3.4 Set-Top-Box SOC
3.4 Set-Top-Box SOC
In Chapter 1, we showed an example of a set-top-box SOC. The block diagram for this SOC is repeated here in Figure 3.5.
Figure 3.5. A Set-Top-Box SOC
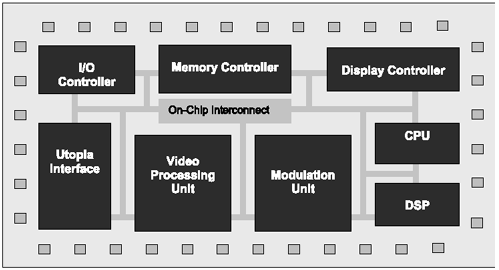
In this SOC, typical traffic flow for cable applications is as follows :
-
From video-processing unit to memory controller
-
From memory controller to video-processing unit
-
From I/O controller to memory controller
-
From memory controller to display controller
For satellite applications, the traffic flow changes to:
-
From Utopia interface to video-processing unit
-
From video-processing unit to memory controller
-
From memory controller to display controller
All of the above traffic goes through the on-chip interconnect. The following example covers a detailed STB SOC with Sonics SiliconBackPlane as the on-chip interconnect.
| |
| |
| Top |
EAN: 2147483647
Pages: 61