Binding to the Persistence Abstraction
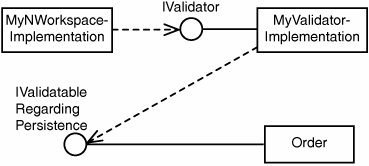
| In the previous chapter, I talked about how to prepare for the persistence infrastructure by working with an abstraction layer that I called NWorkspace (which is just an example of such an abstraction of course). As you might have guessed, it has some support for validation as well, because the reactive nature needs to be dealt with when we make calls to PersistAll(). Of course, I don't want the persistence abstraction to expect a certain interface to be implemented on the Aggregate roots. Make the Validation Interface PluggableTherefore, I made it possible to inject an IValidator to the IWorkspace. The IValidator interface looks like this: public interface IValidator { bool IsValidatable(object entity); bool IsValid(object entity); IList BrokenRules(object entity); }The IWorkspace implementation talks to the IValidator implementation, and the IValidator implementation then decides what interfaces to look for on the entities. In my case, the IValidator implementation looks for IValidatableRegardingPersistence implementations and knows what to do with the IValidatableRegardingPersistence implementation in order to throw an exception during PersistAll(), if necessary. To make this a bit more concrete, see Figure 7-3. Figure 7-3. Overview of the collaborating pieces Just as with the database itself, the IValidator is reactive, but it reacts at a step earlier than the database and it often reacts on slightly more complex and domain focused rules. To make testing easier, I also have an implementation of IValidator that is called ValidatorThatDoesNothing. I mean for it to be used for unit tests when you don't want to have the validation to interfere. Then you inject ValidatorThatDoesNothing to the IWorkspace implementation instead of the one looking for IValidatableRegardingPersistence instances. It took 30 seconds to write, and I think that's a decent investment compared to how useful it is. Alternative Solution for Approaching the Reactive Validation on SaveAs I have touched on earlier, there are problems for certain O/R Mappers regarding what you can do at the validation spot in the persist pipeline. Therefore, it might be interesting to think about what you can do to deal with that. In my implementation, I prefer to check the rules in real-time; that is, when someone wants to know. As I've mentioned, I like the idea of using Services for dealing with problems related to what can't be done at the validation spot. One alternative solution is to update the list of broken rules after each change to a property so that it is pre-calculated when it is needed. Depending on your call patterns, it could either be more or less efficient than my way of doing it. Note Gregory Young pointed out that with the metadata on the rules mentioned earlier (what fields affect what rules), one can be very efficient about rechecking rules and always having current validation. A problem is that it requires some help with dirty tracking, or you will have to write loads of code yourself in your setters (unless you apply AOP for dealing with the crosscutting concern of course). You will also have to use properties instead of public fields, even if public fields would otherwise do very well. Note This style is used in the CSLA.NET-framework [Lhotka BO], which also has support for something I haven't touched upon: multi-step undo. Another solution is to hold on to a flag called IsValidated that is set to true each time you reproduce the list of broken rules and set to false after each change. At the validation spot for the persist-pipeline, you expect the IsValidated to be true, or you throw an exception. That affects the programming model slightly because it makes the IsValidRegardingPersistence call or BrokenRulesRegardingPersistence call mandatory. The other drawback (if you consider the mandatory call a drawback, and I think I do) is that you have similar problems with the dirty tracking as I just mentioned. Anyway, it's good to have a couple of different approaches prepared in case you find problems with your first choice. Reuse Mapping MetadataThere's one more idea I need to get out of my system before moving on. I have already said that I like the principle of defining once but executing where most appropriate (such as in the UI, the Domain Model, or the database). This idea is very much in line with that. If you find that you put a lot of energy into defining loads of simple rules by hand, such as maximum string lengths, you should consider setting up those rules dynamically instead by reading metadata somewhere. For example, you have the information in the database, but using that might be a bit troublesome depending on your mapping solution. An alternative might be the metadata mapping data itself. Perhaps you'll find the source for several rules there. Anyway, the important part of the idea is to read the data from somewhere when you start up the application, set up the rules dynamically, and then you are done. Of course, as with all the other ideas in this chapter, this isn't the answer to every problem. It is just one more tool for solving the big puzzle. |
EAN: 2147483647
Pages: 179