19.5. Improving Server Availability with Memory Technologies
| < Day Day Up > |
| Chapter 3 explained key memory concepts along with technologies used to detect and correct memory errors. This subsection explains methods and technologies relating to memory that can be used to improve server availability, including the following:
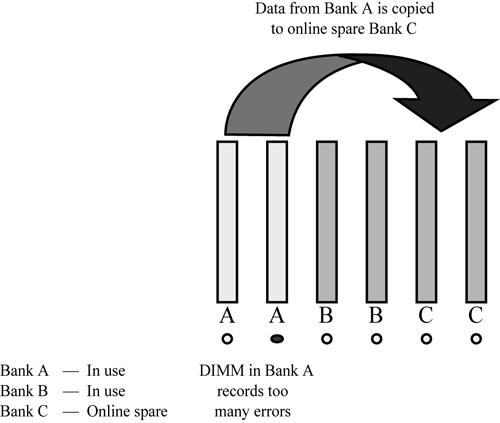
19.5.1 Online Spare MemoryOnline spare memory technology enables a ProLiant server to remain available even if a DIMM records an excessive number of single-bit errors. Online spare memory increases availability by enabling an administrator to wait until a scheduled downtime to replace a faulty DIMM. Online spare memory provides a spare memory bank for systems that detect excessive single-bit errors. When a memory bank with a faulty DIMM is detected, it automatically fails over to (is replaced by) a spare bank of DIMMs, as shown in Figure 19-1. Figure 19-1. Online spare memory.
In earlier-generation servers and in servers without online spare memory, when a memory module experiences an excessive number of correctable single-bit errors, the system issues a prefailure warning and the DIMM continues to function in its degraded state. If this occurs, the recommended procedure is to power-off the server as soon as possible, replace the faulty DIMM, and restart the system. With online spare memory, a memory bank with a faulty DIMM automatically fails over to a spare bank of DIMMs. One pair of DIMMs functions as the spare bank. Up to two other memory banks can be installed in the other slots. When the faulty DIMM reaches a predefined single-bit error threshold, the ROM starts copying the contents of the failing bank to the spare bank in 128KB increments. During this time, the failing bank provides all read accesses. Data is written to both banks during the copy process. Note Because the spare bank must be able to hold all the information from a failing bank, the DIMMs in the spare bank must be the same size as, or larger than, the other banks. After memory copying is complete, the system ROM makes the switch to the spare bank. At that point, no more reads or writes are made to the failing bank. All reads and writes are made to the spare bank. During a scheduled shutdown, the faulty DIMM is replaced with a functioning DIMM. When the server restarts, the memory banks resume their normal functions. The advantage of online spare memory is that the shutdown to replace the failing DIMM can be scheduled for a time when there is little activity on the server. When the server restarts, the memory banks resume their normal functions. 19.5.1.1 SPECIAL REQUIREMENTSOnline spare memory has the following requirements:
Note You can find the complete special memory requirements in the user guide that shipped with the server. 19.5.1.2 CONFIGURING ONLINE SPARESBefore you configure an online spare, HP recommends that you perform the following steps to test the new memory:
After the memory has been tested, power-down the system and verify that bank C is populated with memory no smaller than either bank A or B. To configure the online spare, follow these steps:
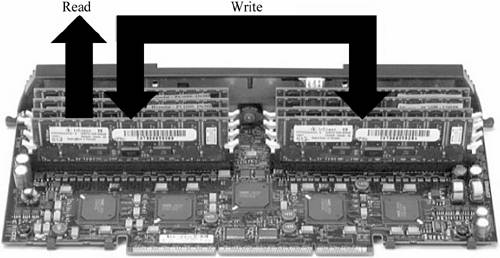
Note If the memory size requirements for proper operation are not met, RBSU will not allow you to enable online spare memory and will display this message: Caution: Current memory configuration does not support Online Spare. 19.5.2 Single-Board Mirrored MemorySingle-board mirrored memory provides a higher level of availability than online spare memory by adding protection against multibit errors using a mirrored memory bank. When a failure occurs, the system rereads the correct data from the mirrored bank. The system performs all future reads from the mirrored memory bank until the server can be shut down and the memory replaced. Single-board mirrored memory in ProLiant servers protects against multiple noncorrectable multibit errors without degrading the performance of the memory system. A single memory board contains two memory banks. One of the banks is designated as the primary bank and the other as the mirror. Data sent to memory is written by the memory controller to both banks simultaneously, but the system reads from the primary bank only, as illustrated in Figure 19-2. Figure 19-2. How single-board mirrored memory works.
During a read operation, if a multibit error is detected on one or more DIMMs in the primary bank, the system reads from the mirrored bank instead. This process occurs without service intervention or server interruption. Service personnel can replace the failed DIMM during a regularly scheduled shutdown. Note Mirroring protects against multibit errors so long as system and mirrored DIMMs do not fail in the same cache line at the same time (a highly unlikely event). All read and write operations in a mirrored memory configuration are handled by the memory controller. Although data is always written to both banks in the mirrored pair, data is read only from the primary bank. To ensure that all DIMMs are functioning properly, every 24 hours the system switches the primary and mirror designations and begins reading from the other bank. 19.5.2.1 SPECIAL REQUIREMENTSThe requirements for mirrored memory are as follows:
When implementing mirrored memory, follow these steps:
19.5.3 Hot-Plug Mirrored MemoryHot-plug mirrored memory provides a higher level of availability than online spare memory by adding protection against multibit errors. When a failure occurs, the system rereads the correct data from the mirrored bank on the other memory board. The system performs all future reads from the other memory board until the failed bank can be hot-plug replaced without shutting down the server, as shown in Figure 19-3. Figure 19-3. How hot-plug mirrored memory works.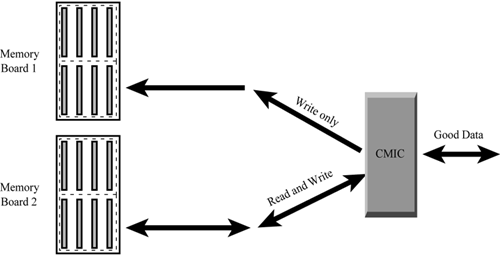 Hot-plug mirrored memory is targeted to customers who cannot afford to take a server offline to replace a failing DIMM. Hot-plug mirrored memory works like single-board mirrored memory. The difference is that the primary banks and mirrored banks are located on different memory boards. To use hot-plug mirrored memory, a server must have two identical memory boards, each containing several banks of DIMMs. The memory controller writes the same data to identically configured banks of DIMMs on both memory boards. The memory controller reads data from only one group. If any bank of DIMMs has a multibit error, the system performs the following actions:
If no errors occur, the system periodically switches which set of banks it reads from to ensure that both sets are monitored for memory errors. ! Important If a DIMM exceeds the limit defined by HP for single-bit correctable errors, the system will not fail over to the redundant banks, but will notify you of the condition through Insight Manager 7. Hot-plug mirrored memory also provides hot-plug replacement capability. You do not have to wait for a scheduled shutdown to replace the failed DIMM. You can remove a memory board that has a failed or degraded bank on it without shutting down the server. After replacing the bank of DIMMs, you can reinstall the memory board when the server is still running. After the board is reinstalled, the system automatically returns to mirrored status. You can also perform a non-hot-plug replacement of failed or degraded DIMMs during a scheduled shutdown. Note The special requirements described in the "Single-Board Mirrored Memory" section also apply to hot-plug mirrored memory. Hot-plug mirrored memory offers two main advantages over single-board mirrored memory. First, you can mirror more than one bank of DIMMs. Second, no server downtime is necessary to replace a defective DIMM or bank. 19.5.4 Hot Plug RAID MemoryHot Plug RAID Memory enables a memory subsystem to withstand a complete DIMM failure and continue to operate normally in a manner similar to hot-pluggable hard drives in a RAID 4 configuration. The system corrects future reads from parity information until the failed DIMM can be hot-plug replaced without shutting down or restarting the server. Originally, the term RAID was used to describe a fault-tolerant hard disk drive technology. The same RAID theory can be applied to DIMMs. HP calls this Hot Plug RAID Memory. Hot Plug RAID Memory allows memory to be added, replaced, and upgraded without shutting down or even restarting the server. Servers with Hot Plug RAID Memory use five memory controllers to control five SDRAM DIMMs. The memory controllers are part of a next-generation chipset designed by HP. Each one is an application-specific integrated circuit (ASIC). To write data to memory, a cache line of data is split into four blocks and distributed among the controllers. Four of the memory controllers write one block of data on their associated DIMMs. A RAID engine calculates parity information, and the fifth memory controller stores the parity information on the fifth DIMM. RAID memory takes memory protection and correction beyond the capabilities of ECC. With RAID memory, multibit errors and full DRAM failure can be corrected. Errors in the ECC detection system can also be detected, but not corrected. Although a failure of the ECC detection system can allow memory corruption and ultimately a system failure, it might not cause problems in the system if there are no memory errors to detect or correct. The RAID memory system in the ProLiant 700 series servers allows for the detection of a failure of the ECC system, which can be corrected by replacing a memory cartridge. | ||
| < Day Day Up > |
EAN: 2147483647
Pages: 278