Replication
|
| < Day Day Up > |
|
You may decide to duplicate a part of the directory or the whole directory on two or more other directory servers. This action of duplicating the directory is called "replication." The LDAP literature uses the terms "consumer" and "supplier." These expressions come in handy when describing the data flow. The server that sends the data is called the supplier. The server that receives the data from the supplier is called the consumer. These roles are not exclusive. The consumer server can be a supplier server for other servers, as we will see in the next section, "replication scenarios."
Furthermore, there are master servers and slave servers. The slave server runs in a read-only mode, getting its data from a master. The clients, therefore, cannot update the data on a slave server. Only the master server can modify data on the slave server, whose only function is to serve clients for search operations. Of course, the master server can also modify the data in the directory it contains. A directory application can have more than one master. However, the so-called multimaster replication is more difficult to implement. In this first section we will speak about master-slave replication only. In the section on multimaster replication, we will have a look at what is different in a configuration with more than one master directory server.
Replication has a number of advantages. It can improve:
-
Availability: Upon the failure of one server, another can continue to provide information to the clients.
-
Performance: Distribution of the workload among multiple servers increases efficiency by dividing the type of work each one performs. For example, you could have one server dedicated to data updates and another for data retrieval.
-
Bandwidth: Efficient configuration increases bandwidth. Most enterprises have a large geographical extension and thus a geographically extended WAN. In this situation, it may be convenient to bring the directory closer to the clients by putting a directory server on every LAN and keeping these directory servers synchronized. The main advantage is a gain in bandwidth that you can use for other applications.
-
Maintenance: Organizations that span multiple time zones must always have an active server. If each time zone has its own directory server, directory servers that are not being used can be safely taken offline. If you offer 24/7 service, you can take a server offline for maintenance as long as there are enough servers to respond to client requests. As mentioned before, a master-slave pair can also be used for offline backup. While the offline backup of the slave is active, the master continues its work. Once the backup is finished, you can put the slave online again.
Note, however, that there are no formal standards for replication or for a replication protocol at the time of this writing. Work is under way, and the workgroup is now releasing an important milestone of its work, but it will still take some time to create a standard. You can monitor the state of the art at the Web site of IETF (http://www.ietf.org). We will discuss this in greater detail in the section called "Work in Progress." The lack of a standard combined with vendors' desire to meet the needs of the market has led to the current situation where every LDAP implementation has it own replication solution.
Let us see how OpenLDAP is implementing replication. In Appendix D you will find a detailed discussion of the configuration of OpenLDAP for replication. You have to configure one server as master and one server as slave. The master server maintains a replication log. This log describes the changes to the directory the master server has applied. The slave server has to be configured to accept modifications of the master server. OpenLDAP delivers a replication server that does nothing else but communicate to the slave server the changes in the directory the master server has applied. Replication server and master server are two different programs. If I want to be precise, I should have stated the following: the slave server has to be configured to accept modifications from the replication server. That's enough, however, for the sake of this example. More in Appendix D.
Previously I said that ever vendor has its own solution for replication, and these single solutions, unfortunately, are not compatible with each other, so you cannot set up a replication between directory servers of different suppliers.
You can replicate the whole directory or one part of the directory, and you can replicate one server to more servers. There are a number of possibilities for implementing replication, and you can also combine these implementations. You can even combine replication with partitioning. We will address these subjects in Chapter 9, where we consider design questions.
However, bear in mind that not all implementations support all of the features that we have mentioned. It is best to check the documentation of the various LDAP implementations while you are still in the planning phase. Of course, most users are not in the fortunate position of choosing their LDAP software based on its replication options. In most cases, replication does not become an issue until the directory services system is successfully deployed and the workload increases. At this point you have to live with the options that your implementation offers. The reason for underestimating the workload is simple. When the directory services are up and running, more and more application programmers will use them. The real use of directory services is typically far greater than expected. We will address this issue later. For now, we will have a look at the different replication scenarios.
Replication Scenarios
In this section, we will briefly look at a few of the possible replication scenarios. We will return to this topic in Chapter 9, when we examine the design of directory services.
Exhibit 11 depicts the most basic scenario: a simple master-slave replication. The master server A replicates to the slave server B. The replication in this case has the goal of increasing the availability of directory services. If server A is down, then the clients can use still directory services through server B.
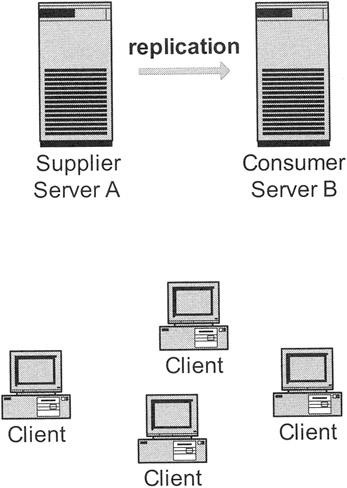
Exhibit 11: Simple Master-Slave Replication
Exhibit 12 shows a different scenario. We still have master-slave replication, but the main scope here is to make the data available in a different subnet. If the connection between the two networks is down, the clients on the location of either the slave or the master still have directory information, although the information on the slave side may be out of date. The main advantage in this configuration, however, is that the traffic on the network link caused by the directory servers is kept as low as possible. Server A sends only the data that has been modified to server B. Both sites use their own directory server. The network link is used only for replication updates. The bandwidth that otherwise would be used by the clients is now available for use by other applications. Both sites can continue to use the directory, even if one of the servers is unavailable, because in this case its replication partner takes over its workload.
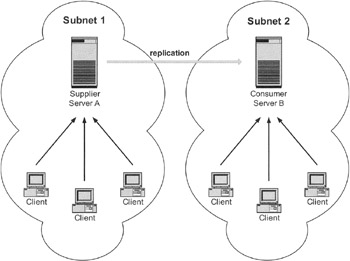
Exhibit 12: Simple Master-Slave Replication between Subnets
Exhibit 13 shows an example of a cascading replication, where the replicated server replicates furthermore on a second slave server. Not all directory server implementations support this architecture. In the case of OpenLDAP, where you have a dedicated consumer server, a cascading architecture would not be possible.
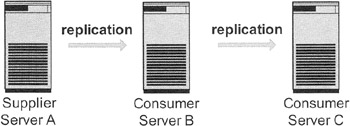
Exhibit 13: Cascading Replication
Exhibit 14 depicts a somewhat more complex configuration. The master server holds the database, and all changes (insert, modify, delete operations) are made on this server. There are four consumer servers, each serving one subnet. These four servers can be put much closer to the clients they are serving than the master server. The master replication server in this configuration has two functions. First, it speaks with the clients requesting a directory update. Then it distributes these updates to the single consumer servers.
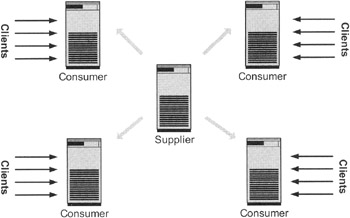
Exhibit 14: Supplier Server with Several Consumer Servers in Different Subnets
Performance can be improved even more by putting a further replicating server between the master replication server and the slaves, working practically as a hub. In this configuration, the supplier server leaves the distribution of the updates to the hub and concentrates on its job as LDAP server. It receives the messages from the clients and executes the necessary steps on the directory.
Schema Information and ACL
In LDAP (v3), schema information should be held in the form of a subschemaSubentry object. Some implementations use this mechanism to propagate changes in the schema from the supplier to the consumer. Because the exact syntax for the representation of the schema in the subschemaSubentry is not yet defined in a standard, every supplier uses its own. Thus it is best to have a common schema for both the supplier and consumer and to avoid changing the schema.
Since there is no standard defining access control lists (ACLs), some directory server implementations hold the ACL in the configuration files, and others keep it where the data is, in the directory. When the ACL is part of the directory, updates in the ACL can be propagated through replication.
Work is under way to define a standard for both mechanisms. A major goal of this effort is to allow directory servers from different suppliers to exchange information. Once these standards are defined, it will still take some time until the first suppliers implement the standards.
Single Master versus Multimaster
Until now we have seen only configurations featuring a single master server. Updates of the directory are made on the master server, which replicates them on the slaves or slave. In all these cases, the access is to slave servers running in read-only mode, which means that they cannot modify any entry. The only one who can do this is the master server. However, this does not mean that a client connected to the slave server cannot modify an entry. Indeed, the client can ask the slave server to update or delete an entry, and the request is handled like a referral. Upon the request to the slave server, the client receives from the slave server the location of the master server and its IP number. With this information, the client submits its request to update information to the master server. Normally, the client software handles this automatically, and the transaction is hidden from the user. Alternatively, the update request could also be handled using chaining. The client asks the slave server to update an entry. The slave server asks the master server to make the update. After the master server sends the return code in the form of a message object, the slave server informs the client.
There are also situations where you may wish to have more than one master server. In this case of multimaster replication, more than one directory server has write access to the directory. This obviously complicates the situation. Clients in such an architecture can submit update requests to any of these master servers. If in a master-slave solution the master is no longer available, you can read the directory, but you cannot update it anymore. Whether this is acceptable depends on the particular application. If you have two masters, though, you continue to work both in read and update, even if one of the masters is not available. As soon as the disabled master becomes available again, it will be updated.
This solution has its advantages, but it also introduces a big problem. If more than one server accepts updates from the clients, the same entry can be updated on two different servers. An entry might be updated with one value on server A and another value on server B. Exhibit 15 depicts such a situation. The server software has to have some sort of policy to resolve such conflicts. The servers could use the time stamp of the update action to decide which update to keep and which one to discard. Using Exhibit 15, imagine that a client in the United States updates the room number to 512 at 4:01 p.m. and one minute later a client in the United Kingdom updates the room number to 528. Most directory servers keep the most recent update and discard the previous one. This obviously requires that the time between the servers is perfectly synchronized. Note, however, that there is no correct way to handle this situation because, for the directory server, no client's update is better or worse than the other.
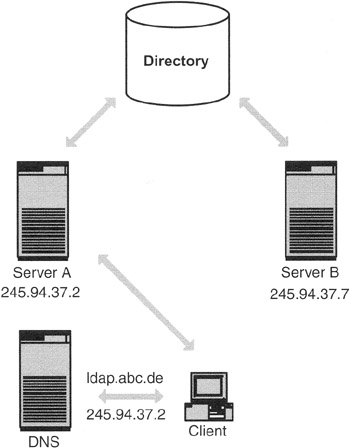
Exhibit 15: Two Servers Sharing One Directory
Again, how these details are handled depends on the implementation because there is no standard yet. Check the documentation shipped with your software. Given the lack of a standard, it is clear that replication cannot be implemented between software from different suppliers. It is not only the multimaster replication that does not work between products of different suppliers. It is the replication protocol between the directory servers that has not yet been standardized.
Exhibit 15 shows a very interesting scenario of replication. This architecture is particularly interesting because it is a thing between multimaster and single-master replication. Two directory servers (server A and server B) share a common directory. The goal is that if server A is unavailable, server B can continue its work. Because both directory servers use a common directory, you need not replicate it to keep both servers aligned. If the client wants to connect with the directory server, it gets the IP number from the DNS and then connects with the directory server. If server A should answer, the DNS gives the address of server A. If server B should answer, the DNS gives the address of server B. The switch from server A to server B is therefore achieved by the DNS server that resolves the names. Let me make the example clearer. The client asks the address ldap.abc.de from the DNS server. If we want server A to respond, the DNS says to the client: "Look, the address of ldap.abc.de is 245.94.37.2." If we want server B to respond, we tell to the client: "The address of ldap.abc.de is 245.94.37.7."
Replication Agreements
Once the architecture is established, replication still has to be set up to work properly. You set up replication by defining a handful of agreements between supplier and consumer servers. These are the arguments the server has to agree upon:
-
Supplier- or consumer-initiated replication
-
Frequency of replication
-
Unit of replication
-
Incremental or total replication
-
Replication account
We will have a brief look at each of these points. Please keep in mind, however, that each directory server handles replication in a different manner, so some points may be just configured and you cannot change them. Refer to the documentation delivered with your directory server.
Supplier- or Consumer-Initiated Replication
This describes which of the partners initiates the replication. In a supplier-initiated replication the supplier contacts the consumer and pushes all the data changed since the last replication to the consumer. In a consumer-initiated replication, the consumer contacts the supplier and pulls down all data changed since the last replication. The end result for both replication types is the same. The choice of which to use depends on the particular architecture. The supplier-initiated replication can push an update to the consumer as soon as the data in the supplier changes, thus minimizing the delay between the update of supplier and consumer. Using this strategy, the consistency between supplier and consumer is strong. The consumer-initiated replication is used when the connection to the consumer is not very stable, for example in a dial-up connection. When the consumer connects to the LAN, it can request the supplier to begin the replication.
Frequency of Replication
The frequency of replication depends on the degree of consistency required between consumer and supplier. As the divergence between consumer and supplier becomes more critical, replication should occur more frequently. However, the more frequently the server is busy with replication, the greater is the loss of performance against connections to the clients.
Unit of Replication
You can also decide which part of the DIT you will replicate. Some implementations only allow you to replicate the whole directory.
Incremental or Total Replication
This defines whether you replicate the whole directory or just the part that has actually changed. Total replication is used when you set up replication for the first time or if you reload the entire directory on the supplier. For normal operation, you will normally use incremental replication between supplier and consumer.
Replication Account
You must define an account that the supplier and the consumer can use for the replication process. The replication account must have sufficient rights to achieve the operation on the partner server.
Load Sharing
Replication has different objectives, one of which is load sharing. We have already seen two possible methods of load sharing. The first possibility is to use two or more directory servers and distribute accesses to these directory servers via DNS. The client asks for the directory server "directory.Ldap_Abc.org." The DNS server gives an IP number, and the client then contacts the directory server with this IP number. When the next request arrives at the DNS, it delivers another IP number. Thus, the requests are distributed among all directory servers. Exhibit 16 shows this architecture. The disadvantage of this architecture is that the DNS does not speak LDAP and therefore does not understand if one of the LDAP servers does not answer. Furthermore, the distribution among the directory servers is not guided by the nature of the requests.
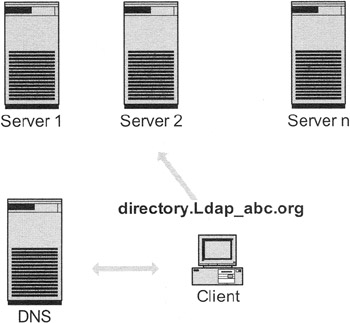
Exhibit 16: LDAP Load Balancing Using DNS
Another possibility is to use a gateway, as noted in the previous section on "replication scenarios." Every directory server in this schema is specialized on a particular activity. Exhibit 17 shows the architecture. One or more supplier servers accept all the data maintenance operations. Remember that data maintenance operations are more resource consuming than read operations. The supplier pushes the changes onto the gateway, which distributes the data to the consumer servers. The consumer servers, in turn, handle the read operations for the clients.
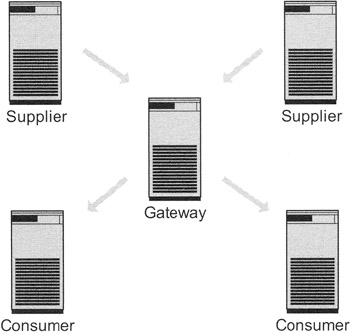
Exhibit 17: LDAP Gateway
A last possibility is to use an LDAP proxy server, as shown in Exhibit 18. Because the proxy server speaks LDAP, it understands the requests made by the clients. Therefore, the LDAP proxy can decide on a configurable and "intelligent" way to distribute the requests. It can furthermore decide to hide certain attributes from the client or to put together two data sources and make them appear as a unique data source to the client. Most of the commercial vendors also offer an LDAP proxy server. However, this is a very expensive solution. Fortunately, the OpenLDAP implementation can be compiled to work as a proxy server. We previously mentioned the need to compile OpenLDAP in a particular way to get it work as a proxy. Chapter 7, "LDAP Directory Server Administration," provides more information about the installation of LDAP, and Appendix D tells you how to compile and configure the OpenLDAP proxy server.
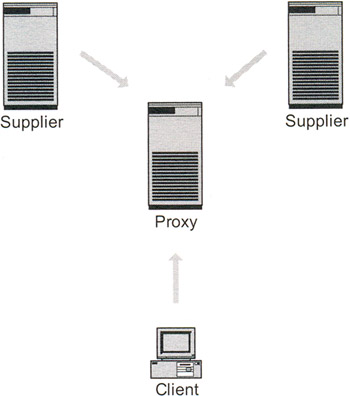
Exhibit 18: LDAP Proxy
Security Aspects
The security considerations for the conversation between a consumer and supplier server are the same as for a conversation between a client and server. Most server implementations offer a variety of options to secure this conversation. Your choice of method depends on your particular requirements.
In an insecure environment like the Internet, it is very important that both the supplier and the consumer servers are sure about the identity of the partner. However, even in an intranet environment, security issues should be a concern. Many intranet administrators assume that the "bad guys" are outside the network. Unfortunately, experience has shown that "bad guys" could also be inside the system.
As mentioned before, directory servers can exchange schema information and ACLs. In a so-called man-in-the-middle attack, this information can be forged if transmitted in the clear without encryption. Thus such information should be encrypted before transmission. The same holds true for user data. User data stored in the directory contains the users' passwords. When this information is transmitted between consumer and supplier servers, anyone listening on the network can capture it.
The available security options depend on the implementation you are using. Refer to the documentation delivered with your software to understand which options are appropriate for your application. Again, there is no standard, and every software vendor has a solution of its own. A number of suppliers offer an LDAP proxy. For example, Sun has one in its Sun One server suite that also includes an LDAP proxy server.
Work in Progress
The replication process, like much of LDAP, is a work in progress. A working group called LDUP (LDAP Duplication/Replication/Update Protocol) is in the process of standardizing master-slave (also called single-master) and multimaster replication. You can learn more about their work from the IETF Web site at http://www.ietf.org/html.charters/ldup-charter.html.
The following lists reflect the latest information drawn from the workgroup's Web site at the time of this writing. Given the time lag in publishing, you would be wise to refer to the Web site for recent updates. The LDUP working group has divided its activities into seven areas, each of which is documented by one or more papers:
-
LDAP (v3) replication architecture: Describes the overall architecture of the LDUP protocol, i.e., the LDUP components and how these components work together.
-
LDAP (v3) replication information model: Defines the schema information necessary for replication to work. It includes replication agreements, consistency models, replication topologies, management of deleted objects, and administration. This information has to be maintained by the replicating servers.
-
LDAP (v3) replication information transport protocol: Defines extended operations that allow LDAP itself to propagate the information to be replicated
-
LDAP (v3) mandatory replica management: Management protocol to administer replication.
-
LDAP (v3) update reconciliation procedures: Procedures for the detection and resolution of replication conflicts. Replication may try to update the same element from different information sources. These procedures should resolve conflicts.
-
LDAP (v3) profiles: LDAP (v3) replication architecture, information model, protocol extensions, and update reconciliation procedures
-
LDAP (v3) client update: Enables the client to synchronize with update in the LDAP server and receive notification about modifications in the database.
At the time of this writing, the work of the LDAP group has produced the following documentation:
-
RFC 3384, "LDAPv3 Replication Requirements"
-
"General Usage Profile for LDAPv3 Replication," draft available from http://www.ietf.org/internet-drafts/draft-ietf-ldup-usage-profile-03.txt
-
"LDAP Client Update Protocol," draft available from http://www.ietf.org/internet-drafts/draft-ietf-ldup-lcup-03.txt
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 149