USE OF DATA MINING IN DESIGNING THE LEARNING PROCESS
USE OF DATA MINING IN DESIGNING THE LEARNING PROCESSThe learning process conceptually consists of analyzing the data of the stored cases to infer information that allows updating the discriminating function of the system domains. As it was previously indicated, this discriminating function defines the system knowledge base. This updating is necessary to avoid possible classification errors as described in the previous section. To carry out this task, data mining is the suitable technology (tool). The first step in designing the learning process is to design a cases base in which data of queries and their respective results are stored. Conventional data-mining processes are carried out on a database whose structure was designed without taking into account such a process. For this reason, at their initial stages, these processes involve tasks such as selection, preprocessing, transformation, etc., that are needed to generate a convenient data structure to be analyzed. A way of simplifying the mining process is to take into account these tasks while designing the data structure to store cases in the cases base.
Structure of Data Associated with a QueryAs it has been described, whenever a user performs a query, the system classifies domains according to its knowledge base. Then, the query is sent to domain dj ∊ DP having the greatest discriminating score RSV(dj, qi). If the query is not positively answered, it is sent to domain dj∊DP having the following lower discriminating score RSV(dj, qi) and so forth, till one of the domains positively answers the query. In general, if the classification error does not affect the system efficacy, some of the dj∊DP should answer positively. The data associated with each information requirement qi, which are necessary for the learning process, will be stored as a case. Taking into account the possible classification errors previously discussed, it will be necessary to store the following data: the query qi, the RSV(dj,qi) (discriminating function value) of domains classified into the DP criterion set (Potential domain set), the taxonomy Kdj of each domain dj∊DP, and the valuation of the answer va (dj, qi) emitted by the user of domain dj answering to query qi. It should be stressed that from the learning point of view, the information in the answer to the query does not matter, but what does matter is whether the required information was provided by a domain or not. Therefore, the variable called valuation of the answer va (dj, qi), which was described in previous sections, was introduced. The logical structure of data to be stored for a specific query is summarized in Table 2.
The first field, which is called Domain, stores the name that identifies each domain dj∊DP. The second field, called ValuationAnswer (VA), stores the value of the qualitative value va (dj, qi). In the third field, the RSV(dj, qi) is stored. This is the value of the discriminating function that helps to determine the position of the domain dj∊DP in the ranking. In the remaining fields, the values of the discriminating function weights are stored, wpk ∀ pk ∊ Kqi ∩ Kdj / dj∊DP. These are the weights of keywords that appear in the query and belong to the domains classified into the DP criterion set. A field value equal to 0 indicates that the keyword associated to this field is not stated in the taxonomy of the respective domain. Let us consider the following example: Query: How many items of product X were for sale in promotion? Filtered Query: Kq1 = {items, product, X, sale, promotion} This example shows that four domains of the system were classified as potential, Dp={Marketing, Production, Forecast, Sales}. The Marketing domain presents the smallest RSV value, and therefore is the fourth one in the ranking. Moreover, this domain answers the consult in a positive way, va(Marketing, q1) = Positive. Forecast and Sales domains, which are second and first in the ranking, respectively, answer the consult in a negative way, va(Forecast, q1) = va(Sales, q1) = Negative. The Production domain presents a va(Forecast, q1) = Null, since it exceeded the time period it had to answer the consult. Finally, the intersection set between the set of keywords of the query and the set of keywords that define the taxonomy of Marketing domain is integrated by the following keywords: product and promotion. Thus, Kq1 ∩ K(marketing) = {product, promotion}. For that reason, the respective weights of the discriminating function are higher than zero. As the keyword Sale is not include into Marketing taxonomy, the weight factor associated to the discriminating variable Sale is wsale = 0.
The logical structure of data represented in Table 2, which is defined to store a case, allows easily visualization of the results associated to a query qi. In other words, it is a visualization of data in the queries or cases dimension. From the point of view of the need for learning that has been posed, this is not a convenient structure, since in order to evaluate possible domain classification errors, it is necessary to visualize data from the domains dimension.
Visualization of Data of the Cases Base in the Domains DimensionTable 4 presents a logical structure of data in the cases base that allows observing a domain's behavior before the various queries. This structure will store, for a given domain dj, all queries qi, for which RSV(dj, qi) > cutoff score. Essentially, this data structure uses binary fields to represent the relationship between a query qi, which is defined by the set of keywords Kqi, and the domain taxonomy Kdj.
In Table 4, the first field, Query, stores the name that identifies each query qi. The second field, called VA, stores the qualitative variable value va(dj, qi). According to what has been described in previous sections, in order to determine possible errors in the classification efficiency, the RSV(dj, qi) value itself does not matter, but the relative position of each domain dj∊DP does. Therefore, the third field (Order) stores the order that domain obtained in the ranking of domains classified as potential to answer to the query qi. The remaining fields are divided into two groups. In the first group, each field represents a keyword of the domain taxonomy. Each field is designated with a keyword pk∊ Kdj, and represents a binary variable pk that takes 1 as its value if the keyword pk of the domain taxonomy is in the query qi, and takes 0 as its value if pk is not stated in that query.
In the second group, each field represents a keyword stated in query qi that does not belong to the domain taxonomy. Each of these fields is designated with a keyword p'k and represents a binary variable p'k that takes 1 as its value if the keyword p'k is stated in the query qi but does not belong to the domain taxonomy dj, and takes 0 as its value if p'k is not in that query.
Let us consider the previous example. Let us suppose that it is the first case for which the domain is classified as having potential for answering to the query: Query: How many items of product X were for sale in promotion? Filtered query: Kq1 ={items, product, X, sale, promotion} Marketing Domain
Production Domain
Forecast Domain
Sales Domain
Thus, we have a structure for each system domain. Each structure stores the way in which the domain behaved for the different queries for which it has been classified as potential. In the following section, we will see how this logical data structure meets the posed learning needs.
Application of Data Mining to the Learning Process DesignOnce the logical data structure is designed and the cases are stored, the latter must be analyzed using data mining. The object is to analyze the data kept in the cases base so as to identify relationships among the data from which possible behavior patterns of cases can be defined. Such patterns are used to define rules for updating the discriminating function of each domain, which is stored in the knowledge base. This requires working with the cases data associated to the involved domain. For this purpose, the logical data structure presented in Table 4 of the previous section will be used. According to what has been discussed, the updating can be performed in two ways: either updating the weights of the keywords (predicting variables) that define the domain taxonomy or modifying the domain taxonomy by adding new keywords.
Patterns ObtainmentOnce a significant number of cases qi are stored, we can perform a mining of these data to look for patterns. For that purpose, we define Qdj as the set of stored cases qi associated to dj. That is, Qdj = {qi / RSV(dj, qi) > cutoff score}. To start with, cases qi ∊ Qdj are classified into four groups: a first group formed by cases in which no classification error occurred; a second group of cases in which the domain provided a positive answer, but it was not the first one in the ranking of potential domains (these are cases in which the classification error affected the system efficiency); a third group of cases, in which the domain provided a negative answer; and, finally, a fourth group of cases in which the query was not answered. To carry out this classification, va(dj, qi) and or(dj, qi) are defined as predicting variables. Group of efficient cases Q+dj: integrated by those cases that present va(dj,qi) = positive and or(dj,qi) =1
Group of non-efficient cases Q*dj: integrated by those cases that present va(dj,qi) = positive but or(dj,qi) >1
Group of negative cases Q−dj: integrated by those cases that were answered in a negative way.
Group of Null cases Q0dj: integrated by those cases in which an answer was not provided.
Once qi ∊ Qdj cases are classified into one of the four defined groups, the purpose is to infer rules to update the discriminating function of each domain that is stored in the knowledge base. The action of these rules will be to:
With the aim of interpreting the relationships among variables, we present three main rules obtained by the mining process that will be used to develop the system learning process:
In the condition of this rule, we are saying that a word belonging to the domain taxonomy is a candidate for increasing its weight if:
Now, we present the rule for the incoming of new words into the domain taxonomy.
In the first condition of this rule, we say that a word is a candidate for entering a Kdj if:
A word can enter Kdj if the amount of domains in the system is much higher than the quantity of domains in which p is stated or is a candidate.
In the condition of this rule, we are saying that a word p is a candidate for diminishing its weight if:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

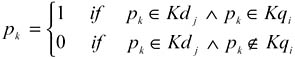
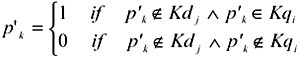



EAN: 2147483647
Pages: 194