Working with Regular Expressions
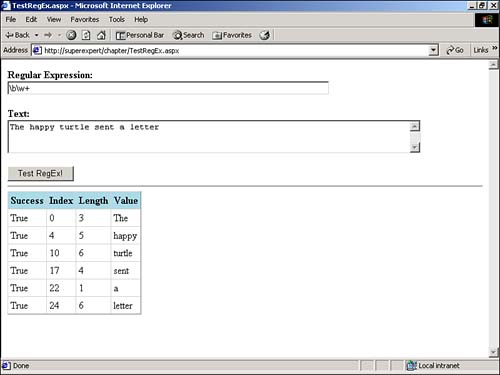
| You can use regular expressions to perform very complex pattern matching. You'll quickly discover that you need to make use of regular expressions within a number of different contexts when building ASP.NET applications. In Chapter 3, "Performing Form Validation with Validation Controls," for example, you learned how to use the Validation controls to validate HTML form data. One of the Validation controls, RegularExpressionValidator , depends on regular expressions. You can use regular expressions with RegularExpressionValidator to validate email addresses, Social Security numbers, and Internet addresses, for example. With a proper understanding of how regular expressions work, you can validate any sequence of characters and numbers with RegularExpressionValidator and the proper regular expressions. You also can use regular expressions to perform complex formatting operations. You can use regular expressions not only to match expressions, but also to replace expressions. For example, imagine that you need to convert a plain text document into an HTML document that you can display at your Web site. You can automatically insert the correct HTML tags into the document by taking advantage of regular expressions. In the following sections, you learn about the implementation of regular expressions in the .NET framework. You also learn how to use regular expressions to both match and replace expressions. Using Regular Expression ClassesYou use three main classes in the .NET framework when working with regular expressions: RegEx , Match , and MatchCollection . All three classes can be found in the System.Text.RegularExpressions namespace. The RegEx class represents a regular expression. You initialize it with a regular expression like this: Dim objRegEx As RegEx objRegEx = New RegEx( "b[iao]t" ) This example initializes a new RegEx class named objRegEx with the regular expression "b[iao]t" . This regular expression matches the strings bit , bat , and bot . After you initialize an instance of the RegEx class, you can check whether a string matches a regular expression by calling the RegEx IsMatch method: Dim objRegEx As RegEx objRegEx = New RegEx( "b[iao]t" ) If objRegEx.IsMatch( "bat" ) Then Response.Write( "It's a Match!" ) End If In this example, the IsMatch method returns the value True because the string bat matches the regular expression b[iao]t . Alternatively, you can use an instance of the RegEx class to match and replace parts of a string. For example, the following instance of the RegEx class replaces all vowels in a string with question marks: Dim objRegEx As RegEx Dim strString As String objRegEx = New RegEx( "[aeiou]" ) strString = "The slow-moving aardvark" Response.Write( objRegEx.Replace( strString, "?" ) ) In this case, the Replace method returns the string Th? sl?w-m?v?ng ??rdv?rk . If you need additional information about the expression matched by the RegEx class, you can return an instance of the Match class: Dim objRegEx As RegEx Dim objMatch As Match objRegEx = New RegEx( "b[iao]t" ) objMatch = objRegEx.Match( "The bat flew in the window" ) Response.Write( "<p>Success: " & objMatch.Success ) Response.Write( "<p>Index: " & objMatch.Index ) Response.Write( "<p>Value: " & objMatch.Value ) In this example, the Match method returns an instance of the Match class. If a match is found, the Success property returns the value True , the Index property returns the position of the match, and the Value property returns the matching expression. A regular expression can match a string in multiple places. If multiple matches are found, you can use the MatchCollection class to represent all the matches: Dim objRegEx As RegEx Dim objMatch As Match Dim objMatchCollection As MatchCollection objRegEx = New RegEx( "[aeiou]" ) objMatchCollection = objRegEx.Matches( "The bat flew in the window" ) For Each objMatch in objMatchCollection Response.Write( "<p>Success: " & objMatch.Success ) Response.Write( "<p>Index: " & objMatch.Index ) Response.Write( "<p>Value: " & objMatch.Value ) Next In this example, the Matches method returns an instance of the MatchCollection class. A For...Each loop displays the information from each match represented by the MatchCollection class. To make it easier for you to follow the discussion of regular expressions in this section, I've included the page in Listing 24.9 so that you can test a regular expression (see Figure 24.2). Listing 24.9 TestRegEx.aspx<Script Runat="Server"> Sub Button_Click( s As Object, e As EventArgs ) Dim objRegEx As RegEx objRegEx = New RegEx( txtRegularExpression.Text ) dgrdMatches.DataSource = objRegEx.Matches( txtMatchExpression.Text ) dgrdMatches.DataBind() End Sub </Script> <html> <head><title>TestRegEx.aspx</title></head> <body> <form Runat="Server"> <b>Regular Expression:</b> <br> <asp:TextBox ID="txtRegularExpression" Columns="80" Runat="Server" /> <p> <b>Text:</b> <br> <asp:TextBox ID="txtMatchExpression" TextMode="MultiLine" Columns="80" Rows="3" Runat="Server" /> <p> <asp:Button Text="Test RegEx!" OnClick="Button_Click" Runat="Server" /> <hr> <asp:DataGrid ID="dgrdMatches" CellPadding="4" HeaderStyle-BackColor="LightBlue" HeaderStyle-Font-Bold="True" AutoGenerateColumns="False" Runat="Server"> <Columns> <asp:BoundColumn HeaderText="Success" DataField="success" /> <asp:BoundColumn HeaderText="Index" DataField="Index" /> <asp:BoundColumn HeaderText="Length" DataField="Length" /> <asp:TemplateColumn> <HeaderTemplate> Value </HeaderTemplate> <ItemTemplate> <%# Server.HtmlEncode( Container.DataItem.Value ) %> </ItemTemplate> </asp:TemplateColumn> </Columns> </asp:DataGrid> </form> </body> </html> The C# version of this code can be found on the CD-ROM. Figure 24.2. Testing regular expressions. The page in Listing 24.9 contains a form with two TextBox controls. You can enter a regular expression in the first TextBox control and some text in the second TextBox control. When you click the Button control, the Button_Click subroutine executes. The Button_Click subroutine evaluates the regular expression and text on the form and binds the results to a DataGrid control, which displays all the properties of each Match class that match the regular expression. Examining Elements of a Regular ExpressionA regular expression typically contains both literal text and metacharacters. Literal text, as you might assume, is nothing more than plain, ordinary text. You can place literal text in a regular expression to perform an exact character-by-character match. For example, the regular expression let matches any occurrence of the characters let in a string. The regular expression matches the word let , the first part of the word letter , and the last part of the word hamlet . Regular expressions get interesting when you start using metacharacters. Metacharacters enable you to match much more than simple sequences of characters. For example, you can use metacharacters to match only words, only words that start with the letter P , or words that appear at the beginning or end of a line of text. Matching Single CharactersYou can use metacharacters to define character classes. A character class is a set of characters that you can use to match a single character. Imagine that you want to match every instance of the word affect in a string, but you know that people often use the word effect to mean the same thing. You can use the following regular expression to match either word: [ae]ffect The brackets define a character class. You can place multiple characters within brackets to represent any one of the multiple characters. The characters do not have to be letters . The following regular expression matches any single punctuation symbol: [!?.,] You also can specify a range of characters in a character class. For example, the following character class matches any single uppercase character: [A-Z] You can also use a range with numerals: <font size="[1-9]"> This regular expression would match <font size="3"> and <font size="5"> , but not <font size="33"> . A character class matches only a single character at a time. NOTE To match a hyphen in a character class, list the hyphen as the first character. You can include multiple character classes in a single regular expression. For example, the following regular expression matches a time of the form 12:59pm: [01][0-9]:[0-5][0-9][ap]m This regular expression matches 03:59am and 12:22pm but does not match 3:59am. You also can use a caret ( ^ ) within a character class to exclude characters. For example, the following regular expression fails to match words that contain the letter a in their second position: m[^a]t This regular expression matches mit and met , but not mat . Matching Special CharactersYou can use the following special characters in a regular expression:
You can use the following code, for example, to replace newline characters with HTML <br> characters: Dim objRegEx As RegEx Dim strString As String strString = "The slow-moving aardvark." & vbNewline strString &= "The happy turtle." objRegEx = New RegEx( "\n" ) Response.Write( objRegEx.Replace( strString, "<br>" ) ) The following list describes metacharacters that represent character classes:
The dot character ( . ) is particularly useful. You can use it to represent any single character. Consider the following regular expression: 12.25.99 This regular expression matches various data formats, including 12/25/99, 12-25-99, _12 25 99, and even 12.25.99. The following metacharacters do not represent characters, but represent the position of characters in a string:
You can use the \b metacharacter, for example, to match word boundaries. So, if you want to match the word let , but not letter or hamlet , you can use the following: \blet\b The \A and \z metacharacters are useful for guaranteeing that a string contains a certain expression and nothing else. For example, you might want to check whether a Text control contains the word secret without any extraneous characters, newline characters, or whitespace. You can check for the word secret by using the following regular expression: \Asecret\z This regular expression matches an expression that starts at the beginning of a string and ends at the end of the string. NOTE The list of metacharacters in this section is not exhaustive. See the .NET Framework SDK Documentation for a complete list of metacharacters. One additional metacharacter warrants discussion in this section. Because metacharacters, such as the dot character ( . ), have a special meaning, you can't use them to represent a literal character. To represent a period, you need to place a backslash before it like this: \. The backslash works as an escape character. You can use it with a metacharacter to represent the character's literal value. Matching Alternative Sequences of CharactersThe character classes and metacharacters you have examined thus far enable you to represent alternative characters but not alternative sequences of characters. For example, imagine that you want to match either a <p> or <br> tag in a string. To match either sequence of characters, you need to use the alternation metacharacter like this: <p><br> When using the alternation character, you often need to group characters with parentheses. For example, the following regular expression matches both color and colour : col(oou)r You also can use parentheses to control the precedence of other metacharacters. If you need to find every occurrence of the name Bill or Ted starting on a word boundary, you can use the following: \b(billted) Notice that the preceding regular expression means something different than the following one: \bbillted This latter example matches the word malted because the \b metacharacter applies only to bill . Matching with QuantifiersYou can use quantifiers to match a sequence of characters a certain number of times. The following list describes the quantifiers that you can use with regular expressions:
Suppose that you want to match both the words aardvark and aardvarks . You can use the ? quantifier to indicate that the s is optional like this: aardvarks? Or, imagine that you know that all product codes in your company start with the letter p and contain between three and five numerals. In that case, you can match a product code by using the following regular expression: \bp\d{3,5}\b In this example, the \b checks whether the product code starts at a word boundary, the \d{3,5} indicates a string of between three and five digits, and the \b represents the end of the word boundary. You also can use quantifiers with parentheses, as follows , so that the quantifiers apply to a whole sequence of letters: The( very)? slow-moving aardvark This regular expression matches both "The very slow-moving aardvark" and "The slow-moving aardvark" . Identifying Regular Expressions and GreedSome of the quantifiers are greedy. They match the characters that you intend for them to match, but they keep matching additional characters. The * quantifier, for example, matches zero or more characters. Imagine that you want to match any HTML tag in a string. You might be tempted to match HTML tags with the following regular expression: <.*> This regular expression reads: Match any character that appears zero or more times between a < and > . This seems like a perfect regular expression for hunting down HTML tags. Now, imagine that you applied this regular expression to the following string: A <i>quantifier</i> can be <big>greedy</big>. You might expect the regular expression to match the tags <i> , </i> , <big> , and </big> . Unfortunately, the * quantifier gets too ambitious and matches the whole expression <i>quantifier</i> can be <big>greedy</big> . The * quantifier matches the i that follows the first < , but then it also matches the > and every other character that follows until it reaches the final > at the end of </big> . To handle this problem, you need to use a special nongreedy modifier with the quantifier: ? . So, to fix the regular expression in the preceding example, you would use the following: <.*?> The ? forces the * quantifier to be nongreedy. This regular expression correctly matches <i> , </i> , <big> , and </big> . The ? forces the quantifier to match as few characters as possible. You can use the ? modifier with several of the quantifiers:
Capturing and BackreferencesCapture groups work like variables in a regular expression. A capture group enables you to capture a pattern of characters in a regular expression and refer to the pattern by either a number or name later in the regular expression. You indicate a capture group in a regular expression by using parentheses. For example, the following regular expression contains a capture group with the characters aardvark : The slow-moving (aardvark) After you capture an expression, you can refer to it later in the regular expression by using a backreference. For example, the expression \1 is used as a backreference in the following regular expression: The slow-moving (aardvark) This regular expression matches a string that contains The slow-moving aardvark aardvark . Why are capture groups useful ? You can use a capture group to match repeating patterns of characters. For example, imagine that you want to match any string that contains the same two letters in a row. You can match repeating characters by using the following regular expression: (\w) The parentheses in this regular expression capture any single word character. Later in the regular expression, the \1 backreference refers to the captured expression. If you apply this regular expression to The happy aardvark , the regular expression would match both the pp in happy and aa in aardvark . NOTE Parentheses can be used for a number of different functions in a regular expression. For example, you use parentheses with alternation to group alternative sequences of characters. By default, whenever you use parentheses, the characters contained within the parentheses are captured. You can disable this default behavior by using the n option (discussed in the section "Setting Regular Expression Options") or by adding ?: to the parentheses like this: (?:aardvark)(?:turtle) This regular expression does not capture the characters aardvark or turtle . You can capture multiple groups of characters in a regular expression by using multiple sets of parentheses. You can refer to each captured group by using \1 , \2 , \3 , and so on. For example, the following regular expression matches any four letters in a row when the last two letters are reversed copies of the first two letters: (\w)(\w) When applied to the following sentence , this regular expression matches the ette in letter : The aardvark sent a letter Instead of using numbered backreferences to refer to capture groups, you can name the capture groups. For example, the following regular expression matches any two repeating characters in a string using a named backreference: (?<myLetter>\w)\k<myLetter> The construct (?<myLetter..) creates a capture group with a name. In this case, the name is myLetter . The construct \k<myLetter> is a named backreference to the capture group. Suppose that you want to match any two words in a row such as the the . You can match repeating words by using the following regular expression: \b(\w+)\s+\b This regular expression matches any expression that starts on a word boundary, contains one or more numerals or letters, is followed by at least one whitespace character, and contains the same sequence of numerals or letters followed by a word boundary. In other words, it matches the same word twice in a row. You can rewrite this regular expression to use a named capture group like this: \b(?<repeat>\w+)\s+\k<repeat>\b This regular expression refers to the group of letters captured in the parentheses with the name repeat . Using Replacement PatternsA replacement pattern is the string that you supply to the RegEx Replace method when you want to replace expressions in a string. For example, suppose that you want to replace every instance of the word very in a string with the word extremely . You can accomplish this task by using the following code: Dim objRegEx As RegEx Dim strString As String strString = "The very slow-moving aardvark." objRegEx = New RegEx( "very" ) Response.Write( objRegEx.Replace( strString, "extremely" ) ) You can refer to capture groups in a replacement pattern. In the preceding section, you learned how to refer to capture groups by using both numbered backreference expressions, such as \1 and \2 and named backreference expressions, such as \k<repeat> or \k<myLetter> . Within a replacement pattern, you must refer to a capture group with a slightly different syntax. In a replacement pattern, you refer to a capture group by number using $1 , $2 , and so on, and by name using ${repeat} , ${myLetter} , and so on. Suppose that you want to replace every instance of the HTML <h#> tag with the HTML <font> tag. If the tag <h1> appears in the string, you want to replace it with <font size=1> ; if the tag <h2> appears in a string, you want to replace it with <font size=2> ; and so on. You can do so by using the following code: Dim objRegEx As RegEx Dim strString As String strString = "<h4>Grocery List</h4>" & _ "<h3>eggs</h3>" & _ "<h3>milk</h3>" & _ "<h3>pancake mix</h3>" objRegEx = New RegEx( "<h(\d)>(.*?)</h>" ) Response.Write( objRegEx.Replace( strString, "<font size=></font>" ) ) In this example, the RegEx class is initialized with the following regular expression: <h(\d)>(.*?)</h> This regular expression matches an opening and closing HTML header tag. It contains two capture groups. The first capture group contains a single digit for the size of the heading. The second capture group contains the text that appears between the opening and closing header tag. This regular expression is used with the following replacement pattern: <font size=></font> In this replacement pattern, the $1 refers to the first capture group in the regular expression, and the $2 refers to the second capture group. So, the $1 is replaced with the size of the header, and the $2 is replaced with the original contents of the header tag. When all is said and done, the string <h4>Grocery List</h4> <h3>eggs</h3> <h3>milk</h3> <h3>pancake mix</h3> is replaced with the string <font size=4>Grocery List</font> <font size=3>eggs</font> <font size=3>milk</font> <font size=3>pancake mix</font> Setting Regular Expression OptionsYou can set a number of options when working with regular expressions. These options can be found in the RegexOptions enumeration in the System.Text.RegularExpressions namespace. These options are as follows:
All these options have the value False by default. You can enable any of them in two ways. First, you can enable one or more options for a regular expression as a whole when you declare it like this: Dim objRegEx As RegEx objRegEx = New RegEx( "match me!", RegexOptions.IgnoreCase ) The first parameter here is the regular expression, and the second parameter contains the IgnoreCase option. If you need to specify multiple options, use the Or operator like this: Dim objRegEx As RegEx objRegEx = New RegEx( "match me!", RegexOptions.IgnoreCase Or RegexOptions.Singleline ) You also can set options within the regular expression itself. This capability is useful when you want the option to apply to only part of a regular expression: (?i:aardvark) This regular expression enables matches that are not case sensitive with the i option. You can list multiple options and disable particular options like this: (?im-r:aardvark) This regular expression enables matches that are not case sensitive and multiline mode and disables right-to-left matching. The most useful of the regular expression options is IgnoreCase . For example, the following regular expression matches Aardvark, aardvark , and AArDVark : (?i:aardvark) The Multiline option is also useful. It affects how the beginning-of-string metacharacter ( ^ ) and end-of-string metacharacter ( $ ) are interpreted. By default, the ^ metacharacter matches only the very beginning of a string, even if the string contains multiple lines of text. If you enable the Multiline option, the ^ and $ metacharacters match the beginning and end of each line of text. Consider this text: The aardvark went to the store. The aardvark bought some eggs. If you apply the regular expression ^The to this text when not in Multiline mode, only the first The in the text is matched. However, if you apply the regular expression in Multiline mode, both instances of The are matched. Another regular expression option can be used for Singleline mode. This can be confusing because Singleline mode is not the opposite of Multiline mode. In fact, you can enable both Singleline and Multiline modes for the same regular expression at the same time. The Singleline option affects how the dot metacharacter ( . ) is interpreted. Normally, a dot matches all characters except a newline. In Singleline mode, however, a dot also matches a newline character. Let's return to the previous text for another example: The aardvark went to the store. The aardvark bought some eggs. By default, if you apply the regular expression .+ to this text, the regular expression returns the following two matches: The aardvark went to the store. and The _aardvark bought some eggs. . Two matches are found because, by default, the dot character automatically stops when it encounters a newline character. In Singleline mode, in contrast, the regular expression .+ returns only a single match: The aardvark went to the store. The aardvark bought some eggs. . A single match is returned because, in Singleline mode, the dot keeps going past the newline character. |
EAN: 2147483647
Pages: 263