7.3 Nonlinear Predictive Techniques
| Linear predictive methods exploit the wideband nature of the useful data signal to suppress the interference. In doing so, they are exploiting only the spectral structure of the spread data signal, not its further structure. These techniques can be improved upon in this application by exploiting such further structure of the useful data signal as it manifests itself in the sampled observations (7.5). In particular, on examining (7.1), (7.2), (7.3), and (7.5), we see that for the single- user case (i.e., K = 1), the discrete-time data signal { c n } takes on values of only Consider again the state-space model of (7.10) “(7.11). The Kalman “Bucy estimator discussed above is the best linear predictor of r n from its past values. If the observation noise { v n } of (7.12) were a Gaussian process, this filter would also give the global MMSE (or conditional mean) prediction of the received signal (and hence of the interference). However, since { v n } is not Gaussian but rather is the sum of two independent random variables , one of which is Gaussian and the other of which is binary ( 7.3.1 ACM FilterIn [309], Masreliez proposed an approximate conditional mean (ACM) filter for estimating the state of a linear system with Gaussian state noise and non-Gaussian measurement noise. In particular, Masreliez proposed that some, but not all, of the Gaussian assumptions used in derivation of the Kalman filter be retained in defining a nonlinearly recursively updated filter. He retained a Gaussian distribution for the conditional mean, although it is not a consequence of the probability densities of the system (as is the case for Gaussian observation noise), hence the name approximate conditional mean that is applied to this filter. In [133, 387, 522] this ACM filter was developed for the model (7.10) “(7.11). To describe this filter, first denote the prediction residual by Equation 7.34 This filter operates just as that of (7.13) “(7.17), except that the measurement update equation (7.14) is replaced with Equation 7.35 and the update equation (7.16) is replaced with Equation 7.36 The terms g n and G n are nonlinearities arising from the non-Gaussian distribution of the observation noise and are given by Equation 7.37 Equation 7.38 where we have used the notation For the single-user system, the density of the observation noise in (7.12) is given by the following Gaussian mixture: Equation 7.39 Let Equation 7.40 we can then write the functions g n and G n in this case as Equation 7.41 Equation 7.42 The ACM filter is thus seen to have a structure similar to that of the standard Kalman “Bucy filter. The time updates (7.13) and (7.15) are identical to those in the Kalman “Bucy filter. The measurement updates (7.35) and (7.36) involve correcting the predicted value by a nonlinear function of the prediction residual Algorithm 7.3: [ACM-filter-based NBI suppression] At time i, N received samples {r iN , r iN+1 , ..., r iN+N-1 } are obtained at the chip-matched filter output (7.5) .
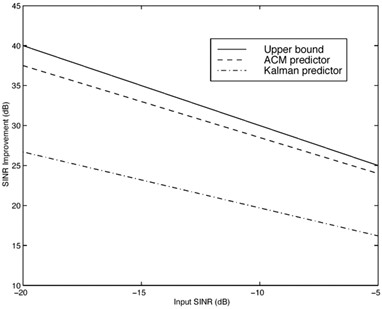
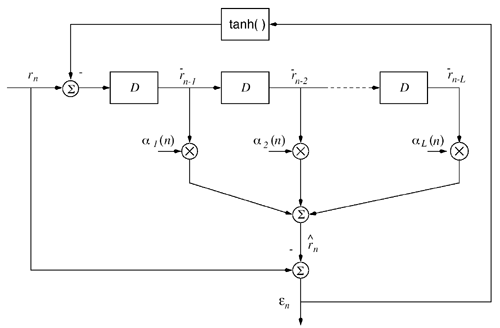
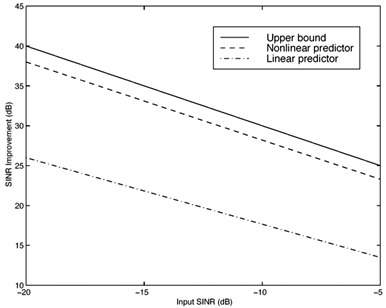
Simulation ExamplesWhen the interference is modeled as a first-order autoregressive process, which does not have a very sharply peaked spectrum, the performance of the ACM filter does not seem to be appreciably better than that of the Kalman “Bucy filter. However, when the spectrum of the interference is made to be more sharply peaked by increasing the order of the autoregression, the ACM filter is found to give significant performance gains over the Kalman filter. Simulations were run for a second-order AR interferer with both poles at 0.99: where { e n } is an i.i.d. Gaussian sequence. The ambient noise power is held constant at s 2 = 0.01, while the total of noise plus interference power varies from 5 to 20 dB (all relative to a unity power spread-spectrum signal). In comparing filtering methods, the figure of merit is the ratio of SINR at the output of filtering to the SINR at the input, which reduces to where Figure 7.5. Performance of the Kalman filter “ and ACM filter “based NBI suppression methods. To stress the effectiveness against the narrowband interferer (versus the background noise), the solid line in Fig. 7.5 gives an upper bound on SNR improvement, assuming that the narrowband interference is predicted with noiseless accuracy. This is calculated by setting 7.3.2 Adaptive Nonlinear PredictorIt is seen that in the ACM filter, the predicted value of the state is obtained as a linear function of the previous estimate modified by a nonlinear function of the prediction error. We now use the same approach to modify the adaptive linear predictive filter described in Section 7.2.2. This technique was first developed in [387, 522]. To show the influence of the prediction error explicitly, using (7.34) we rewrite (7.25) as Equation 7.50 We make the assumption, similar to that made in the derivation of the ACM filter, that the prediction residual Equation 7.51 By transforming the prediction error in (7.50) using the nonlinearity above, we get a nonlinear transversal filter for the prediction of r n , namely, Equation 7.52 where Equation 7.53 The structure of this filter is shown in Fig. 7.6. To implement the filter of (7.52), an estimate of the parameter Figure 7.6. Tapped-delay-line nonlinear predictor. Equation 7.54 where Algorithm 7.4: [LMS nonlinear prediction-based NBI suppression] At time i, N received samples {r iN , r iN+1 , ..., r iN+N-1 } are obtained at the chip-matched filter output (7.5) .
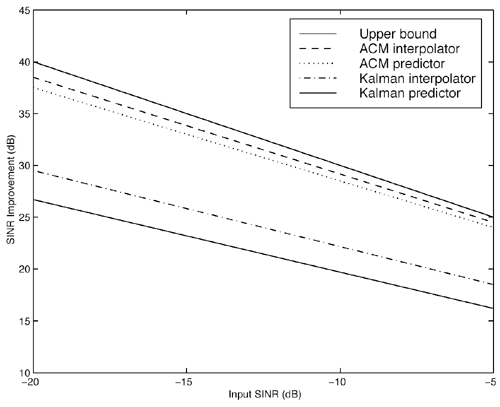
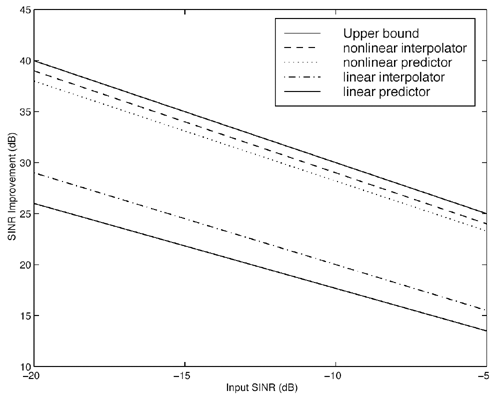
It is interesting to note that the predictor (7.52) can be viewed as a generalization of both linear and hard- decision-feedback (see, e.g., [107, 108, 254]) adaptive predictors, in which we use our knowledge of the prediction error statistics to make a soft decision about the binary signal, which is then fed back to the predictor. As noted above, introduction of this nonlinearity improves the prediction performance over the linear version. As discussed in [387], softening of this feedback nonlinearity improves the convergence properties of the adaptation over the use of hard-decision feedback. Simulation ExamplesTo assess the nonlinear adaptive NBI suppression algorithm above, simulations were performed on the AR model for interference given in Section 7.2. The results are shown in Fig. 7.7. It is seen that, as in the case where the interference statistics are known, the nonlinear adaptive NBI suppression method significantly outperforms its linear counterpart . Figure 7.7. Performance of adaptive linear predictor “ and adaptive nonlinear predictor “based NBI suppression methods. 7.3.3 Nonlinear Interpolating FiltersACM InterpolatorNonlinear interpolative interference suppression filters have been developed in [425]. We next derive the interpolating ACM filter. We consider the density of the current state conditioned on previous and following states. We have Equation 7.60 Equation 7.61 where in (7.60) we made the approximation that, conditioned on i n , the interpolated estimate is still Gaussian: Equation 7.62 with Equation 7.63 Equation 7.64 While the mean and variance of the interpolated estimate at each sample n can be computed via the equations above, recall that the forward and backward means and variances are determined by the nonlinear ACM filter recursions. Simulation ExamplesThe equations above can be used for both the linear Kalman filter and the ACM filter to generate interpolative predictions from the forward and backward predicted estimates. As in the ACM prediction filter, we have approximated the conditional densities as being Gaussian, although the observation noise is not Gaussian. The filters are run forward on a block of data and then backward on the same data. The two results are combined to form the interpolated prediction via (7.63) “(7.64). Simulations were run on the same AR model for interference as that given in Section 7.2. Figure 7.8 gives results for interpolative filtering over predictive filtering for the known statistics case. The filters were run forward and backward for all 1500 points in the block. Interpolator SINR gain was calculated over the middle 500 points (when both forward and backward predictors were in steady state). Figure 7.8. Performance of Kalman interpolator “ and ACM interpolator “based NBI suppression methods. Adaptive Nonlinear Block Interpolator Recall that the ACM predictor uses the interference prediction at time n , Equation 7.65 Equation 7.66 The next block of data follows the same procedure. However, when the next block is initialized , the previous tap weights are used to start the forward predictor, and the interpolated predictions { Simulation ExamplesResults for the same simulation when the statistics are unknown are given in Fig. 7.9. The adaptive interpolator had a block length of 250 samples, with 100 samples being overlapped. That is, for each block of 250 samples, 150 interpolated estimates were made. For the case of known statistics, the ACM predictor already performs well, and there is little margin for improvement via use of an interpolator. The adaptive filter shows greater margin for improvement, on which the interpolator capitalizes. However, in either case, the interpolator does offer improved phase characteristics and some performance gain at the cost of additional complexity and a delay in processing. Figure 7.9. Performance of linear interpolator “ and nonlinear interpolator “based NBI suppression methods. A number of further results have been developed using and expanding the ideas discussed above. For example, performance analysis methods have been developed for both predictive [537] and interpolative [538] nonlinear suppression filters. Predictive filters for the further situation in which the ambient noise { N ( t )} has impulsive components have been developed in [133]. The multiuser case, in which K > 1, has been considered in [425]. Further results can be found in [11, 15, 238, 535, 536]. 7.3.4 HMM-Based MethodsIn the prediction-based methods discussed above, the narrowband interference environment is assumed to be stationary or, at worst, slowly varying. In some applications, however, the interference environment is dynamic in that narrowband interferers enter and leave the channel at random and at arbitrary frequencies within the spread bandwidth. An example of such an application arises in the littoral sonobuoy arrays mentioned in Section 7.1, in which shore-based commercial VHF traffic, such as dispatch traffic, appears throughout the spread bandwidth in a very bursty fashion. A similar phenomenon arises when the direct-sequence system coexists with a frequency- hopping system, which happens, for example, when wireless LANs and Bluetooth systems operate in the same location. A difficulty with use of adaptive prediction filters of the type noted above is that when an interferer suddenly drops out of the channel, the " notch " that the adaptation algorithm created to suppress it will persist for some time after the signal leaves the channel. This is because, while the energy of the narrowband source drives the adaptation algorithms to suppress an interferer when it enters the channel, there is no counterbalancing energy to drive the adaptation algorithm back to normalcy when an interferer exits the channel. That is, there is an asymmetry between what happens when an interferer enters the channel and what happens when an interferer exits the channel. If interferers enter and exit randomly across a wide band , this asymmetry will cause the appearance of notches across a large fraction of the spread bandwidth, which will result in a significantly degraded signal of interest. Thus, a more sophisticated approach is needed for such cases. One such approach, described in [67], is based on a hidden-Markov model (HMM) for the process controlling the exit and entry of NBIs in the channel. An HMM filter is then used to detect the subchannels that are hit by interferers, and a suppression filter is placed in each such subchannel as it is hit. When an exit is detected in a subchannel, the suppression filter is removed from that subchannel. Related ideas for interference suppression based on HMMs and other "hidden data" models have been explored in [219, 238, 355, 375]. |
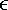
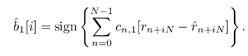
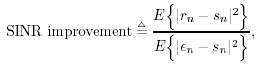
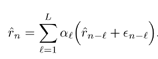
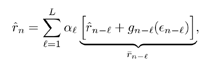
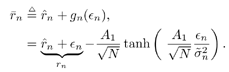
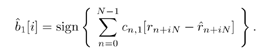
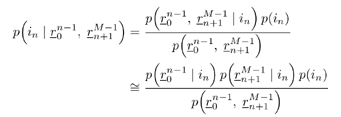
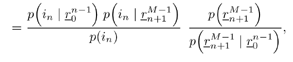
EAN: 2147483647
Pages: 91