Section 26. MSAAttribute
26. MSAAttributeOverviewProcess variation affects how resulting products and services appear to Customers. However, what you (and ultimately the Customer) see as the appearance usually does not include only the variability in the entity itself, but also some variation from the way the entity is measured. A simple example of this is to pick up a familiar object, such as this book. If you were to judge if the lettering on this page was "crisp" enough and then you handed the same page to three other people, it is highly likely that there would be a difference in answers amongst everyone. It is also likely that if someone handed you the same page later (without you knowing it was the same page) and asked you to measure it again, you would come to a different answer or conclusion. The page itself has not changed; the difference in answers is purely due to the Measurement System and specifically errors within it. The higher the Measurement Error, the harder it is to understand the true process capability and behavior. Thus, it is crucial to analyze Measurement Systems before embarking on any Process Improvement activities. The sole purpose of a Measurement System in Lean Sigma is to collect the right data to answer the questions being asked. To do this, the Team must be confident in the integrity of the data being collected. To confirm Data Integrity the Team must know
To answer these questions, Data Integrity is broken down into two elements:
And after Validity is confirmed (some mending of the Measurement System might be required first):
Validity is covered in the section "MSAValidity" in this chapter. Reliability is dependent on the data type. Attribute Measurement Systems are covered in this section; Continuous Measurement Systems are covered in "MSAContinuous" in this chapter. An Attribute MSA study is the primary tool for assessing the reliability of a qualitative measurement system. Attribute data has less information content than variables data, but often it is all that's available and it is still important to be diligent about the integrity of the measurement system. As with any MSA, the concern is whether the Team can rely on the data coming from the measurement system. To understand this better it is necessary to understand the purpose of such a system. Attribute inspection generally does one of three things:
Thus, a "perfect" Attribute Measurement System would
Some attribute inspections require little judgment because the correct answer is obvious; for example, in destructive test results, the entity either broke or remained intact. In the majority of cases (typically where no destruction occurs), however, it is extremely subjective. For such a system, if many appraisers (the generic MSA terminology for those doing the measurement) are evaluating the same thing they need to agree
In an Attribute MSA, an audit of the Measurement System is done using 23 appraisers and multiple entities to appraise. Each appraiser and an "expert" evaluate every entity at least twice and from the ensuing data the tool determines
LogisticsConducting an Attribute MSA is all about careful planning and data collection. This is certainly a Team sport because at least two appraisers are required, along with an expert (if one exists), and it is unlikely that Belts apply the Measurement System in their regular job (i.e., the Belt almost certainly won't be one of the appraisers used in the MSA). Planning the MSA takes about two hours, which usually includes a brief introduction to the tool made by the Belt to the rest of the Team and sometimes to the appraisers. Data collection (conducting the appraisals themselves) can take anywhere between an hour and a week, depending on the complexity of the measurement. RoadmapThe roadmap to planning, data collection, and analysis is as follows:
Interpreting the OutputFigure 7.26.1 shows example graphical output from an Attribute MSA. The left side of the graph shows the agreement within the appraisers (analogous to Repeatability), and the right shows the agreement between the appraisers and the standard. The dots represent the actual agreement from the study data; the crosses represent the bounds of a 95% confidence interval prediction for the mean of agreement as the Measurement System is used moving forward. Figure 7.26.1. An example of an Attribute MSA graphical analysis (output from Minitab v14).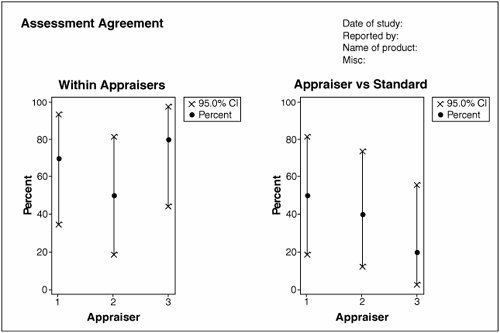 The associated Within Appraiser statistics are shown in Figure 7.26.2. For example, Appraiser 1 agreed with himself in seven out of the ten samples across the two trials. Moving forward, agreement would likely be somewhere between 34.75% and 93.33% (with 95% confidence). To gain a narrower confidence interval, more samples or trials would be required. To be a good, reliable Measurement System, agreement needs to be 90% or better.
The associated Appraiser versus Standard statistics are shown in Figure 7.26.3. For example, Appraiser 1 agreed with the standard in five out of the ten samples. Moving forward, agreement would likely be somewhere between 18.71% and 81.29% (with a 95% degree of confidence). To be a usable Measurement System, agreement needs to be 90% or better, which is clearly not the case here.
The associated Between Appraiser statistics are shown in Figure 7.26.4. The Appraisers all agreed with one other in four out of the ten samples. Moving forward, agreement would likely be somewhere between 12.16% and 73.76% (with a 95% degree of confidence). To be a reliable Measurement System, agreement needs to be 90% or better, which is clearly not the case here.
Another useful statistic in Attribute MSA is Kappa, defined as the proportion of agreement between raters after agreement by chance has been removed. A Kappa value of + 1 means perfect agreement. The general rule is that if Kappa is less than 0.70, then the measurement system needs attention. Table 7.26.1 shows how the statistic should be interpreted.
Figure 7.26.5 shows example Kappa statistics for a light bulb manufacturer's final test Measurement System with five defect categories (Color, Incomplete Coverage, Misaligned Bayonet, Scratched Surface, and Wrinkled Coating). For the defective items, appraisers are required to classify the defective by the most obvious defect. Color and Wrinkle are viable classifications (Kappa > 0.9), but for the rest of the classifications agreement cannot be differentiated from random chance. The p-values here are misleading because they are related to a test of whether the Kappa is (greater than) zero. Just look to the Kappa values for this type of analysis. The overall reliability of the Measurement System is highly questionable because the Kappa for the Overall Test is only 0.52.
After MSA data has been analyzed, the results usually show poor reliability for many Attribute MSAs. This is mainly due to sheer number of ways these types of Measurement Systems can fail:
Given all the preceding possibilities for failure it should be apparent why Belts are strongly encouraged to move to Continuous metrics versus Attribute ones. If only Attribute measures are feasible, there are some actions that help improve reliability of the metric, but there really are no guarantees in this area:
Attribute Measurement Systems are certainly the most difficult to improve, and it is important to check continually for appraiser understanding. It is generally useful to capture data on a routine basis on the proportion of items erroneously accepted or rejected and applying Statistical Process Control to the Measurement System based on this. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
EAN: 2147483647
Pages: 138