Determining What to Measure in a VoIP SLA In a VoIP deployment, you want your phone users to be as happy with the level of service being delivered as they were with the PSTN. SLAs provide a target for the actual performance your VoIP system delivers. In a sense, an SLA is quite a simple matter: You define performance and availability goals and then monitor the system to see how well you are meeting them. But just as a VoIP SLA can include a huge variety of performance metrics to be monitored, so can it be defined in many different ways. What kind of SLA is best for you? It depends. First of all, do you need an internal or external SLA, or both? Consider the definitions: -
Internal SLA— An SLA within your enterprise. It typically describes the mutual expectations between users of the system and another internal organization, such as your IT group. -
External SLA— An SLA between your company or organization and a third-party service provider. The service provider may be an ISP, carrier, or other VoIP outsourcer. The type of SLA you need is determined by business requirements and user expectations. You may end up with both types of SLAs, or you may develop only one. However, key components of both types of SLAs are the metrics that will be collected and evaluated. The metrics you emphasize should be based on your overall business goals. The key SLA metrics can be categorized into four main groups: -
Availability -
Call-setup performance -
Call quality -
Incident tracking Each of these categories contains several submetrics. The sections that follow cover each group of metrics in more detail. Availability As discussed in previous chapters, today's PSTN users expect to hear a dial tone 99.999 percent of the time when they pick up a phone. This expectation makes availability important in any VoIP SLA. But what exactly does the term availability include? To begin with, you want to hear a dial tone when you pick up the phone; to state the case simply, no dial tone equates to being unavailable. Next, when you dial a phone number, you expect the call to go through; no ringing or a network busy signal equates to being unavailable. Finally, while you are talking, you expect to be able to complete the call without being disconnected; abnormal call termination equates to being unavailable. In addition to directly measuring downtime, here are some of the submetrics to monitor and include in an SLA that tracks availability: -
IP PBX availability— Is the IP PBX (or equivalent server) active and functioning properly? If not, how long was it down due to hardware, software, or network problems? Was the IP PBX unavailable while patches or updates were applied? If multiple IP PBXs are involved, this metric captures the availability statistics of all of them. -
Network availability— VoIP calls depend on the IP network. Is network connectivity available? If not, how long has the outage persisted? Was the network unavailable during router updates or configuration changes? You probably already have some SLAs in place for network availability. Consider updating them for VoIP by making them more stringent. -
Network service availability— Many IP phones and VoIP servers rely on critical network services to perform call routing. Are the DNS and DHCP servers available? Are these network services running? If DNS and DHCP are unavailable, users may not be able to make any calls. -
Call-completion percentage— This metric is sometimes referred to as the answer seizure rate in the telephony community. It represents the percentage of attempted calls that were successfully completed. A low call-completion percentage generally points to declining availability. -
Abnormal disconnections— These refer to calls that were not ended by one of the talkers. How many calls that were in progress were abnormally terminated? Where did these disconnections occur? A high number of dropped calls may point to declining availability. -
Line busy— How many times did a caller receive a busy signal? Was the line really busy, or was the busy signal an indicator of oversubscribed gateway ports? The key metric here is the number of busy call attempts caused by oversubscription of resources. Because availability metrics are so basic to the health of your entire system—and to users' satisfaction levels—they are the first group of statistics to put in a VoIP SLA. Next, you need to think about what happens when availability is good, but performance problems plague calls during setup. Call-Setup Performance When you make a VoIP call, a complex series of events has to occur in sequence, and without errors. The first set of events, the call-setup phase, takes care of getting a dial tone, dialing the phone number, and getting a result, either ringing at the desired location or a busy signal. Several different protocols are used for call-setup in various VoIP implementations, and all could experience poor performance. Call-setup protocols such as H.323, SIP, SCCP, MGCP, and Megaco operate principally using the TCP protocol, sending a large number of different flows between the IP phones and VoIP server to establish a call between two parties. Call setup can involve many network flows. Figure 7-1 shows the simplest example of call setup using SIP between two IP phones.[1] Figure 7-1. Simple Example of Call Setup Using SIP 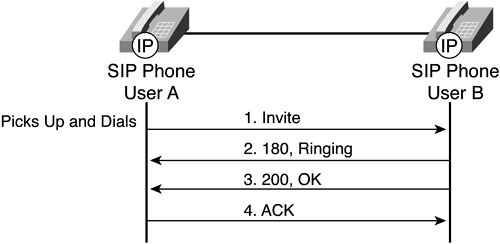
Poor call-setup performance can affect the user's initial perception of the call. If the normal sequence of tones and responses is not provided quickly enough, users may get impatient and hang up. Call setup can be divided into two subphases: -
Dial tone response time— The amount of time that elapses from the moment you pick up the phone until you hear a dial tone. If the delay is long enough, users may think the system is unavailable. Today, most IP phones generate a dial tone almost instantaneously, so this metric may not be a major issue for your systems. However, it is still vitally important. A good upper bound to use is two to three seconds. Any additional delay would not be acceptable to most users. -
Call-setup response time— The amount of delay between the time you dial the phone number and the time you hear ringing or get a busy signal (sometimes referred to as post-dial delay). How much delay is too much for this metric? It depends on the users and their expectations. But if the delay becomes too long, some users may get frustrated and hang up, thinking the call cannot go through. A good upper bound for call-setup response time is 2.5 seconds.[2] This matches the average call-setup response time in the PSTN. You should also pay close attention to call-setup response times for calls between the VoIP system and the PSTN. There is extra work involved in routing IP calls over analog lines, and gateway signaling protocols, such as MGCP and Megaco, are added to the mix. Translations between signaling protocols at the gateway may add additional delays to the call-setup time. Call-setup metrics must be considered in any VoIP SLA. Next, you need to take into account what happens when availability is good and call-setup completes quickly, but the call quality is poor. Call Quality Users have well-established expectations for a VoIP system: It ought to sound as good as the PSTN. As a result, call quality is a key component of a VoIP SLA. The mean opinion score (MOS) is the standard metric for user perception of call quality. The SLA for all calls should be drafted in terms of the MOS scale, from 1.0 to 5.0. A MOS of 4.0 or higher is considered toll quality or equivalent to the PSTN. A MOS of 4.0 should be considered good, 3.6 and above is acceptable, and anything below 3.6 should not be considered acceptable for business-quality calls. Figure 7-2 shows user satisfaction with different MOS values. Figure 7-2. User Satisfaction Shown on a MOS Scale 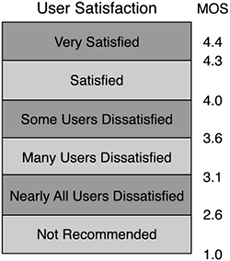
When you incorporate the MOS into your SLA, you create an additional requirement: You need tools that can monitor the performance of calls on your network and calculate a MOS from what is measured. Chapter 3, "Planning for VoIP," discussed the network-performance metrics used to calculate MOS: -
Delay— VoIP traffic is intolerant of excessive delay. Long delays can make phone calls sound like walkie-talkie conversations. SLAs for delay are usually specified as a maximum allowable in milliseconds for packet delivery. The widely accepted limit for end-to-end delay is 150 ms; if your delay exceeds 150 ms in a single direction, it is likely that the MOS will decline. -
Jitter— Variations in packet arrival times can cause packets to be discarded and VoIP call quality to suffer. SLAs for jitter are usually specified in maximum allowable milliseconds of variability in delay among packets transmitted from the same source. A good number for the maximum allowable jitter is 40 ms. -
Lost packets— If lost, VoIP packets are not retransmitted. Lost packets thus result in clipped syllables or even missing words in a call. SLAs for lost packets are usually specified as a maximum allowable percentage lost of all packets sent. A packet loss percentage of less than 0.50 percent is recommended for good-quality VoIP. A fourth component of the MOS, the codec, is usually a fixed parameter per call—so it is not measured in real time. Chapter 2, "Building a Business Case for VoIP," includes a table that shows standard quality impairments for each codec. There is no need to spell out separate SLA metrics for each of these measurements; the call-quality portion of your SLA should simply specify the MOS. However, you may choose to set up monitoring thresholds for these metrics, to trigger early warnings that quality is declining. For example, you may set a threshold that is crossed whenever end-to-end delay rises above 150 ms. Although the measured MOS may not yet have declined, a delay above 150 ms signals a potential reduction in call quality. Incident Tracking If any of the availability, call-setup, or call-quality SLA metrics decline, you will want to determine why. Whenever an SLA metric deteriorates and crosses a threshold, the incident-tracking metrics come into play. Incidents often occur because of an outage or severe degradation that requires repairs. Scheduled changes and ongoing maintenance are also tracked as incidents. Several metrics are usually part of an SLA to deal solely with incident tracking: -
Mean time to repair (MTTR)— When an SLA value is violated, how long does it take for the provider to fix a problem, make an upgrade, or perform required maintenance? The time it takes to resolve each incident is averaged to get the MTTR. The MTTR is probably the most common SLA metric that deals with incident tracking. For this metric, lower numbers are better. -
Mean time between failures (MTBF)— Do failures occur frequently or only rarely? This metric defines the average time between failure incidents. The MTBF gives an indication of how often failures are occurring and can help identify potential availability problems. Proper monitoring of the MTBF also can inform you if failures are starting to occur more often. For this metric, higher numbers are better. When tracking downtime or low call quality, set thresholds proportional to the SLA metrics and configure events or alerts to be sent when these thresholds are crossed. Tie the events into your fault-management and event-response systems. Early warnings may prevent SLA violations for the crucial VoIP network metrics and help you to avoid triggering violations of incident-tracking metrics. A good VoIP SLA should include incident-tracking metrics to give you an expectation for how rapidly your service provider will respond when service levels are not being met. In turn, incident-tracking metrics help to guarantee the high availability, call-setup performance, and call quality already specified in the SLA. |