Defining XML
|
|
Because XML is a markup language, there is no internal mechanism for establishing the definition of a document. That fact caused the development and acceptance of other standards to fill this role. These standards work within the native abilities of XML to establish relationships with documents and define what a valid document is.
Because of XML's flexibility, standardizing a method for defining documents is quite an undertaking. XML is not a functional language, so you can't make passes through the code looking for key commands or definitions. In programming languages, you have a limited number of functional commands to be aware of. Variable names are also usually declared in the code with specific commands like "set" or "declare." In XML, any word can be an element name, an attribute name, or a value. Elements can be stacked any number of ways in multiple occurrences with multiple meanings. What number of approaches could you take to define the following code?
<name name=" name"> <name/> <name> <name name=" name"/> name </name> </name>
Of course you are thinking, "Who wants to do this?" The point is that this is legal code, and any means for defining an XML document would have to support it. Fortunately there are mechanisms like Document Type Definitions (DTDs), namespaces, and XML Schemas that help us to define our data.
The Document Type Definition
DTD was the first standard established to allow us to define XML data. In fact, DTD preceded XML a little because it was originally developed to work with SGML data. Of course, this transitioned to XML easily since it is an implementation of the SGML specification. DTDs allow us to specify data in great detail, defining required and optional elements, required and optional attributes, the relationships between our elements, and so forth.
While they do accomplish these objectives, DTDs have proven a little more difficult to work with in practice, mainly because DTDs use a unique language of their own. This issue is further compounded by the fact that DTD tags have a much more complex syntax than XML itself. That means yet another language to learn to define the documents we are creating in XML (the language we are concerned with)!
DTDs also cannot define data in enough detail for some implementations. For instance, DTDs have no way of defining the length of an element. While this may not be of concern for internal XML users, you will likely want partners less familiar with the service to know what the limits are of values being sent and received. Some applications would also benefit from knowing the data types of the elements involved. This could help consumers know whether they are working with numbers or strings.
| Note | A specification has been submitted to the W3C for defining data types in DTDs. The latest version of this specification, called Datatypes for DTDs (DT4DTD) 1.0, can be found at http://www.w3.org/TR/dt4dtd. However, this does not address the other challenges of working with DTDs. |
Despite this shortcoming, since DTDs were first and have been around so long, they have been widely implemented in applications and tools as the default standard for defining XML documents. Therefore, even though there are alternatives, we might have to support DTDs so that we don't exclude any potential consumers of our Web services.
Syntax
I will briefly cover some of the key concepts of the DTD syntax to help you understand the level of effort for building DTDs as well as allow you to build DTDs for some of your more basic documents.
Declaration Tags
While DTD does not use XML, it does utilize the markup language structure and does use tags for declaring components. These tags are used to identify entities, elements, attributes, and notations. Each tag is listed with its corresponding XML component in Table 3-2.
| COMPONENT | TAG |
|---|---|
| Attributes | <!ATTLIST ...> |
| Document | <!DOCTYPE ... [...]> |
| Elements | <!ELEMENT ...> |
| Entities | <!ENTITY ...> |
| Notations | <!NOTATION ...> |
You can see that the tags themselves are fairly straightforward. However, the full implementation of these tags is less so.
The first tag you need to become familiar with is the document tag. In a sense this is the document type declaration itself, as all other components fall within the brackets in the document tag. The name you give the doctype tag is that of the root element, and you can have only one doctype per DTD, for obvious reasons. A sample DTD might look like the following:
<!DOCTYPE customer []>
Entities
Entities define XML-compliant data that can be referenced throughout an XML document that references the DTD. Often a separate DTD is used to define environment information, similar to the concept of include files. Entity values can only be established in the DTDs and cannot be changed in the XML, so it is more appropriate to think of them as constants instead of variables. If the data is referenced in the XML, the entity declaration looks like this:
<!ENTITY fileroot "c:\temp">
When the entity is referenced in the DTD itself, the entity declaration looks like this:
<!ENTITY % fileroot "c:\temp">
To then reference this entity in the DTD, use the following code:
%fileroot;
Entities will not support non-XML-compliant data. To define or reference this kind of information, use the notation tag, as shown here:
<!NOTATION...>
Elements
When you define elements, you start with the element type declaration. This involves defining the name and content model for that type. At a minimum, you must define the name of the element for it to be a valid declaration. Do this by following the ELEMENT keyword with the name of the element, as shown here:
<!ELEMENT customer>
This does more than simply declare the existence of the element. However, declaring a content model after the element name provides more information. The content model provides a high-level definition of the acceptable usage of a subelement in an element. The options are defined in Table 3-3.
| DECLARATION | MEANING | SAMPLE |
|---|---|---|
| ANY | Any use | <!ELEMENT customer ANY> |
| EMPTY | No subelements | <!ELEMENT customer EMPTY> |
| (#PCDATA) | Character data only | <!ELEMENT customer (#PCDATA)> |
| (#PCDATA,...) | Mixed content can be used | <!ELEMENT customer (#PCDATA, address) > |
| (<values>,...) | Defined subelements used | <!ELEMENT customer (address, order) > |
EMPTY declares the absolute exclusion of any child elements. ANY is entirely open and is assumed when no content model is provided, as in our customer element definition earlier. PCDATA stands for parsed character data and basically communicates that the data in the element can contain text. Without this listing, an element could contain child elements and attributes but have no actual value itself. With this control, we can restrict our elements to have just data or to have data and elements. However, when you incorporate the #PCDATA control in your elements, you lose some ability to use other control mechanisms. One such mechanism is the evaluation controls. These are listed in Table 3-4.
| CONTROL | MEANING | SAMPLE |
|---|---|---|
| , | sequence | address, order |
| | | OR | address|order |
| () | grouping | (address|order), address |
In evaluating the content of an element, a comma is used to define a sequence, whereas multiple child elements may be defined. A vertical bar defines the logical OR selection, which means an option between two or more values exists. The parentheses are simply a means for grouping various values for more complex content definitions.
Another method for defining a content sequence is using the content occurrence characters listed in Table 3-5. These characters allow you to define the frequency of child elements in an element's content.
| CHARACTER | MEANING | SAMPLE |
|---|---|---|
| * | 0 or more instances | address* |
| + | 1 or more instances | address+ |
| ? | 0 or 1 instances | address? |
Building a DTD
To bring all of this together, let's look at a list of possible business rules. To define a customer in an XML document, our code will define a customer element that supports the following rules:
-
One first name
-
One last name
-
Multiple addresses, but at least one
-
Up to three street entries per address
-
Multiple orders with no minimum
-
A credit or checking account for each order
To make sure we have a good understanding of the requirements, it is often helpful to create an XML document or two that might serve as baseline samples to help us build our definition file. Here is a sample customer document:
<customer> <firstname>John</firstname> <lastname>Doe</lastname> <address> <street>320 Main</street> <city>Dallas</city> <state>TX</state> <zipcode>75234</zipcode> </address> <order> <creditaccount>4444333322221111</creditaccount> </order> </customer>
Now let's take a look at the DTD that defines this XML in the following code:
<!ELEMENT customer (firstname?, lastname?, address+, order*)> <!ELEMENT firstname (#PCDATA) > <!ELEMENT lastname (#PCDATA) > <!ELEMENT address (street+, city, state, zipcode) > <!ELEMENT order (creditaccount | checkingaccount) > <!ELEMENT street (#PCDATA) > <!ELEMENT city (#PCDATA) > <!ELEMENT state (#PCDATA) > <!ELEMENT zipcode (#PCDATA) > <!ELEMENT creditaccount (#PCDATA) > <!ELEMENT checkingaccount (#PCDATA) >
Notice how we had some limitations in how tightly we could match our requirements. First, we have no way of requiring one and only one instance of a child element as we might want to for the first name and last name elements. Also, we have no mechanism for limiting the number of street entries in our address element to three. These are some of the types of issues that were identified early on and the industry tried to resolve through the XSD standard.
Attributes
Now that we know how to define the elements and their children in a DTD, we will look at defining the attributes of an element. With a first glance at the tag for attributes, you might come to the correct conclusion that the ATTLIST tag contains the list of all attributes instead of singling them out. However, elements and attributes are not tied together through any hierarchical system the way the XML itself would link them. Instead, it relates the two based on the tag name of the element. For instance, if the element name is "customer," then the attribute is identified by the same name, as shown here:
<!ELEMENT customer> <!ATTLIST customer firstname lastname >
While this may seem unintuitive, it does give you the flexibility of separating the element definition from its defined attributes. Such an organization would, however, make it a little more difficult for human interpretation, as this example shows:
<!ELEMENT customer> <!ELEMENT order> <!ATTLIST customer firstname lastname > <!ATTLIST order number status >
Just as we had a way to define the existence of child elements in elements, we have the same control of the attribute definition. We can use the same controls for defining values in each attribute, but instead of the occurrence characters, the keywords in Table 3-6 define the instance restrictions.
| DECLARATION | MEANING |
|---|---|
| CDATA | Attribute value can be any character data. |
| #FIXED "value" | Required attribute; value specified in quotes. |
| #IMPLIED | Optional attribute. |
| #REQUIRED | Attribute value must be specified. |
| "value" | Attribute default value specified in quotes. |
If we go back to our customer business requirements, we can take a different approach to our definition by maximizing our use of these attribute declarations. If we transition some of our data from elements to attributes, our DTD is shown in the following code:
<!ELEMENT customer (address+, order*)> <!ATTLIST customer firstname CDATA #REQUIRED lastname CDATA #REQUIRED > <!ELEMENT address (street+) > <!ATTLIST address city CDATA #REQUIRED state CDATA #REQUIRED zipcode CDATA #REQUIRED > <!ELEMENT street (#PCDATA)> <!ELEMENT order (creditaccount | checkingaccount) > <!ELEMENT creditaccount (#PCDATA) > <!ELEMENT checkingaccount (#PCDATA) >
This code shows how the XML document produced from this definition might differ from our earlier definition:
<customer firstname=" John" lastname=" Doe"> <address city=" Dallas" state=" TX" zipcode="75234"> <street>320 Main</street> </address> <order> <creditaccount>4444333322221111</creditaccount> </order> </customer>
Notice how we split the address element content into child elements and attributes. The street data could not be transitioned to attribute data because we had to support multiple instances, which attributes cannot do. Although we have a tighter definition with city, state, and zip code now required, there are two reasons why this is not be a good implementation. First, we are taking one logical set of data and requiring an application that likely needs both to use two different parsing processes to extract the information. For reasons we will explore later, parsing attributes and parsing elements are two very different tasks, and you want to optimize your applications by utilizing one or the other (probably elements). Second, we are changing our data structure to comply with our data definition mechanism. This is akin to redesigning a database schema to fit inside a diagram view. If possible, we should make our definitions work for us, not the other way around.
To finish our coverage of the syntax of DTDs, let's look at a few very important rules that may not have been obvious during our examples:
-
Do not reuse the same element name more than once.
-
Make sure your document name matches the name of your root element.
-
Do not list child elements more than once in an element's declaration.
-
Do not list child elements whose definitions cannot be referenced.
Now that we know how to build DTDs, let's take a quick look at how we can use them to define and validate our XML data.
Implementation
An XML document can either contain the DTD or point to a DTD that contains its definition. This allows you to either reuse your definitions very easily and maintain efficient code or encapsulate all data and its definition in one file for simpler transport. Obviously you want to externalize your definition whenever possible so that you don't transmit extraneous information.
If you list the code directly, place the DTD code after the XML declaration tag, as shown here:
<?xml version="1.0" encoding=" UTF-8"?>
To reference an external DTD, identify the path to the DTD through the document declaration, as shown here:
<?xml version="1.0" encoding=" UTF-8"?> <!DOCTYPE customer SYSTEM "http://www.apress.com/customer.dtd">
Additionally, you can reference external DTDs from within the DTD itself. This can be helpful for reusing the definitions of elements in other DTDs. We can do this by loading an external DTD into an entity declaration and then exposing it directly in the document type declaration, as shown here:
<?xml version="1.0" encoding=" UTF-8"?> <!ENTITY % order.dtd SYSTEM "http://www.apress.com/order.dtd"> <!ELEMENT customer (firstname?, lastname?, address+, order*)> <!ELEMENT firstname (#PCDATA) > <!ELEMENT lastname (#PCDATA) > <!ELEMENT address (street+, city, state, zipcode) > %order.dtd; ...
At this point you should be comfortable with writing your own DTDs. However, even with this quick look we have run into a few barriers with this approach, and you will probably encounter more if you work further with DTDs. Fortunately, we have a new standard in development that can help us with some of these issues.
Namespaces
With the extensibility and flexibility of XML come a few potential data integrity issues that have to be addressed. One of these is definition for our data, which is addressed by DTDs or XML Schemas (which we will look at later in this chapter). Another integrity issue is the coexistence of matching tag names. This is where namespaces can be helpful. Namespaces are a mechanism for qualifying elements and attributes as part of an entity structure.
Understanding the Element Conflict Issue
You can think of namespaces as a categorization or grouping of tags that differentiates them from other tags utilizing the same names. Let's consider the potential problems of having common tags used in different ways for different elements. For example, how does one differentiate between element and attribute names that are reused in different contexts?
Consider this example:
<movie> <title>Forrest Gump</title> <actor> <character>Forrest Gump</character> <name>Tom Hanks</name> </actor> <director> <name>Robert Zemeckis</name> </director> </movie>
In parsing this data, how do you differentiate between the names of the actor and the director? If you know the complete path, you can make sure you are getting the name of the actor instead of the director, but without a definition file (which will sometimes be the case), a program may not be able to differentiate the two. This problem becomes even more obvious when sharing XML across organizational boundaries that implement XML in different ways.
Perhaps another organization uses the following document to describe the same information:
<movie title=" Raiders of the Lost Ark"> <actor character =" Indiana Jones" name=" Harrison Ford"/> <director name=" Steven Spielberg"/> </movie>
XML definitions can help clarify the data to others, but clearly something more is needed to distinguish the usage of common element and attribute names with different meanings. Fortunately, the W3C has defined a specification called namespaces that addresses this area.
Declaring Namespaces
The qualification namespaces provide is really just a formal declaration of a set of element and attribute names. The actual element name changes only slightly by the addition of a prefix. For instance, the <movie> tag might become <organizationa:movie>. You can think of the effect of declaring a namespace as similar to naming a place or person. To identify somebody as a girl is very general, but identifying that person as Lauren is more specific. Certainly there can be many Laurens in the world, but you are using a proper noun to identify her. So, in a sense, you can equate regular elements as nouns and namespace elements as proper nouns.
Do not confuse individually declared namespaces with standards. Although namespaces can be used to define standards (such as XHTML and XSLT), namespaces are a tool that can be used at anyone's discretion to help address the problem of uniquely identifying XML data. That means you could standardize your organization on using namespaces for every piece of XML that is created. However, this is probably overkill, since you can use just your XML definition files for defining XML structures. While namespaces don't require definition files (either DTDs or XML Schemas), you also don't need to use namespaces to define your data. Namespaces are a formal declaration of your XML definition, but there is actually no inherent relationship between the two other than the declarations in your XML document.
Each namespace should be declared as a Uniform Resource Identifier (URI) reference in the element of an XML document where you want to utilize it. This URI address actually points to nothing. It is simply using the URI as a global reference point that does nothing but assist you with the declaration of the namespace.
-
URN (Uniform Resource Name), URI (Uniform Resource Identifier), and URL (Uniform Resource Locator) are often used interchangeably and mean essentially the same thing: an address referencing information on a server accessible via the Internet or your intranet. There are subtle differences in their formal definitions that should specify what kind of information they can reference, but most uses do not make this distinction.
The following is an example of declaring the namespace for our first movie data set:
<movie xmlns:organizationa = "http://organizationa.com/schema">
In this example, xmlns is the attribute containing the URI value, and organizationa is the prefix value assigned to that namespace. The movie element is not actually identified as a component of the namespace. To accomplish this, you have to prefix the movie tag name itself, as shown here:
<organizationa:movie xmlns:organizationa = "http://organizationa.com/schema">
| Caution | Sample URNs, URIs, and URLs often point to a directory instead of a specific page in the directory. The implication is either that the destination has no real meaning (as is the case with namespaces) or that any request of that directory on the server will return a default page that provides the necessary information. The idea is that you can be more flexible in your definition files (for example, switching from a DTD to an XML Schema). This is not something a server does by default, so you or your Web server's administrator must set this up. |
Referencing Namespaces
This example should make it obvious that we have established a relationship between the namespace reference and the prefix "organizationa." Every subelement that has a declared prefix utilizes its corresponding namespace. However, this explicit declaration is not necessary when only one namespace is utilized because it is implied. For instance, the following two XML data sets work exactly the same way.
This is an explicit namespace reference:
<organizationa:movie xmlns:organizationa=" http://organizationa.com/schema"> <organizationa:title>Forrest Gump</organizationa:title> <organizationa:actor> <organizationa:character>Forrest Gump</organizationa:character> <organizationa:name>Tom Hanks</organizationa:name> </organizationa:actor> </organizationa:movie>
This is an implicit namespace reference:
<organizationa:movie xmlns:organizationa = "http://organizationa.com/schema"> <title>Forrest Gump</title> <actor> <character>Forrest Gump</character> <name>Tom Hanks</name> </actor> </organizationa:movie>
If you choose, or are forced, to use an explicit naming implementation, you may want to put more thought into the prefix you choose for your namespace reference. The prefix organizationa is quite long; org-a would probably suffice.
| Tip | Although some purists believe that no attempt to minimize tag names should be made because it contradicts the spirit of XML, I believe there should be some restraint. For instance, I would maintain some descriptive identity, but not take up excessive space with unnecessary text. More text means more data to send over the wire and more cycles for the parsers and writers working with the data. One character won't make much difference, but five characters actually add up to at least 15 characters (or 15 bytes) once you declare them and use them for one element (start and end tags). |
Referencing Multiple Namespaces
You might have noticed that I left out the director element from the last two code examples. This is because the name element was utilized as a subelement of the director element. Since our namespace had already declared the name element as a subelement of the actor element, we needed a second namespace for the director. Since we are working with a single structure here that will often, if not always, contain actor and director elements, this may be a case in which we should redesign our XML to make it easier to use one namespace. For this scenario, we will do away with the name element under the director element. This leaves us with the following data set:
<org-a:movie xmlns:org-a = "http://organizationa.com/schema"> <title>Forrest Gump</title> <actor> <character>Forrest Gump</character> <name>Tom Hanks</name> </actor> <director>Robert Zemeckis</director> </org-a:movie>
| Tip | This is an excellent example of a design decision that you may be faced with in the real world when working with XML.While you certainly don't want to compromise the integrity of your data model, you want to make it as easy as possible to build XML that is valid and logical. In this case, the overhead of using two namespaces for one data structure (which you own) is probably not worth the tradeoff of maintaining multiple uses of the name element. |
While this one namespace is a good solution for our movie data structure, some data structures will still need to reference more than one namespace when we start working with multiple forms of the same data. This will require not only two or more namespaces, but also explicit declaration of which namespace each element utilizes. Let's see what the utilization of multiple namespaces looks like by combining our current movie data model with the earlier attribute-centric movie data model. To maintain a well-formed XML structure, let's declare this information as a listing of available videos at a store (thus using videos as our root element). This definition is shown in the following code:
<videos> <org-a:movie xmlns:org-a=" http://organizationa.com/schema"> <title>Forrest Gump</title> <actor> <character>Forrest Gump</character> <name>Tom Hanks</name> </actor> <director>Robert Zemeckis</director> </org-a:movie> <org-b:movie xmlns:org-b = http://organizationb.com/schema title=" Forrest Gump"> <actor character =" Forrest Gump" name=" Tom Hanks"/> <director name=" Robert Zemeckis"/> </org-b:movie> </videos>
This is really the easy way to use two namespaces in one document. It could be argued that both namespaces should really be declared at the root element and referenced as needed in each element. This is somewhat analogous to declaring global variables versus declaring local variables, but without the same repercussions. This code shows what it looks like:
<videos xmlns:org-a = "http://organizationa.com/schema" xmlns:org-b =" http://organizationb.com/schema"> <org-a:movie> <org-a:title>Forrest Gump</org-a:title> <org-a:actor> <org-a:character>Forrest Gump</org-a:character> <org-a:name>Tom Hanks</org-a:name> </org-a:actor> <org-a:director>Robert Zemeckis</org-a:director> </org-a:movie> <org-b:movie title=" Raiders of the Lost Ark"> <org-b:actor character =" Indiana Jones" name=" Harrison Ford"/> <org-b:director name=" Steven Spielberg"/> </org-b:movie> </videos>
| Tip | You will want to minimize the number of times you reference a namespace in a given XML document. Accomplishing this may require defining your namespaces at a higher element level than absolutely necessary and then explicitly declaring your namespaces at each element, which requires a bit more effort. The reason you want to minimize the number of namespace declarations is that the parser has to handle the URI every time, and that really should be avoided when unnecessary. |
You can also exempt certain elements from namespaces that have been declared. Remember that all child elements implicitly assume a parent's defined namespace. You may sometimes want to "break out" of that with a child element. You can do this by simply defining a null namespace for that element like this:
<movie xmlns=""/>
| Caution | Some XML experts have stated that unprefixed elements do not belong to any namespace declared at any level, but section 5.2, "Namespace Defaulting," of the namespace specification clearly states that child elements implicitly reference their parent's namespace when no namespace has been declared. |
You can also reference namespaces at just the attribute level. You might want to do this to maintain a consistent data type or validation across different elements and schemas. In this example, we are using a namespace to help us define a list of monetary attributes:
<price finance:currency=" US">3.95</price>
Unlike some topics we have discussed, I have probably covered the majority of the specification for namespaces and have certainly covered all of the material relevant to our topic of Web services. Still, if you wish to cover every aspect, I encourage you to visit the W3C site or check out one of the many XML books available that cover namespaces.
The XML Schema
The XML Schema Definition Language (XML Schema, XSD) is the "new kid on them block" for defining XML documents. This is an attempt to modernize the DTD concept and adapt it for the specific needs of XML. With support for tighter validation and strong data typing, it does fill in some of the gaps of DTDs.
One of the biggest improvements in XSD over DTD is the definition language. XML Schemas are created using XML! That means you don't have to learn another syntax just to define your XML data.
At this point, XSD is merely a recommendation to the W3C, so it is likely to go through a few more changes before being finalized. You can find the current version of the specification and its status at the W3C site: http://www.w3.org/XML/Schema.
| Caution | My discussion of the XML Schema specification is based on the W3C Candidate Recommendation dated October 24, 2000. Any changes to the specification made since this recommendation will not be reflected, so take care in transferring any of this code or information directly to production applications. |
While there are many tools that already support the existing recommendations of XML Schemas, DTDs are also still widely used and supported. Unfortunately, the development and adoption of standards take some time. While most people would have a hard time arguing that XSDs are not better than DTDs for defining XML, these issues have caused hesitation for cautious vendors.
| Caution | Do not confuse XML Schemas with XDR (XML-Data Reduced) Schemas. XDR was a Microsoft-led attempt to define a new XML Schema language before the W3C started work on it. XDR has been replaced by XML Schema industry-wide and is now supported only by Microsoft parsers. |
I see XSDs as being the practical standard going forward for defining our XML documents. However, many implementations may need to support both for the sake of not excluding legacy XML applications. Instead of focusing on the details, I will cover just the main constructs and minimal requirements for defining schemas for Web services interfaces.
| Note | Who would have thought we would be discussing "legacy XML applications" at this point?! While some have been critical of the standards process, this really reflects the speed at which new standards can and have been developed and enhanced. |
The XML Schema specification is quite involved and defines a multitude of entities and scenarios. I will not cover the specification in all its details (that is quite easily a book in and of itself), but will merely cover the highlights that will allow you to build the basic schemas necessary for providing Web services and following the samples later in the book.
Schemas
Schemas are actually a collection of entities called schema components. There are 12 of these components in total, falling into three main categories as shown in Table 3-7.
| CATEGORY | COMPONENT |
|---|---|
| Primary | Simple type definitions Complex type definitions Attribute declarations Element declarations |
| Secondary | Attribute group definitions Identity-constraint definitions Model group definitions Notation declarations |
| Helper | Annotations Model groups Particles Wildcards |
We will focus on only a subset of these components, namely, the simple type, complex type, and attribute group definitions and the attribute and element declarations. As a byproduct of this discussion we will also touch on a few other components. There are several mechanisms allowing declarations and definitions that you can utilize in defining your XML documents.
The same high-level concepts of documents and content models from DTDs apply to XML Schemas. That means that much of your knowledge about DTDs should translate easily. For instance, we have a set of base tags that defines every entity in our definition as shown in Table 3-8.
| COMPONENT | TAG |
|---|---|
| Document | <schema> |
| Elements | <simpletype> or <complextype> |
| Attributes | <attributetype> |
| Data type | <datatype> |
Every definition starts with a schema tag. Every component of the XML document resides in the schema tag. So a valid skeleton schema document looks like the following:
<schema> </schema>
| Note | I will leave out references to the schema namespace until I address that in the next section. |
The schema element is simply a container for the actual definition. If it bothers you that the schema doesn't have a name, keep in mind that the schema is always the root node, and so the filename of the document is actually the name of the schema.
To populate this schema then involves adding a series of elements associated with data types. Unfortunately, this is where the simplicity stops. Schemas are very complex structures that have many rules to go with their flexibility. Like any journey, it is good to begin with a view of the destination. To let you know where we are going and what it will look like, I will give you a snapshot of a complete schema in Listing 3-1. If you are like me, you will want to jump right into it and dissect the syntax and code. However, I recommend not spending too much time looking into this code, since it is likely to confuse you if you do not have a good understanding of the building blocks, which I will attempt to provide in the remaining sections of this chapter.
Listing 3-1: Sample XML Schema
<?xml version="1.0" encoding=" UTF-8"?> <xsd:schema xmlns:xsd=http://www.w3.org/2000/10/XMLSchema elementFormDefault=" qualified"> <xsd:element name=" parent"> <xsd:simpleType> <xsd:restriction base=" child"/> </xsd:simpleType> </xsd:element> <xsd:element name=" child"> <xsd:complexType> <xsd:attribute name=" name" type=" xsd:string"/> <xsd:attribute name=" value"> <xsd:simpleType> <xsd:restriction base=" xsd:string"> <xsd:enumeration value=" yes"/> <xsd:enumeration value=" no"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> </xsd:complexType> </xsd:element> </xsd:schema>
At first glance, this schema can look rather intimidating, but the syntax can be broken down into sections, one piece at a time. The first step to learning how to build schemas is gaining an understanding of their data types. We will start there and work our way back up through schema structures to this level of complex schema.
| Tip | It will be much easier to work with developing schemas if you select a good tool. Some, like the current version of XML Spy (www.xmlspy.com), will even do much of the work for you by taking an XML document and generating a schema. Since there are multiple ways to define the same XML document, any automated program will make some assumptions, so you may have to modify the resulting schema to match your needs. |
Data Types
The fundamental distinction between XML Schemas and DTDs manifests itself through data types. Schemas are built on this fundamental structure, whereas DTD is only now trying to integrate data typing into its definition of an XML document. The XML Schema specification itself has been defined in two sections, one for data types and the other for structures. The structures section defines the language itself, and the data types section covers the valid mechanisms for defining data types in schemas.
-
Data typing is the process of defining the lexical and value space of data elements to closely match their intended use.
The root of this distinction between DTDs and XSDs is actually the intent of each standard. DTDs were designed to define documents. Of course any valid XML data set is actually a document, but they can be very different in their approaches. As I pointed out in the "Attributes" section earlier, you can represent the same data through two very different designs by utilizing attributes versus elements and subelements. Choosing the attributes approach creates a more document-oriented XML base, whereas utilizing elements begets a more data-oriented XML base. Attributes are harder and more costly to access and validate, so when this is necessary, pushing those values to elements makes the data more accessible and results in a "tighter" document. XML Schemas were designed as a tool for developers taking this approach.
| Caution | Although XML Schemas allow you to specify more of your XML data in greater detail, it comes at the cost of efficiency. Schemas can take up to four times the code of DTDs to define the same documents. Remember, DTDs were designed solely for document definition, whereas schemas utilize XML, so it has to be much more self-describing. The tradeoff will become much less as more tools for building schemas become available. |
There are two steps to declaring elements in a schema. The first step is to declare the data type(s) for that element. That is what we are discussing in this section. Once that is done, you must declare the element(s) utilizing that data type. We will discuss that in the following section.
Data types come in two different varieties: primitive and derived. Primitive data types are also referred to as the base types since they are not based on any other data type. Derived data types can be thought of as compound data types based on primitive or other derived data types. The idea of compound or derived data types should not be confused with complex type elements, which we will discuss in the next section.
Primitive Data Types
Table 3-9 shows a list of the available primitive data types in the schema specification. With these, you can both define data fields and generate new data types based on these base types. The only data types that are probably new to you and specific to schemas are recurringDuration and timeDuration. Other defined data types are used for namespaces but fall outside the scope of this book.
| NAME | DESCRIPTION | PATTERN |
|---|---|---|
| binary[*] | a base 2 number | 0|1 ... |
| Boolean | a true or false value | true|false |
| decimal | a base 10 number with a specification below 1 | d.d... |
| double | a 64-bit representation of a float | +|- d... |
| float | a 32-bit, base 10 number that can be positive or negative | +|- d... |
| recurringDuration | a period of time that is recurring | yy-mm-ddThh:mm:ss.sss |
| string | a finite sequence of characters | |
| timeDuration | some duration of time | PyymmddThhmmss |
| uriReference | a network or system resource reference | |
| Note: Capital letters in the patterns represent required constants. | ||
|
[*]The binary data type is not valid directly in schemas. According to the specification, such usage should cause an error in the schema. This data type is intended only as a base type for other derived data types. | ||
Another data type available through schemas is the generated data type timeInstant. This is a single instance of time based on recurringDuration that specifies the century. Its pattern looks like ccyy-mm-ddThh:mm:ss.sss. Additionally, the time zone can be added by a Z to the right followed by a plus or minus sign and the hh:mm pattern representing the difference between the time zone and the local time.
These data types can be qualified in two ways: ordered and unordered. Ordered data types are those with values that fall in a specific sequence. For example, numbers increment from one value to another, say, 1 to 999. Unordered data types are not so restricted and are fairly independent. Instead of thinking of the different data types as either ordered or unordered, think of the ways in which they could be defined. For instance, a timeDuration certainly has a sequence, but it may also have defined, enumerated values.
Each of these two aspects has its own corresponding attributes. These attributes are used to either extend or restrict the data types used to declare the elements in your data. These are listed for you in Table 3-10. Understanding these attributes should help you grasp the difference between ordered and unordered data.
| ORDERED | UNORDERED |
|---|---|
| duration | encoding |
| maxExclusive | enumeration |
| maxInclusive | length |
| minExclusive | maxLength |
| minInclusive | minLength |
| period | pattern |
| precision | whitespace |
| scale |
Ordered Attributes
Notice the commonalities between the ordered attributes in Table 3-10. Each attribute relates to some kind of range. It could be either a value range or a sequence range, but it definitely leads to a restriction of values. These attributes obviously are very appropriate to numbers, times, calendar dates, and even artificial sequences. Let's look at a few of the more common ordered attributes in more detail.
When you define ordered data types, the exclusive and inclusive sets are invaluable for defining ranges. I'm not quite sure why both implementations were incorporated into every numeric data type, but for floats and doubles, the restrictions can allow you to specify the range on a more granular level. For example, the exclusive range of the set (0.0,10.0) allows values only up to 9.9999..., but the inclusive range includes 10.0000... exactly. Since precision is arbitrary for floats and doubles, this may be your only avenue for defining the value exactly. I recommend using decimal numbers, when possible, to avoid this situation, since it offers precision through the scale attribute.
| UPDATE | The W3C Proposed Recommendation of March 30, 2001, changed the scale attribute to the fractionDigits attribute and the precision attribute to the totalDigits attribute. They have the same meanings, just different names. Depending on the tool you are using, it may recognize both or just one or the other. |
I recommend that you standardize on one method to maintain consistency in both your data and your parsing applications. The tools you use to build your XML may standardize this for you, but sometimes you may want or need to define schemas manually. Also, if you have not standardized on XML tools, they may take different approaches, which will then be implemented across your organization. In general, I prefer to use inclusive ranges, since that is the typical syntax in most programming languages. Basically, the use of the exclusive set means the values defined are outside the range of your element, as shown here:
<simpleType name=" exclusiverange"> <restriction base=" integer"> <minExclusive>0</minExclusive> <maxExclusive>101</maxExclusive> </restriction> </simpleType>
while use of the inclusive set means the values are in the range of your element, as shown here:
<simpleType name=" inclusiverange"> <restriction base=" integer"> <minInclusive>1</minInclusive> <maxInclusive>100</maxInclusive> </restriction> </simpleType>
The previous two code segments define the same range, 1 to 100.
The precision attribute is used to declare the number of digits used to define a number. The scale is then used to declare the number of specific digits, or those digits to the right of the decimal, to define the number. The logical conclusion is that the scale value is always smaller than or equal to the precision value. The following is the realNumber element that utilizes the precision and scale attributes:
<simpleType name=" realNumber"> <restriction base=" real"> <precision>9</precision> <scale>2</scale> </restriction> </simpleType>
Unordered Attributes
The unordered attributes contain many of the properties a developer would look for in limiting the possible values for very open data types. These attributes obviously have to be much broader in their application and are generally used in combination to formulate a meaningful data type for a document.
When you define the length for a data type, you actually have a couple of options. How you handle length affects how you program your applications to handle unordered data, so make these decisions carefully. First, you can define length like this:
<simpleType name=" firstName"> <restriction base=" string"> <length>20</length> </restriction> </simpleType>
The necessary design decision here is "How do you handle this?" To better phrase this question, look at this alternative schema for firstName:
<simpleType name=" firstName"> <restriction base=" string"> <maxLength>20</maxLength> </restriction> </simpleType>
Depending on how your logic is developed, there may be no difference between these two definitions. There may, however, be some size implications when using length, since that attribute defines a fixed size, which the existing data may not utilize completely. The duplication of logic necessary to handle both is unnecessary, so I recommend not implementing both in the same document. Fortunately, the specification prevents the same data type from utilizing length and either the maxLength or minLength attribute. Unfortunately, when working with XML data from outside your control, you may have to accommodate both meanings for similar nodes in different documents.
The reason for this discrepancy usually has to do with the source of the data and its intended use. If this firstName data element came from a database and is intended for recreating a database, length would likely be used. However, if the firstName data element is defined only as an interface element, a minLength as well as a maxLength property may be specified to ensure that the data can be validated against the business requirements. The best way to handle this is to stick primarily with the minLength and maxLength attributes when necessary and avoid the length attribute due to its ambiguity.
Whitespace is an attribute that is especially important on a data level for handling bulk text. This attribute has three predefined values that allow you to dictate the amount of normalization performed on the text: preserve, replace, and collapse. The preserve value means that no normalization should be performed on the string, so it does not change. The replace value means that all special layout characters (for example, tab, carriage return) are replaced with spaces. That means that this data:
<data> Jere Left Wing Mike Center Brett Right Wing <data>
is interpreted as this:
<data>Jere Left Wing Mike Center Brett Right Wing<data>
Finally, the collapse value communicates that all sequences of spaces should be compressed to single spaces (as browsers do with HTML).
Enumeration is one of the more important attributes you will use when defining your data. This is the mechanism for declaring the acceptable values for the field. For instance, to define a field called "sports," you could use the following schema:
<simpleType name=" sports" base=" string"> <enumeration>Baseball</enumeration> <enumeration>Basketball</enumeration> <enumeration>Football</enumeration> <enumeration>Hockey</enumeration> <enumeration>Soccer</enumeration> </simpleType>
The only valid values for the sports node would be Baseball, Basketball, Football, Hockey, and Soccer. (My apologies to the tennis players out there!) There is no mechanism for dictating order or preference through this attribute, so the application of this constraint may not be exactly as you intended.
| Caution | Remember that an application has to actually enforce the specification by interpreting and performing the functions based on these attributes. A tremendous amount of work is necessary to utilize the rules in the specification, especially for those applications generating XML data. Some of this is done in some of the XML parsers available, but much of it must fall to your applications generating and utilizing the data. |
Derived Data Types
Now that we know how to define and restrict our primitive data types, we can start to create our own. These would be called derived data types. These constructed data types are built by "inheriting" the simple types and further defining the different properties.
Many derived data types are also available directly from the specification. These are all based on primitive types or on another derived type. The derived data types provided by the specification are often referred to as "built-in." Some of the more common types are listed in Table 3-11, but you will need to refer to the specification for the current complete list.
| NAME | DESCRIPTION | DERIVED FROM |
|---|---|---|
| CDATA | represents whitespace normalized strings | string |
| date | a specific day | timePeriod |
| integer | any whole number | decimal |
| language | language of the text | token |
| long | an integer between 2^64 & -2^64 | integer |
| time | the time of a specific day | recurringDuration |
| timeInstant | single instance of time | recurringDuration |
| token | a nonsequenced string | CDATA |
Simple Types
To create these derived data types, we have to utilize simple types. A simple type is an element that allows us to extend our base data types to generate derived data types. This is done by declaring a base type and restricting the available attributes. Simple types cannot extend data types, so only the existing attributes can be defined; no new attributes may be added to the base type. Let's walk through a few examples.
To define the long data type, we first have to define the integer data type by basing a simple type off a decimal and defining the scale as 0, as shown here:
<simpleType name=" integer"> <restriction base=" decimal"> <scale>0</scale> </restriction> </simpleType>
Next, we will base another simple type called long and define the range to accommodate the appropriate values, as shown here:
<simpleType name=" long"> <restriction base=" integer"> <minInclusive>-9223372036854775808</minInclusive> <maxInclusive>9223372036854775807</maxInclusive> </restriction> </simpleType>
Let's look at another example that isn't number based, but time based. Time stamping can be an important part to creating an audit trail during integration processes, so let's derive the built-in timeInstant data type.
| UPDATE | The W3C Proposed Recommendation of March 30, 2001, changed the derived timeInstant attribute to dateTime base type. Since it is now a base type, the concept of deriving it is no longer appropriate. Additionally, the recurringDuration type was changed to the time data type, and the timeDuration to the duration data type. They have the same meanings, just different names and definitions. Depending on the tool you are using, it may recognize both specifications or just one of them. |
First, we will base it on the recurringDuration base type, which represents a repeating period of time. Obviously for an instance of time we don't need it recurring, so we will want to constrain the period attribute. Also, the period of time will need to be restricted to a single instance. To accomplish this, we will set the value for both the period and the duration to 0. However, both values are declared as timeDuration values and so must comply with the timeDuration lexical format. This means adding a "P" to the beginning (for period) and selecting one of the components of timeDuration (this can be Year, Month, Day, etc.). This will produce the following schema code:
<simpleType name=" timeInstant"> <restriction base=" recurringDuration"> <duration>P0Y</duration> <period>P0Y</period> </restriction> </simpleType>
-
A lexical format defines the possible representations for a given data type. For example, 64 and 2^6 are two lexical representations of the same value.
If you look at these derived data types, you may start to wonder what the difference is between these and the data types we were declaring earlier (firstName, sports). The answer is that there is really no difference. This only has value to the person declaring the type and how it will be used. This might do nothing more than add some context to an existing data type. With this realization, we can now consider every data type defined in our XML Schema on equal terms. This understanding is important to have as you define your data documents so that you can define the data elements you need and keep an eye toward reusability.
Keep in mind that we are only declaring data types, not actual elements that can be used in our XML data. What we have been doing is akin to declaring all of the types for variables in your code, but not the actual application variables. In the next section, we will start to tie elements to these data types so that they have meaning and relevance in our data.
Complex Types
We have already used the simple type element to generate derived data types. In the most basic terms, simple types define elements that have no child elements. They occur in an XML document only as the lowest node on their branch. Primitive or derived data types can define simple type elements. Complex type are elements much more robust than simple types because they can group multiple data types and incorporate attributes in their definitions. Complex types are necessary containers because elements cannot be defined as the children of other elements directly in schemas. Whenever you want to establish a parentchild relationship between elements, use the complex type syntactically to accomplish that. Figure 3-2 should help you visualize the relationship between the simple type and complex type elements and the primitive and derived data types that define them.
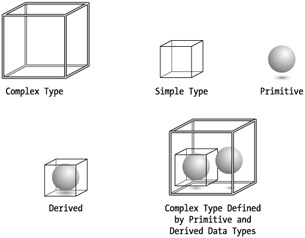
Figure 3-2: Schema data type relationships
As we saw earlier, we can already restrict other data types by creating simple types based on them and utilizing attribute constraints. Complex types can be used to restrict other complex data types in much the same way. However, the true power of complex data types comes from the ability to extend these data types by combining multiple types together. The complex type also allows you to tie attributes to elements. This is very similar to the programmatic concept of classes. Because of the number of permutations possible in this scenario, understanding the structure syntax for the complex type is very important.
First, let's take a look at the attributes available for defining the properties of our complex type elements. They are described briefly in Table 3-12.
| NAME | DESCRIPTION |
|---|---|
| id | namespace ID |
| final | permission to modify this type (#all|extension|restriction) |
| mixed | referring to the content model (true|false) |
| name | name of the type |
| UPDATE | The attributes of the complex type have gone through many changes since the XML Schema draft was first submitted. Many older publications on XML and schemas based on specifications previous to the October 2000 recommendation refer to a content attribute that no longer exists. The March 2001 recommendation replaced the mixed attribute with the content type attribute. |
The final attribute declares what others can do with this type. This was developed with an eye toward the future, when there might be mechanisms that could support this function. Compliance today would be strictly voluntary.
The mixed attribute helps to define the content model of the type. A content model defines what kind of content exists. Declaring this can help an application to efficiently parse a type to know what is valid and invalid with some efficiency. There are basically four types of content models in XML Schemas: empty, text only, element only, and mixed. Figure 3-3 illustrates the difference between these content models. With the mixed attribute set to false, the application knows it should encounter only one of the other content types. If the property is not explicitly stated, it is assumed to be false.
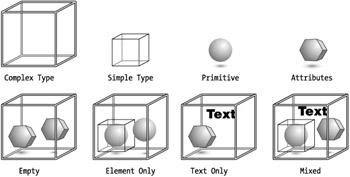
Figure 3-3: Complex type content models
Unfortunately, this system is not the simplest of designs to work with on a human level. The mixed property only marginally helps, because the content is also defined by the subelements declared in the type. The mixed property more or less sets the stage for what the application can expect, but your choice of elements and child elements really dictates the content model.
Before getting into the content model any further, you should learn about the child elements available in the complex type entity. They are described briefly in Table 3-13. We will discuss these throughout the rest of this section.
| NAME | DESCRIPTION |
|---|---|
| all | a list of required elements |
| annotation | any comments |
| attributeGroup | a collection of attributes declared externally |
| choice | a list of elements from which one may be selected |
| complexContent | a complex type entity |
| sequence | a list of ordered elements |
| simpleContent | a simple type entity |
| Note | The code I am providing for this section should not be considered complete schema code. I will merely be using sections of a schema document to identify specific portions without introducing too many new concepts at one time. All code, however, should be well-formed XML. |
Simple and Complex Content
To better understand these content models, we really need to first understand the simple and complex content elements. These are relative newcomers to the XML Schema specification, but are very important for working with complex type elements.
Think of the simple content and complex content elements as containers for the modification of existing types. A complex type can have either a simple content or a complex content, not both. Simple content simply defines elements of actual value. For instance, a complex type that extends the decimal type with a currency attribute utilizes a simple content container like this:
<complexType name=" money"> <simpleContent> <extension base=" decimal"> <attribute name=" currency" type=" string" /> </extension> </simpleContent> </complexType>
We see here a new element called extension. Whenever we use the simple and complex types, we are either extending or restricting an existing type or group of types. In fact, those are the only two child elements available to the simpleContent and complexContent elements (aside from annotation). However, the context of the two elements is very different when used in the simple and complex content containers. In fact, the specification would have been justified in creating separate elements under the simpleContent and complexContent entities just to minimize any confusion.
Both the extension and restriction entities support the base property, which declares which type is being manipulated. Under the simple content container, the restriction element supports a range of child elements. These elements comprise the set of attributes listed in Table 3-10 as well as simpleType. The goal is to provide all of the functionality necessary to detail the data validation required for a single element. The restriction and extension elements fully support all the attribute entities as well (attribute, attributeGroup, anyAttribute).
In the complexContent container, the restriction and extension elements can support entirely new model groups. I will discuss model groups in the next section, but suffice it for now to say that a model group can support a collection of elements. That means that a complex content element can support not only element information, but also an entirely new branch of elements and attributes. However, you may not always want to do this, and that is where content models come into play.
A complex type has four content models: empty, element only, text only, and mixed. Each of these models automatically supports attributes as well. Table 3-14 provides XML code examples of what each of these models looks like in implementation.
| MODEL | CODE |
|---|---|
| Empty | <customer/> |
| Element only |
<customer> <firstName>John</firstName> ... </customer> |
| Text only | <customer>John Doe</customer> |
| Mixed |
<customer>12345 <firstName>John</firstName> ... </customer> |
If you want to include only attributes in your complex type, then you are using the empty content model, and you need the complex content element. In this scenario, we will transition the money type from a simple content entity (which we just saw) to a complex content, as shown here:
<complexType name=" money"> <complexContent> <extension base= "anyType"> <attribute name=" value" type=" decimal"/> <attribute name=" currency" type=" string"/> </extension> </complexContent> </complexType>
As you can see, the only differences in the two code bases are the complexContent and simpleContent tags. So does it matter which method you use? Only if you ever want to change the definition of your money type. The complex content model is much more extensible in that making it a nonempty type is very simple. In the case of the simple content example, it has to be transferred to a complex content model to support growth going forward. If you don't believe you will ever need this extensibility, then stick with the simple content type.
To generate an element only type, we definitely need to use the complex content element. Remember, the simple content element can support only a single element, so a series of elements falls outside its scope. Let's take the same money type and turn it into an element only type, as shown here:
<complexType name=" money"> <complexContent> ... <element name=" value" type=" decimal" /> <element name=" currency" type=" string" /> ... </complexContent> </complexType>
I have masked out some additional tags to avoid confusion. We will be discussing them shortly. Also, keep in mind that we have not discussed the element entity yet, so don't worry if you don't understand the entire code segment. The main idea here is that more than one element can exist through the complex content container. Here is a shorthand version of this same definition that works because the content type is defaulted to complex content for a complex type:
<complexType name=" money"> ... <element name=" value" type=" decimal"/> <element name=" currency" type=" string" /> ... </complexType>
Finally, any combination of elements and text data in an element requires the mixed property value to be set to true. Thus this code represents a complex type in which the content model is mixed:
<element name=" storeSales"> <complexType> <complexContent mixed=" true"> <restriction base=" string"> ... <element name=" value" type=" decimal"/> <element name=" currency" type=" string"/> ... </restriction> </complexContent> </complexType> </element>
This code, when used in a schema document, defines an element called storeSales that has a string value and contains two child elements. Here is an example of mixed content in XML code:
<storeSales> MyStore <value>8450</value> <currency>US Dollars</currency> </storeSales>
Table 3-15 shows the four content models with the appropriate syntax and any shorthand versions. This is meant to be a quick reference for you once you start building complex types in your schemas.
| MODEL | SYNTAX | SHORTHAND |
|---|---|---|
| Empty |
<complexType mixed=" false"> <complexContent/> </complexType> |
<complexType/> |
| Text only |
<complexType mixed=" false"> <simpleContent> ... </simpleContent> </complexType> |
<complexType> <simpleContent> ... </simpleContent> </complexType> |
| Element only |
<complexType mixed=" false"> <element/> </complexType> |
<complexType> <element/> </complexType> |
| Mixed |
<complexType mixed=" true"> <complexContent> ... </complexContent> </complexType> |
<complexType> <complexContent> ... </complexContent> </complexType> |
Model Groups
Model groups are used to define groups of elements in a very customized manner. While they are somewhat related to groups by their nature, they are actually independent. All three models must be used exclusively of each other. That means that model groups are (for the most part) hierarchical and cannot be peers under any type. Also, while each supports the same attributes of minOccurs and maxOccurs, the range is restricted between 0 and 1 for each.
all
The all entity is used to declare a list of required elements that can be listed in any order. This group is slightly different in that it can only be used to define elements, no groups or sequences, as shown here:
<complexType name= "customer"> <all> <element name=" custID" type=" integer"/> <element name=" fName" type=" string"/> <element name=" lName" type=" string"/> </all> </complexType>
To get around the limitation of not being able to list all choices in an entity (something that you will likely want to do), you can choose a more verbose schema involving another layer of entities by embedding another complex type in an artificial element. Let's modify the preceding customer example by adding the choice of a home, work, or cellular telephone number, as shown here:
<complexType name= "customer"> <all> <element name=" custID" type=" integer"/> <element name=" fName" type=" string"/> <element name=" lName" type=" string"/> <element name=" contactNumber"> <complexType mixed=" true"> <choice> <element name=" home" type=" string"/> <element name=" work" type=" string"/> <element name=" cellular" type=" string"/> </choice> </complexType> </element> </all> </complexType> sequence
The sequence element lets you dictate the order of a list of entities. Like the choice element we will look at next, its child elements can comprise elements, groups, choices, and other sequences, so a wide variety of permutations are available. Sequences are very necessary to writing complex schemas because the all element cannot contain a choice element. However, I do not advise using unnecessary sequences. Among XML's positive qualities are its open nature and structure and its defining sequences. We have these sets of defined tags that have relationships, but dictating the order of tags among peers decreases the extensibility of the language. Some might argue that less work would go into writing applications if XML data were sequenced, but I believe there will always be exceptions to account for that will require the same flexibility from our applications. In other words, as soon as you write an application that depends on sequenced data, an alternative data set will come up from a new scenario that requires changes to the application. I think it is far better to design for the worstcase scenario so you aren't surprised later.
Regardless, the mechanism is necessary, so here is a sample:
<complexType name=" customer"> <sequence> <element name=" custID" type=" integer"/> <element name=" fName" type=" string"/> <element name=" lName" type=" string"/> </sequence> </complexType>
This then makes the following XML data invalid:
<customer> <custID>123456</custID> <lName>Smith</lName> <fName>John</fName> </customer> choice
As its name implies, the choice element is used to allow the selection of one instance from all possible child elements. Its child elements can comprise elements, groups, sequences, and even other choices so the compound nature can provide various declarations, as shown here:
<complexType name=" order"> <sequence> <element name=" shipMethod" type=" shipOption"/> <choice> <element ref=" workAddress" type=" address"/> <element name=" homeAddress" type=" address"/> </choice> </sequence> </complexType>
With some of these examples, we have in fact ventured past data types into some of the structures behind schemas. The two components obviously go hand in hand to build our schemas. So now that we've covered the highlights of data types, let's jump to structures so that we can start bringing closure to this definition language.
Using Data Types
The major topics we have discussed until now have focused on data types. They provide everything we need to define anything we might need for our XML data. However, we now have to utilize these data types by grouping them, extending and restricting them, and associating them with the elements for our documents. To do this, we need to round out our understanding of the various entities available.
Schema Namespace
We have already touched on the schema element, since it is the root node of any schema. A schema should be treated like the container for our definitions, and this container can only accept certain entities directly. These entities are simpleType, complexType, element, attribute, attributeGroup, group, notation, and annotation.
The significant aspect of the schema element is the namespace it represents. Any application that actually validates schemas will need the reference to this model through the namespace referenced when the schema element is declared.
| Note | I purposely left out all references to the schema namespace in the data type section so that we could focus on the actual topics at hand. From this point forward, all samples will correctly reference the schema namespace so that our code is compliant with the specification. |
When the schema element is declared, a simple reference to the namespace makes your schema compliant. Thus, instead of just this declaration of the schema:
<schema> </schema>
our declaration should now look like this:
<xsd:schema xmlns:xsd=" http://www.w3.org/2000/10/XMLSchema"> </xsd:schema>
When utilizing the namespace throughout a schema, our schemas will look more like this:
<xsd:schema xmlns:xsd=" http://www.w3.org/2000/10/XMLSchema"> <xsd:element name=" letterBody"> <xsd:complexType name= "customer"> <xsd:all> <xsd:element name=" custID" type=" xsd:integer"/> <xsd:element name=" fName" type=" xsd:string"/> <xsd:element name=" lName" type=" xsd:string"/> <xsd:element name=" contactNumber"> <xsd:complexType mixed=" true"> <xsd:choice> <xsd:element name=" home" type=" xsd:string"/> <xsd:element name=" work" type=" xsd:string"/> <xsd:element name=" cellular" type=" xsd:string"/> </xsd:choice> </xsd:complexType> </xsd:element> </xsd:all> </xsd:complexType> </xsd:element> </xsd:schema>
Notice that even our base types reflect the namespace. This is because all of our primitive and derived data types are actually defined by the XML Schema namespace we discussed previously.
Element Declarations
Elements are the entities behind every node in our XML documents. It can be somewhat confusing when referring to the element entity because of its omnipresent use in XML Schemas. In this instance I am referring to the elements we are defining in our XML data sets.
For example, to define the movie-listing document we saw earlier, we must define the movie, actor, and director elements. As mentioned earlier, XML elements can build upon each other, and we need to think of these elements as extensions of existing elements, be they numeric, string, or some other type. We need to focus on the elements we need to define and not get bogged down in the semantics of element definition.
Elements come with many properties we can use to declare our data types. (See Table 3-16.) The most significant attribute of the element is type. Elements are always based on some type, and this is how we associate the two. In some earlier samples we used elements to build our complex types. Here is another look at our money type:
<xsd:complexType name=" money"> <xsd:sequence> <xsd:element name=" value" type=" xsd:decimal"/> <xsd:element name=" currency" type=" xsd:string"/> </xsd:sequence> </xsd:complexType>
| NAME | DESCRIPTION |
|---|---|
| default | the default value, if any, for the element |
| fixed | the fixed value, if any, for the element |
| id | the namespace reference |
| maxOccurs | the maximum number of times this element can occur in this element |
| minOccurs | the minimum number of times this element can occur in this element |
| name | the name of the element |
| nullable | whether the element is nullable (true|false) |
| type | the base type of the element |
| Note | The schema container and namespace declaration are implied in any code samples referencing the xsd namespace. |
Money contains two elements named value and currency. Each one has a type with value typed as decimal and currency typed as string. These are both derived data types that the elements are using for their data type. This is similar to declaring variables in a programming language. What we see here is a declarative typing through the type attribute of the element entity. Another method for declaring element data types is in-line casting. Enclosing a simple or complex type between an element's start and end tags does this. These two methods should be used exclusively of each other in one element. Such an implementation for our value element looks like this:
<xsd:element name=" value"> <xsd:simpleType> <xsd:restriction base=" xsd:decimal"/> </xsd:simpleType> </xsd:element>
There are different scenarios in which each would be appropriate, so this isn't a "one size fits all" situation.
The minOccurs and maxOccurs attributes would also have frequent use in a "tight" schema definition of our data. Through these properties, we can explicitly declare the existence and frequency of our elements. This ability can be invaluable for declaring a sequence of elements or simply making an element required in a structure. For the first scenario, let's declare a structure for an NHL hockey team. (See the hockeyTeam element schema that follows.) According to the rules, a team must dress two goaltenders and 18 players. These players can be of any position, but any coach will tell you to have a minimum of five defensemen and 10 forwards. That leaves the maximum number of defensemen at eight and forwards 13, as shown here:
<xsd:simpleType name=" player"> <xsd:restriction base=" xsd:string"/> </xsd:simpleType> <xsd:complexType name=" hockeyTeam"> <xsd:sequence> <xsd:element name=" goalies" type=" player" minOccurs="2" maxOccurs="2"/> <xsd:element name=" forwards" type=" player" minOccurs="10" maxOccurs="13"/> <xsd:element name=" defenseman" type=" player" minOccurs="5" maxOccurs="8"/> </xsd:sequence> </xsd:complexType>
What we just did as a quick exercise was define a player type and then declare elements using the player data type. The string represents the name of the player. Of course, this schema doesn't address the overall number of players. Using this definition, we could mistakenly field a team of only 15 skaters or find the loophole in the application and dress 21 skaters. The only problem there is fitting them all on the bench!
How do we address this problem? Well, we have to redesign our definition at a lower level to keep this from happening. Instead of defining a type of player and declaring the elements as positions, why don't we define goalies and skaters based on players? That would look like this:
<xsd:simpleType name=" player"> <xsd:restriction base=" xsd:string"/> </xsd:simpleType> <xsd:simpleType name=" goalie"> <xsd:restriction base=" player"/> </xsd:simpleType> <xsd:complexType name=" skater"> <xsd:choice> <xsd:element name=" forward" type=" player"/> <xsd:element name=" defenseman" type=" player"/> </xsd:choice> </xsd:complexType> <xsd:complexType name=" hockeyTeam"> <xsd:sequence> <xsd:element name=" dressedGoalies" type=" goalie" minOccurs="2" maxOccurs="2"/> <xsd:element name=" dressedSkaters" type=" skater" minOccurs="18" maxOccurs="18"/> </xsd:sequence> </xsd:complexType>
Of course the tradeoff with this implementation is that I could make a mistake and have 18 forwards or 18 defensemen. While this is bad, it at least isn't illegal. Given the two options, this schema definitely is better and is a good example of the kinds of decisions we have to make when trying to design schemas for our business data.
We have now covered enough material to start making complete schemas. The most basic schemas simply define a single element based on a primitive data type. The following code is an example:
<xsd:schema xmlns:xsd=" http://www.w3.org/2000/10/XMLSchema"> <xsd:element name=" name" type=" xsd:string"/> </xsd:schema>
Most of the code samples in this section are valid schemas with a schema container like this. However, to have much richer and well defined, reusable definitions, we will likely build much more involved schemas. These will inevitably involve the simple and complex types we saw earlier, as well as groups and attribute groups.
Group Declarations
Groups are used to define collections of entities as a whole unit locally and easily reference them elsewhere in your schema. This is different from defining complex types because they are much less robust. The only child elements available to a group element are the all, choice, and sequence elements discussed previously.
The group is referenced through the name attribute of the group declaration. Groups then use the ref attribute to reference the group declaration in a document. As an example, let's revisit the order schema used earlier. This time we will modify the order element from our choice model group example by declaring a group for our home and work addresses and selecting the choice from the group, as shown here:
<xsd:complexType name= "order"> <xsd:sequence> ... <xsd:element name=" shipMethod" type= "shipOption"/> <xsd:group ref=" addressOption"/> </xsd:sequence> </xsd:complexType> <xsd:group name=" addressOption"> <xsd:choice> <xsd:element name=" homeAddress" type=" address"/> <xsd:element name=" workAddress" type=" address"/> </xsd:choice> </xsd:group>
You can see how this would be handy if we were going to work with these address elements frequently. This grouping not only makes it easier to work with the elements as a whole, but also conserves space in the schema. Additionally, this addressOption element is more maintainable since a change only needs to be added to one schema and persists throughout the referencing schemas.
Attribute Group Declarations
Attribute groups behave much the same way that groups do. With them, you can group a list of attributes together and reference them anywhere in the schema. For our scenario, let's look again at the shipOption element from our order type. We will flush out some of the details of our shipping options, as shown here:
<xsd:attributeGroup name=" shippingProperties"> <xsd:attribute name=" priority"> <xsd:simpleType> <xsd:restriction base=" xsd:string"> <xsd:enumeration value=" overnight"/> <xsd:enumeration value="2-day"/> <xsd:enumeration value=" ground"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name=" cost" type=" money"/> </xsd:attributeGroup> <xsd:element name=" shipMethod"> <xsd:complexType> <xsd:sequence> <xsd:element name=" deliveryMethod" type=" shipOption"/> </xsd:sequence> <xsd:attributeGroup ref=" shippingProperties"/> </xsd:complexType> </xsd:element>
Perhaps even more so than with the group element, you can tell that aggregating frequently used attributes together can really lead to more efficient reuse of your schema data. In this example, we also utilized the restriction element as opposed to the extension element to show its use in attributes. You might have to modify your schema's structure slightly to accommodate an attribute-heavy structure.
Implementation
Now that we have looked at the syntax of building schemas, how do we use them? There are basically two aspects of using schemas. The first one, the usage of schemas by your XML data, is obvious. The second, the reuse of schemas, is probably less obvious, but nearly as important. After all, if we can't reuse schemas or their components, that dramatically affects the effort we invest and our usage of them.
Using Schemas
Now that we know how to build schemas, how do we actually use them? We want to be able to reference a schema from within an XML document. The SchemaLocation property, which has two different forms, makes this possible. The first form, named SchemaLocation, is used to identify schemas where a target namespace has been identified. For those who do not use namespaces, the noNamespaceSchemaLocation form is available. This difference is merely to point out to an application the namespace state of the data in the document.
A simple reference to a schema for our customer node looks like this:
<customer xmlns:xsi=" http://www.w3.org/2000/10/XMLSchema-instance" xsi:SchemaLocation=" C:\test.xsd">
In the latter case, in which no namespace is declared, the call looks much the same, as shown here:
<customer xmlns:xsi=" http://www.w3.org/2000/10/XMLSchema-instance" xsi:noNamespaceSchemaLocation=" C:\test.xsd">
Reusing Schemas
When we have invested time and effort in defining data types and structures, we would like to be able to reuse them in multiple schemas. Without this reusability, we certainly could question the effort we put into designing our structures and schemas.
To include schemas that share the same target namespace as the local schema, we simply declare an include element and identify the location of the schema through the schemaLocation attribute, as shown here:
<xsd:include schemaLocation=" http://myDomain.com/schemas/customer.xsd"/>
Of course this begs the question how to handle schemas that do not share the local targetNamespace. For such schemas you need to use the import entity. The syntax is virtually identical to that for the include tag, as shown here:
<xsd:import schemaLocation=" http://myDomain.com/schemas/customer.xsd"/>
To take this one step further and modify the schemas when we reference them, we simply exchange the include element for the redefine element, as shown here:
<xsd:redefine schemaLocation=" http://myDomain.com/schemas/customer.xsd">
With this simple change, we now have the ability to either extend or further enhance all of the data types and structures included in the schema. The syntax for these modifications is the same as that for modifying structures defined locally. So if we extend our customer structure defined externally, we use the redefine element, as shown here:
<xsd:schema xmlns:xsd=" http://www.w3.org/2000/10/XMLSchema"> <xsd:redefine schemaLocation=" http://myDomain.com/schemas/customer.xsd"> <xsd:complexType name=" customer"> <xsd:complexContent> <xsd:extension base=" customer"> <xsd:sequence> <xsd:element name=" email" type=" xsd:string"/> </xsd:sequence> </xsd:extension> </xsd:complexContent> </xsd:complexType> </xsd:redefine> </xsd:schema>
It should seem evident that there are a number of ways to define the same elements. We have talked about some of the tradeoffs and benefits, but those were on the element level. The prospect of instead designing schemas for an entire organization could seem quite overwhelming. Some of the decisions you make early on will dictate how the process is defined. Before making those decisions, it's a good idea to develop a schema strategy.
Schema Strategy
It might seem like overkill, but it makes a lot of sense to outline a strategy for your organization to implement and develop schemas. If all employees use their own methods during design and implementation, your organization will probably be unable to benefit from schema reuse. By taking just a little time to document a schema structure for your organization, you could benefit from reuse for years to come.
A schema strategy should address the following components:
-
Selecting development tools
-
Identifying your XML repositories
-
Defining the design rules
-
Establishing a schema hierarchy
-
Utilizing namespaces
First you should standardize on the tools your developers will use when creating schemas (and other XML documents, for that matter). Even compliant tools can produce very subtle differences or nuances in the code that may keep it from working as well with other tools. Standardizing on a tool should help you to avoid any such issues.
The next step is to identify a repository for your schemas. There are several options here, but the main thing is that developers can access existing schemas for maintenance and quickly reference other existing schemas during development.
This decision depends on what form you will keep your data in and your performance and scalability requirements. For example, you could keep your schema data in physical files and organize them through a file structure, but your scalability and performance will then be somewhat limited. Conversely, you could have all of your data maintained in a relational database and extract the data as XML. This would help your scalability, but hurt the overall performance.
After establishing the infrastructure, you should lay down some ground rules for schema design in your organization. This involves defining some best practices and coding standards. You could spend forever doing this, but I recommend just hitting some high points and making sure that the first schemas in the organization go through a review process to surface more specific issues.
The next step is to design a schema hierarchy. This means deciding how schemas will align with documents, how these documents will relate to each other, and the data structures within them. In a small organization, you can get away with being rather ad hoc about this. However, larger organizations will suffer greatly if a standard hierarchy map is not created before schemas are assembled.
Schemas should break down rather neatly into at least a three-layer document structure. Base-level documents should contain all data types, including all derived and simple types. The next level of documents could then define all structures using these data types. Finally, the top-level schema documents could actually define your XML documents using the structures. This structure (see Figure 3-4) will provide many benefits if implemented correctly. First, it allows direct application access to only the highest layer, thereby protecting the integrity of your structures and data types. Second, when a data type or structure is needed, the existing repository can be quickly searched for building blocks to assemble it, and once it is done, it is easily found by others. Finally, this structure also allows for easier organization of your namespaces by grouping schemas together naturally.
Figure 3-4: Three-tier schema hierarchy design
Let's walk through a hierarchical design using our movie sample. In this document, we had a movie element that contained title, actor, and director elements. The actor then had character and name child elements, and the director a name element. Let's go ahead and enhance that by including the genre(s) and the year of its release, as shown here:
<movie> <title>Forrest Gump</title> <year>1994</year> <actor> <character>Forrest Gump</character> <name>Tom Hanks</name> </actor> <director> <name>Robert Zemeckis</name> </director> <genre>Drama</genre> <genre>Comedy</genre> </movie>
The first thing to do is identify all of the data types we will need. Looking at this scenario, it looks like we will need title, year, character, name, and genre data types. Those all go into our level-one document, as shown here:
<xsd:schema xmlns:xsd=" http://www.w3.org/2000/10/XMLSchema"> <xsd:element name=" character" type=" xsd:string"/> <xsd:element name=" name" type=" xsd:string"/> <xsd:element name=" title" type=" xsd:string"/> <xsd:element name=" year" type=" xsd:short"/> <xsd:element name=" genre"> <xsd:simpleType> <xsd:restriction base=" xsd:string"> <xsd:enumeration value=" Comedy"/> <xsd:enumeration value=" Drama"/> <xsd:enumeration value=" Adventure"/> <xsd:enumeration value=" Documentary"/> </xsd:restriction> </xsd:simpleType> </xsd:element> </xsd:schema>
With our elements defined, we now need to make our structures. The data type identification is fairly straightforward. However, identifying structures is a different matter, so this is likely where your difficult design decisions will be made. The element that could be in question for this particular design is movie. If it is the document's root element, then we should declare it in our level-three schema, correct? The best way to resolve this issue is to ask the following question: Will someone else ever reuse this element? If the answer is yes, then I encourage you to leave it in your level-two schema. In this scenario, it makes our level-three schema rather insignificant, so I'm going to arbitrarily state that our root node will not be <movie>, but rather <movieCollection>. This gives us the flexibility to include multiple movies if necessary and allows us to treat the movie element as a structure with a clear conscience! Here is the code:
<xsd:schema xmlns:xsd=" http://www.w3.org/2000/10/XMLSchema"> <xsd:include schemaLocation=" C:\movietypes.xsd"/> <xsd:complexType name=" actorType"> <xsd:sequence> <xsd:element ref=" character"/> <xsd:element ref=" name"/> </xsd:sequence> </xsd:complexType> <xsd:complexType name=" directorType"> <xsd:sequence> <xsd:element ref=" name"/> </xsd:sequence> </xsd:complexType> <xsd:complexType name=" movieType"> <xsd:sequence> <xsd:element ref=" title"/> <xsd:element ref=" year"/> <xsd:element name=" actor" type=" actorType"/> <xsd:element name=" director" type=" directorType"/> <xsd:element ref=" genre" maxOccurs=" unbounded"/> </xsd:sequence> </xsd:complexType> </xsd:schema>
Finally, we get to our level-three schema, which should simply aggregate structures and/or data types together to form the definition for our document. In our case, we will simply be utilizing the movie structure, as shown here:
<xsd:schema xmlns:xsd=" http://www.w3.org/2000/10/XMLSchema"> <xsd:include schemaLocation=" C:\moviestructures.xsd"/> <xsd:element name=" movieCollection"> <xsd:complexType> <xsd:sequence> <xsd:element name=" movie" type=" movieType" maxOccurs=" unbounded"/> </xsd:sequence> </xsd:complexType> </xsd:element> </xsd:schema>
So there is our three-tier schema definition for our movie collection document. You will probably encounter situations in which you cannot strictly adhere to a schema strategy model, but the more you can do that, the more consistent and efficient your schemas will be.
That brings us to the final strategy topic, which concerns the use of name-spaces by large organizations. Namespaces were designed to easily identify and protect XML data. Many organizations allow their departments to create their own systems and services. Your organization needs a plan concerning how name-spaces are created and propagated if it is to be as effective as possible at utilizing XML. The larger a consensus you can have on individual namespaces, the more cooperative the areas of your organization will be in developing solutions.
|
|
EAN: 2147483647
Pages: 77