with the application consuming the Web service. Conversely, developers that focus on the consumer's interaction with the service define the process model. These are two very different approaches that can result in very different designs. The process of developing and reconciling these inconsistencies is ultimately going to make the Web service a better offering because of the different approaches and mindsets addressing the model.
The inconsistencies themselves can manifest themselves in different ways. Quite often extra functionality can be added to the process through the presentation model definition. This occurs through the splitting of tasks into multiple UI steps or even combining tasks into a single UI screen. Likewise, the process model may expose issues or barriers the presentation model did not foresee or consider. To mitigate these issues, neither model should be considered complete until this reconciliation has occurred.
As it happens, we do have a few extra steps identified in our storyboard that were not captured in our process model. If you refer back to the storyboard in Figure 7-1 you will see that we have one step that allows for viewing of more detailed information on the room and/or hotel selected (3) and another step for confirming the user's information (5). We need to reconcile these differences and modify the models appropriately so that they are in sync.
The detail view step is a good example of how the presentation model exposes something the process model does not. The assumption likely made by the process model is that all availability information is viewed on a single screen. The presentation model took the approach of optimizing the initial view to compactly show all results and allow for a drilldown. A user who is taking a business trip and is merely staying one night may not need to view detailed amenities to make a decision on whether to stay in hotel A or hotel B. In this case, the user only needs to see high-level information such as price and proximity, since the rest of the criteria should be met based on the initial search information. This not only optimizes screen space on the presentation, but also optimizes our payloads to provide less wasted data that the user may not require. Since this streamlines the process for the average user, we should integrate this functionality into our process model. (See Figure 7-5.)
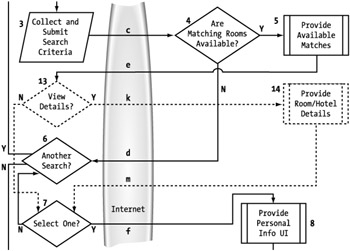
Figure 7-5: Hotel detail view for reservation service
Integrating this step is the same regardless of whether we define the isolated or embedded model, since it requires interaction with the Web service either way. In Figure 7-5, we have modified the isolated service model by adding two entities. The first entity allows the consumer to expose the decision of whether to view the details of a specific room or hotel to the user (13). If the user selects this option, the consumer sends the request to the service (k), and it packages this information together (14) and responds (m). If the user chooses not to view the details, the process continues on to the selection entity.
The second inconsistency between the presentation and process models is the confirmation of user information. This is standard functionality in Web-based applications to give the user the opportunity to change critical information like payment details. The decision that needs to be made here is where to maintain this step. For our embedded model, it makes sense that the consumer would handle this functionality. For the isolated model, this decision is a little more difficult. Going back to the user for a confirmation from a Web service is a very costly operation. There is really no need for going all the way back to the service other than that the consumer doesn't want to handle it.
One solution that works for an isolated model and yet does not require an extra round trip to the server is client-side script. The script can use a simple pop-up window confirming the entered information with the user. For efficiency's sake, we will take this approach. This step for both the embedded and isolated services is identical. (See Figure 7-6.)
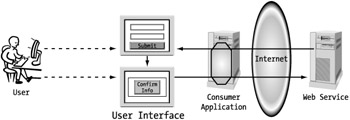
Figure 7-6: Confirmation of personal information for reservation request
With these changes, we now have a presentation model that matches our two process models, isolated and embedded. The next step is to drill down into the communication paths defined in our process model to define the payloads.
Defining the Payloads
The payloads we define for our interaction between the service and its consumers essentially define our interface. Although our two models have similar process flows, their payload definitions are very different. Like the process flow, the isolated service payload builds onto a core of information that is necessary for the embedded service. However, once the necessary presentation information is added, this relationship is virtually unrecognizable.
Since we are dealing with essentially two different services, we need to make a determination of distinction. How will we distinguish between a call for the embedded service versus a call for the isolated service? There are basically two approaches to handling this: differentiate externally or internally to the payload. Making the distinction externally means defining two different URLs for the two services. Internalized distinction means handling the requests for both services through the same location and using the payloads to make the distinction. Both approaches work, so this is simply an aspect of this particular model that we need to determine before we can move forward.
I prefer distinguishing externally for the benefit of eliminating additional checks in the service. We need to parse out data from the request to route our services to our business logic already, but in this case such an approach adds an extra layer of processing. When the distinction is externalized, it is already made for you, and each process can assume the service requested. The drawback to this approach is that you have two listeners, not one. With reuse of most of the overall functionality a strong likelihood, I consider the trade-off worthwhile.
The other decision we have to make is whether to define a unique interface for each model or incorporate them both into a single interface. To make this decision, we really need to understand what is involved with each model. If they are too dissimilar, it probably is not feasible to make a single interface, or at the very least it won't be very efficient. However, we don't want to duplicate designs or logic in an attempt to keep the interfaces independent. We know that the isolated service will build on the embedded service, but we can't be certain how much just yet. To make the best decision for our interface model, we had better model the two interfaces independently and then address this issue afterward. We will do so as part of the interface layer design later in this chapter.
Embedded Service Payload
Before looking at individual payloads, we first need to identify any system information we might need to maintain separately from the main data in every call. As we saw in Chapter 5, we can define header sections in our payloads to contain data that helps us to identify users and maintain state information.
Fundamentally, an embedded service requires less of this kind of functionality simply because the consumer owns more of the process. For our service, the only requirement we need to concern ourselves with is the sequence of availability lookup and reservation request. As I stated in our requirements, we want to catch attempts by a user to reserve a room that had availability determined at a much earlier time. It is not so much that we can't catch this later and handle it, but for the sake of this example I will assume that we want to manage this process to avoid extra overhead on the actual reservation system.
To accomplish this objective, we will develop a simple ID system that references a listing local to the service that provides the time the corresponding availability request was made for each reservation request. If the time was over 30 minutes prior to the reservation request or non-existent, the service responds to the consumer that the current selection is not available and another selection must be made. The consumer could modify the process slightly to more gracefully handle this result by redirecting the consumer to the availability search interface. We will place this ID in a service variable section, as discussed in Chapter 5.
The other determination we need to make is whether we want to manage the current state of the process via state variables. If every request payload is unique, we can simply load the payload and decipher the stage that is inherently obvious. However, the drawback is that not only are you adding process cycles to your Web service listener, but you are also building dependencies on your current payload structure. It is better to generate a system for managing the state whenever modeling Web services with workflow. Again, we will add this state data to our service variable header.
Another piece of information to consider is a consumer ID. We could use this to track the consumer from one step to another. Because of its very nature, we will want the Web service to authenticate the consumer on each call, regardless. This means that any state information we persist in our service variables is only useful on an application level. Depending on what method you are using for authentication, this may or may not be useful and/or necessary. Since we will be authenticating against client certificates, our service can access this information. This is much more reliable than any ID we pass, so we need not bother.
Now that we have defined our header information, we need to look at the specific request and response payloads that define the interactions. For the embedded model of our service, we have three interactions defined:
-
Availability request
-
Hotel detail view
-
Reservation request
Our embedded service has little concern for the presentation of this information, so these payloads essentially provide the appropriate data in a raw format. This allows the consumer to utilize the data in any way necessary to meet requirements.
Availability Request
The availability request consists of the data elements I listed in our requirements. At this point, the design of our payloads simply resolves the structure of the data and identifies which elements are required and which are optional. We will walk through the process of designing our payloads in the section about designing this Web service later in this chapter.
With the availability request payload essentially defined by our requirements, we need to turn our attention to its response payload. This is the data we have to assemble and return to the consumer on receiving this request. For our embedded responses, the payload is fairly direct, without a lot of extraneous information for presentation purposes. If we decide to pass on some extra nonessential information, we will utilize reference links to allow consumers to use it at their discretion while not overloading the payload.
Whenever you expose existing applications or processes as Web services, the response is based on the information returned from those systems. Because these systems were not designed as Web services, you will likely choose to either add more information or to use only a subset of that information. Working with what you get from these systems already gets you going in the right direction to defining your responses.
As identified in our requirements, we are working off of existing COM objects accessing our reservation system. For simplicity's sake, we will have a single object that exposes our functionality. You will need to reference a few different methods to return the correct information to the consumer. We already know the basic parameters from our requirements, so we will look at those specifics later when we start designing our service. Let's at least look now at the call and their returns, shown here:
Public Function fetchAvailability(...) As Variant() Public Function fetchHotel(...) As Variant()
The fetchAvailability method returns a two-dimensional array that contains the matching hotels based on the criteria submitted. This array consists of the following information, in this order:
-
Hotel ID
-
Proximity to location
-
Room type
-
Room rate
Unfortunately, this is only a portion of the data we need to retrieve. We need to reference the other method to get the detailed information on the hotel that users will need to make a decision on the available options.
Like the fetchAvailability call, the fetchHotel method also returns an array containing the information we are requesting:
-
Hotel name
-
Hotel manager
-
Hotel address
-
Hotel city
-
Hotel state
-
Hotel phone
-
Hotel amenities
As we look through the information passed, we can see that there is some information the user will not need to see, such as hotel ID and hotel manager. We could choose to completely leave this information out of the response. However, just because the user or consumer doesn't need the information doesn't necessarily mean that the information is not useful. You might find that utilizing some information "behind the scenes," perhaps through the service variables, can help with tracking or the functionality itself. In this example, the hotel ID might be such a piece of data. While we have not gotten there yet, we will in fact need the hotel ID for our detail view and reservation request. So we can only leave the hotel manager field out of our Web service response. That leaves our response with the following data (in no particular order):
-
Hotel ID
-
Proximity to location
-
Room type
-
Room rate
-
Hotel name
-
Hotel address
-
Hotel city
-
Hotel state
-
Hotel phone
-
Hotel amenities
For this service, we include a few additional pieces of information in our response to the user. One is a date element to help with "stamping" the resulting information. This can't actually be relied on as a true timestamp, since it can easily be altered and is specific to the current time zone, but it could be helpful for the presentation of the data and with any auditing or troubleshooting. We also turn around the data used to make the request. This is a nicety that may help the consumer with maintaining state for the current user. This will keep the consumer from needing to track the information that was sent to the service.
Hotel Detail View
Now that we have defined the availability request and response model, we need to turn our attention to the supporting detail view of the hotel information. This is not a function that is available through the reservation system, but rather something that was conceived for this particular service. This will largely consist of content providing additional information about the hotels that match the availability request. This function could be made generic enough to serve other purposes later, so we will take that approach.
As I just mentioned, we will utilize the hotel ID information from the availability request to make this request. In fact, we will allow that to essentially be the request, along with the service variables. The response then consists of the data listed in our requirements. Again, since this is an embedded service, we provide this information in raw XML form, allowing the consumer to determine how to use and structure it.
Reservation Request
Up until now we have been modeling the process leading up to making a hotel reservation. We have reached the point at which we can address the reservation process itself. We have the information outlined for us already, so we just need to determine if we need to make any changes or additions.
The existing COM object has a single call that can make a reservation request, as shown here:
Public Function makeReservation(...) As Long
I mentioned that we would need the hotel ID for this call. This is because the consumer may have more than one hotel match, so there is no way for us to know in that case which was selected without some kind of identification. Along with this, we will also need some of the matching criteria from the availability request. This information is not passed through the consumer, but rather we will maintain it on our side as part of the state managed by the session ID.
Personal and payment information is also required for the user to place the reservation. Since this data is fairly sensitive and critical, there is an opportunity to provide some validation information. However, since we are defining the embedded process, this is not something that can be done seamlessly. The consumer owns the UI, so we are not providing any content for the data entry steps. We can include the validation in the response of the availability request, but that potentially adds a lot of overhead. To avoid this, we can add just a reference (link) to the validation data maintained separately on our Web server.
For this scenario, we will pass on this approach. Our travel site would already be collecting payment data for other vendors, so they are not likely to need any validation code we generate. Of bigger concern would be the consumer's utilization of our reservation request schema. This helps to ensure that you don't have to reject the request due to bad data. We will take a closer look at this issue in more detail when we build our Web service in the implementation section, and consume Web services in Chapter 8.
Since we will not be adding any services, our reservation request ends up being very much a match of our requirements. We simply need to define how we want this information structured in our design, coming up in the design section.
The response from the reservation request essentially consists of the confirmation information. The system provides a confirmation number, but we also provide a phone number for further assistance (which will be the same for all reservations) and a description of any error encountered during processing. We package this into three elements:
-
Confirmation number
-
Phone number
-
Problem text
This completes the presentation model for our embedded Web service. Next, we need to step through this same exercise for our isolated Web service. This will build on the work we have done here by adding many more services and content to provide a complete user experience through the consumer.
Isolated Service Payload
Our isolated hotel reservation Web service provides a more complete UI for the consumer. This UI falls just short of being a complete Web page because consumers can make changes to our service as it passes through their system(s). Our data is still defined via XML, so they can still modify the content to more exactly match their look and feel.
As with the embedded model, we need to make a determination on our state management. Because this service represents the same process, we have the same requirements. They include identifying the current step in the process as well as tracking the session. It also makes sense then that we handle this data the same way, through the service variables. This also buys us some reuse across the two services, so we will take this same approach.
Some of the extra services our isolated service provides simply expand the existing interactions we have defined for our embedded service. However, some need to be exposed through extra steps. If we refer back to the storyboard we generated for our presentation model (Figure 7-1), we come up with the following interactions:
-
Availability form
-
Availability request
-
Hotel detail view
-
Reservation form
-
Reservation request
Availability Form
The availability form is the request that starts the entire process. The request itself essentially tells us who the consumer is, and we return the necessary information to define the input form for the user to make an availability request. The basic design is based on the availability request itself. The other decisions we have to make are how you should structure it and how much content we should provide.
Since we are assuming a lot of responsibility with an isolated service and the consumer can always modify the data, you should provide as much information as necessary to present a good interface to the user. This approach is even easier to justify, since we are providing a separate embedded service. If this were not the case, we would be adding a lot of overhead to the payload for consumers that would want to design their own UI.
For our availability request UI we will design an HTML form in a table layout, add some font treatments, and include the client-side validation. This provides an interface robust enough that it can be exposed "as is" to the end user. However, when we get to the implementation phase, we will see that the consumer still needs to provide some information so that the form we designed is submitted correctly through the consumer's system.
Availability Request
The availability request is the same as that of the embedded service. The response, however, is different because we provide some formatting. Like with the availability request form, we will put the response data in a table structure and include some font treatment. No data entry is necessary on this UI, so client-side validation is not necessary. However, we need to facilitate two activities from this interface, not just one. One activity is to make a reservation off of one of the matches. The other activity is the viewing of hotel details. Both of these are exposed through either buttons or links. Making this determination is not necessary until we get to design. It is just important that we identify the required functionality for our model so that you can identify the interactions and determine the extent of our presentation services.
Hotel Detail View
The detail view interaction is similar to the availability interaction in that the request does not change from the embedded model, but the response does provide some extra formatting to the existing response. Again, we will use a table structure to define the layout of this data and include some font treatment. The only activities available on this UI are to go back to the results view or make a reservation with the current hotel.
Reservation Form
The reservation form interaction is a new step added for the isolated process. This is only necessary in the isolated process because we are providing the UI and need a way to collect the appropriate information for requesting a reservation. Like the availability request form, we will build an HTML form that aligns to our reservation request interface. We will also provide this form in a table structure with font treatments and the appropriate client-side validation.
Reservation Request
Finally, we have the reservation request. This will follow the same process as the embedded reservation request. We will receive the data identifying the hotel and the room selected, and the response will provide a phone number and either a confirmation number or problem text, depending on whether the reservation was successful.
Looking back over these interactions, we can see that we have a lot of overlap between the embedded and isolated models of our service. The difference in the overlapping functions is actually just the response format. The data doesn't change, simply its presentation. For this service, we should try to aggregate these two processes into one for the sake of efficiency and reusability.
Combining the Two Services
To maximize the reuse of our logic and design we will take both of these services and turn them into one physical service with two interfaces. Taking the least common denominator approach, we will develop one set of logic for both services and simply modify the result as necessary for the service type requested. The two form requests can be left as is because they are not valid for the embedded service. That leaves us with a single process for both requests.
The other three requests (availability, hotel detail view, and reservation) are shared by both services. The requests are the same, but the responses are different. In each case, we need to provide data that is essentially XHTML to be exposed directly to the user. You can accomplish this in several different ways. The worst way is to actually code the logic to provide these two responses. This is needless because we have a tool at our disposal for taking our response data and transforming it into this XHTML: XSL.
We can define an XSL template that formats the data response we provide for our embedded service customers. The only question then is how to apply the template. The options are to apply the template before sending the response to the consumer or to simply reference the template in the response, allowing the consumer to provide it. There are tradeoffs in either scenario.
Applying the template before responding removes some logic on the consumer's side, but also "dumbs down" the response so that it can be very hard for the consumer to ever work with it. The data element tags are replaced by formatting tags; so referencing the data in the response is problematic, if not impossible.
Allowing consumers to apply the template gives them more access to the response on a data level, but also asks them to add some more functionality on their side. This approach would also reduce some of the workload on the Web service provider's system. Given the state of the parsers available today, the transforming of an XML document with an XSL template is becoming very simple, easily accomplished in just a few lines of code in nearly any language. For this reason, we will take the approach of allowing the consumers to apply the template.
This means that the only modification we have to make to the responses is the addition of the XSL template reference. We will add this node in the service variables section for only the isolated service type requests. Otherwise, every response is identical, ensuring the reusability of our application logic.
This completes the interface model for both service versions. We will complete the payload definitions in the design section, coming up later. Before getting to that, we need to define our security model.
The Security Model
The security model is a very important component to address before you get into the design of your Web service. As we saw in Chapter 5, this model consists of system access, application authentication, transport integrity, and payload validation. We need to determine how we will handle each of these areas.
One of the challenges with defining the security model is that it is not likely that your requirements will provide much direction in this area. The business driver is not likely to be aware of or understand these issues, so they are not in a position to address them. That usually means that your requirements may be dictated by your existing IT policies.
| Note | This may be your biggest challenge to deploying Web services. You may be pushing beyond the existing boundaries of your IT policies because Web services are such a new paradigm. That means that you might have to be the driver to change your IT policies. To do this, you will have to define your secure solution and convince your IT department that it is secure. You may also have to educate your business driver so that they can help to apply the necessary pressure. |
System Access
The infrastructure on which you are hosting your Web service will dictate most of your system access model. If you have an open connection to the Internet, anyone will be able to consume your Web service. If you build your Web service correctly, this will essentially be a harmless situation. However, you are opening yourself up to the possibility of people snooping around, making invalid requests, and/or using up your available bandwidth.
In this scenario, our Web service requires that a partner establish an account with us so that we can track activity and usage (as stated in our requirements). Since we are going to that trouble, we might as well require partners to provide us with the IP address or addresses from which they will be making requests. We can then add rules to our routers to only pass on requests to our Web service system from established IP addresses. Sure, IP addresses can be spoofed, but our objective is to limit the volume of invalid requests, and this rule will help.
The other issue we have to consider, especially if this is our organization's first Web service, is the hosting infrastructure. We have an existing set of COM objects through which we will access our reservation system. We could host the Web service directly on the application server with these COM objects, or we could go through ten systems to access the reservation system. I talked about these tradeoffs in Chapter 5, so I will avoid any further discussion about these options.
This is the hotel chain's first Web service, so we have a clean slate to start with. We will implement a proxy-host infrastructure that puts our Web service system in the DMZ and have it access the application server off the internal network. (See Figure 7-7.) We will put the appropriate measures in place to ensure that there is a secure tunnel between those two systems and that no one can access the application server directly through the Web server. The added benefit of this infrastructure model is that we could support a single or multiple application and Web servers supporting our Web services.
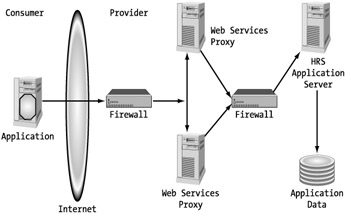
Figure 7-7: Web service proxy-host infrastructure
Application Authentication
Our application authentication model will be responsible for keeping unauthorized requests from getting processed by our service. This means that even a spoofed IP address that slips through our system access rules will not be handled by our service.
We can use any existing HTTP-supported mechanisms for providing authentication. This can include a variety of choices, as discussed in Chapter 5. If you recall, we actually have two authentication scenarios to consider. One covers the consumer and the other the end user. Fortunately, we can get by without authenticating the end user for this Web service because we have only a single transaction utilizing sensitive information: the reservation request. If we were going to store this information and have users come back to reference it for other reservations, this would definitely be an issue.
We do still want to authenticate consumers, however, so that we know they are partners and not unknown consumers. For this Web service, we will utilize certificates to authenticate consumers. This means distributing a file to each consumer, but since we are making them establish accounts, this is a minor addition to the existing process. When your infrastructure is set up correctly, this authentication will happen automatically by exposing your Web service through HTTPS addresses and configuring the site accordingly.
| Caution | There is a risk to distributing client certificates to some consumers, especially for an isolated service. If they are not technically savvy, you may find yourself having to walk them through the process of setting it up correctly. If you are going to be working with a large volume of consumers, this may not be a realistic option. We looked at this process in the "Implementing Certificate Security" section of Chapter 6. |
Although we are not concerned with the identity of the end user, we do want to identify an end user's session for the sake of processing requests appropriately. Remember that we will process a reservation only after an availability request is made; therefore we need to be able to match up their activities in a session. We can also use this functionality to track activities for audit purposes.
We have already taken one step for tracking activity by including a session ID in our system variables. That ID identifies the session for each request, but not the consumer. You might be inclined to incorporate a consumer ID, but that would expose a potentially serious security hole. This could be manipulated by the end user or the consumer to spoof another consumer, so we should not utilize this method for authentication purposes on a persistent basis. By persistent, I mean having consumers use a single ID for every request by every user.
We could, however, utilize the session IDs, established with the initial request of each session independently. During that request we could authenticate the consumer and tie that identity to the session ID through some data source. This session ID could then be traced back to the consumer once the consumer has been authenticated.
By using this session ID to track the consumer, as well as the session, we could not only meet the needs for the service, but also streamline our back-end processing of that information. Of course, this entire model assumes that the data is secure as it travels between the consumer and the Web services provider.
Transport Integrity
Without integrity, we can't really rely on the data transferred between the consumer and the provider. For some services, this may not be an issue. Since we are dealing with users' credit card information, this is very much an issue in this case.
Fortunately, we chose an authentication method that comes with an encryption service: HTTPS. This protocol utilizes SSL to encrypt the data sent between us and the consumer so that each end point can confirm not only the other party's identity, but also that no other party intercepts or modifies the data we send each other. Of course, that doesn't mean that we should implicitly trust the data itself.
Payload Validation
Unfortunately, we cannot be certain that the consumer is sending us the exact information we are expecting. After all, everyone makes mistakes, but we have to make sure that we do what we can to minimize the impact mistakes have on our systems, and thus on other consumers.
For this assurance, we need a method for validating a payload once it is received. Fortunately, we already have a method for this security via our defined XML Schemas. The definitions of our request payloads provide the template we need to check the requests made by our consumers.
We will utilize a parser that provides the function inherently when we process the payload. In this case, we will utilize the MSXML parser.
| Note | The MSXML 4.0 parser from Microsoft includes validation against XML Schemas. Previous versions supported only DTD validation of XML documents. |
|
|
EAN: 2147483647
Pages: 77