Procedural Versus OO Programming
| < Day Day Up > |
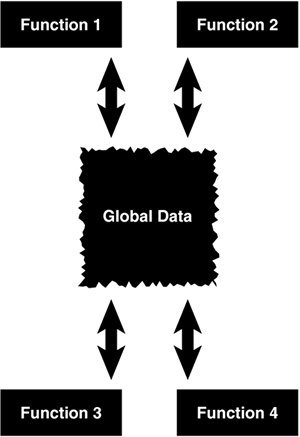
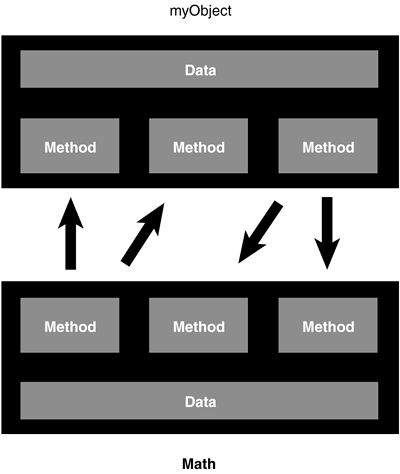
| Before we delve deeper into the advantages of OO development, let's consider a more fundamental question: What exactly is an object? This is both a complex and a simple question. It is complex because shifting gears to learn a totally new way of thinking is not an easy task. It is simple in the sense that most people already think in terms of objects. For example, when you look at a person, you see the person as an object. And an object is defined by two terms: attributes and behaviors. A person has attributes, such as eye color , age, height, and so on. A person also has behaviors, such as walking, talking, breathing , and so on. In its basic definition, an object is an entity that contains both data and behavior. The word both is the key difference between the more traditional programming methodology, procedural programming, and OO programming. In procedural programming, code is placed into totally distinct functions or procedures. Ideally, as shown in Figure 1.1, these procedures then become "black boxes," where inputs go in and outputs come out. Data is placed into separate structures, and is manipulated by these functions or procedures. Figure 1.1. Black boxes. Difference Between OO and Procedural This is the key difference between OO and procedural programming. In OO design, the attributes and behavior are contained within a single object, whereas in procedural, or structured design, the attributes and behavior are normally separated. Procedural programming has been the mainstay since the Bronze Age of computers ”so why change? First, as illustrated in Figure 1.2, in procedural programming the data is separated from the procedures, and sometimes the data is global, so it is easy to modify data that is outside your scope. This means that access to data is uncontrolled and unpredictable (that is, several functions may have access to the global data). Second, because you have no control over who has access to the data, testing and debugging are much more difficult. Objects address these problems by combining data and behavior into a nice, complete package. Figure 1.2. Using global data. Proper Design We can state that, when properly designed, there is no such thing as global data in an OO model. This fact provides a high amount of data integrity in OO systems. Objects are much more than primitive data types, such as integers and strings. Although objects do contain entities such as integers and strings, which represent the attributes, they also contain methods, which represent the behaviors. In an object, you use the methods to operate on the data. Perhaps more importantly, you can control access to members of an object (both attributes and methods). This means that some members , such as data types and methods, can be hidden from other objects. For instance, an object called Math might contain two integers, called myInt1 and myInt2 . Most likely, the Math object also contains the necessary methods to set and retrieve the values of myInt1 and myInt2 . It might also contain a method called Sum() to add the two integers together. Data Hiding In OO terminology, data is referred to as attributes, and functions are referred to as methods. Restricting access to certain attributes and/or methods is called data hiding . By combining the data and methods in the same entity, which in OO parlance is called encapsulation , we can control access to the data in the Math object. By defining these integers as off-limits, another logically unconnected function cannot manipulate the integers myInt1 and myInt2 ”only the Math object can do that. Sound Class Design Guidelines Keep in mind that it is possible to create poorly designed classes that do not restrict access to class attributes. The bottom line is that you can design bad code just as efficiently with OO design as with any other programming methodology. Simply take care to adhere to sound class design guidelines (see Chapter 5, "Class Design Guidelines," for class design guidelines). What happens when another object ”for example, myObject ”wants to gain access to the sum of myInt1 and myInt2 ? It asks the Math object: myObject sends a message to the Math object. Figure 1.3 shows how the two objects communicate with each other via their methods. The message is really a call to the Math object's Sum method. The Sum method then returns the value to myObject . The beauty of this is that myObject does not need to know how the sum is calculated (although I'm sure it can guess). In this example, you can change how the Math object calculates the sum without making a change to myObject (as long as the means to retrieve the sum do not change). All you want is the sum ”you don't care how it is calculated. Figure 1.3. Object-to-object communication. Calculating the sum is not the responsibility of myObject ”it's the Math object's responsibility. As long as myObject has access to the Math object, it can send the appropriate message and then obtain the result. In general, objects should not manipulate the internal data of other objects (that is, myObject should not directly change the value of myInt1 and myInt2 ). And, for reasons we will explore later, it is normally better to build small objects with specific tasks rather than build large objects that perform many. |

| < Day Day Up > |
EAN: 2147483647
Pages: 164