Partitioning
|
| < Day Day Up > |
|
Partitioning is the action of dividing one large directory into two or more smaller and therefore more easily manageable pieces that combine to form a complete, logical unit. Once divided, the clients can continue accessing the directories as if they were on the same directory server. The ability to access the directories as one logical directory can be achieved through the use of referrals or by chaining.
We will see what partitioning is and learn how to partition a directory. In the introduction we learned about the benefits of partitioning. We will learn more about this in Chapter 9, which addresses the topics of planning and design of directory services. In this chapter, we will concentrate on the technical aspects of partitioning.
Once we have an understanding of partitioning, we will look at referrals. We will learn how to create a referral and understand what happens when the directory server sends back a referral. We will also see the different kinds of referrals.
We then move on to have a look at chaining and discuss the differences between referrals and chaining. Note, however, that chaining is not yet standardized, and therefore not all directory servers support chaining.
What Is Partitioning?
Let us consider a very basic situation, as shown in Exhibit 1. Our enterprise Ldap_abc.de has grown up and now it is ldap_abc.org. The org extension indicates a change in the organization's status, but that is not the point. The point for us is that the organization now spans more than one country, with each of these countries having a directory server of its own.
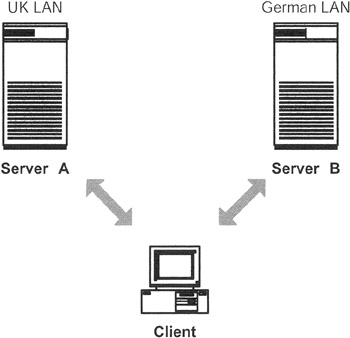
Exhibit 1: Partitioning of a Directory
For the moment, let us assume that besides the server in Germany, we now have a server in the United Kingdom, too. Exhibit 1 shows that we hold the German part of the directory on the German server, while the U.K. directory points to the U.K. server, managed completely in the United Kingdom. The main server is still in Germany and holds also the referral to the U.K. server. If a client asks for ou = UK, ldap_abc.de, it refers to the United Kingdom. I presume that users are more likely to use their own data, i.e., users in the United Kingdom are more likely to need the data held on the U.K. directory server, while users in Germany are more likely to use data held on the German directory server. But if a German user needs data from the U.K. directory server, she can access the data, if she is authorized to do so.
Partitioning also refers to a situation where a piece of the directory tree is removed and put on a different directory server. Exhibit 2 illustrates this more complicated example. This architecture has a number of advantages. Users on the LAN in the United Kingdom do not need to use the network link between the United Kingdom and Germany. This means better performance and greater availability. Should the network link between Germany and the United Kingdom be down, both sites still have access to their local data. On the other hand, if users on the U.K. LAN need access to the German data, they can still do so using the network link if the link is up and running. However, the clients in the United Kingdom have to be configured to use the U.K. server, and the clients in Germany to use the German server. Both directory servers will send a referral to the other server if they are unable to provide the requested information. The client then decides whether to follow the referral and try to contact the server holding the desired information. We previously said that the two directories build a complete logical unit, but this is not exactly the whole truth. Using referrals, clients notice very well that a piece of the directory is on another directory server. Thus it is more accurate to say that clients can navigate seamlessly in the directory spanned by the two directory servers.
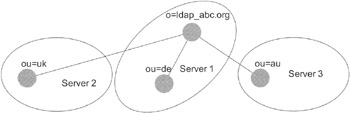
Exhibit 2: Directory Divided into Three Partitions
In the next example, we add a new organizational unit on a new server. Let us assume that we decide to locate all organizational units outside of the main server, which now has a simple dispatch function only. Exhibit 3 depicts this scenario. Using this setup, we can divide a large directory into a number of smaller partitions. Note, however, that each partition has to be a real directory tree. Exhibit 4 shows an invalid partition, where the two organizational units of the partition on server 2 do not have a common ancestor lying inside the partition. The directory on server 2 does not build a tree, and therefore the partition lying on server 2 is not a legal subtree of the root partition on server 0.
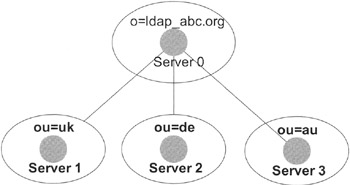
Exhibit 3: A Main Server with Three Organizational Units on Different Partitions
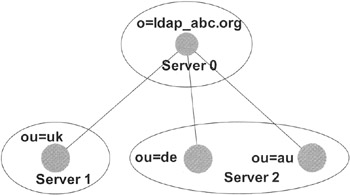
Exhibit 4: Example of an Illegal Partition
Exhibit 5 shows another example of an invalid partition. The partition on server 0 is illegal because the partition contains a hole. For example, there is no element between the object type "inetOrgPerson" with RDN uid = JParker and the organization "o = ldap_abc.org." To make the partition legal, we could move the organizational unit in the partition on Server 0 or move the person with RDN uid = JParker into the partition on server 1.
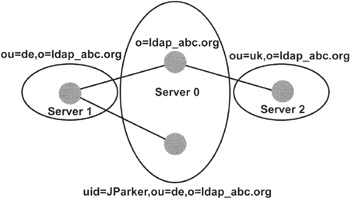
Exhibit 5: Example of Illegal Partition, Ancestor Missing
Gluing the Directories Together
Now assume we have partitioned our directory servers and want to get them up and running. However, there is still one point missing. Look again at Exhibit 3. How does directory server 0 know that the subtree "ou = de" is located on directory server 2? And how, in turn, does directory server 1 know that its ancestor is located on directory server 0?
These details are held in the "knowledge information." The "superior knowledge information" points to the directory server containing the ancestor of the current directory root. The "subordinate knowledge information" points from the ancestor to its child. Most directory server implementations hold this information in the root DSE (DSA specific entry). Recall that DSA is the name used in the X.500 protocol for the directory server (directory server agent).
Note that there is still no standardization. Work is under way, but you can learn more about the knowledge information and other questions about referrals in a draft report available from IETF (draft-ietf-asid-ldapv3-referral-xx.txt).
Referrals
This is the only concept in LDAP (v3) now defined as a standard by an RFC. If a client asks a directory server for an entry it does not contain, the server sends the referral information back. Its function is to tell the client that the desired entry is not available on this server and suggest where to find the desired information. The referral has the following structure:
-
The host name of the directory server
-
The port number of the directory server
-
The base DN of the new target. If omitted, the client tries the same DN it searched on this server.
There are two types of referrals: The smart referral implements the "subordinate knowledge information," and the "superior knowledge information" is implemented by the global referral. The referral that implements the subordinate information is sometimes identified in the literature as a "smart referral," and the global referral is simply called a "referral." In any case, the global referral refers to another directory server if the server you are querying does not have the requested information. In the case of a superior knowledge information, the referenced server does have this information and delivers it to the client. In this way, the directory server could be thought of as a kind of proxy server. All requests it is not able to resolve are forwarded to another directory server that may contain smart referrals to the directory server containing this information. The client has to express explicitly that it wishes to follow the referral. The analogy to the proxy server is, however, not to be considered strict. A proxy server works more as a chaining server than as a referral. The client using a proxy server has no idea that the one that actually holds the data and elaborates the query is not the proxy itself but another server.
Examples
Until now, the discussion may have been interesting, but an example will explain much more than an entire chapter of theory. So let us change our example slightly to see data distribution at work. This time, let us assume that we have a brand-new directory server installed in the United States. This directory server will be used to administer all information regarding the United States. Clients located in the United States will use this directory server, while clients located in Germany will use the German one. Exhibit 6 shows this scenario. In our example, one directory server is running on the standard port, and the other directory server is running on Port 700. This example is not presented to show that it is easy to listen at a nonstandard port. No, the objective is to allow you to try out this example even if you own only one server for test purposes.
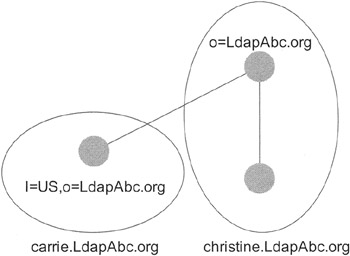
Exhibit 6: New Location in United States Will Need a New Directory Server
The machine called christine.LdapAbc.org is running the directory server with directory root:
"o=LdapAbc.org"
On this directory server, we will find the entire directory information tree except the subtree:
"1=US, o=LdapAbc.org."
On the server called "carrie.LdapAbc.org," we find the directory server containing information regarding the U.S. location. This directory server has the directory root entry:
"1=US, o=LdapAbc.org"
Once the two directory servers are configured and running, everything seems to work quite nicely. If we query Christine, it will report any data located on its directory server. If we query Carrie, its directory server will do the same. If we want to have information from Carrie regarding the search base:
"ou=IT, l=US, o=LdapAbc.org"
we will get a "no such object" message. If we ask Christine about entries not contained in the l = US subtree, the server cannot answer us.
First we will explain to the LDAP server mounted on Carrie how to retrieve the information in the l = US subtree. This we can achieve via the referral object. The next line shows our first attempt to find a Mister Seidl, working in the United States, on our directory server.
ldapsearch -b "o=LdapAbc.org" -h christine.LdapAbc.org "(&(l=US)(sn=Seidl))"
The server will not report any result. Then we add the referral that explains how to arrive at the subtree where Mister Seidl is located.
The distinct name of the referral is just the mount point between the two servers. The object class is "referral," which inherits from "extensibleObject." The last attribute in the referral entry is the LDAP URL where you can find the subtree. Now the search should work fine. But, as you note, we do not get the information. We get instead from the server a hint to look at the directory server
ldap://christine.LdapAbc.org/l=US, o=LdapAbc.org
using the distinct name:
l=US, o=LdapAbc.org
If we want to get all of the information in one step, we have to tell the client to follow automatically all referrals. With the command line we are using, it is enough to specify the -c flag.
So one part of our job is done. The client asking the central server for information on the U.S. site gets a referral or gets the data directly. If a person in the United States connects with the directory on her site now, she still gets "no such object." You have to tell the server Christine to contact the server Carrie if it does not contain the requested information, by setting up a global referral to the server Carrie. The specific command depends on the implementation of the directory server. In the OpenLDAP configuration file, all you have to do is to add this line:
referral ldap://Carrie.LdapAbc.org
to set up a global referral to the server Carrie.
And Now ... from the Client Point of View
Concluding the discussion about referrals, it is worthwhile to have a look at the previous example from the client point of view. We will use the example mentioned above.
The LDAP Server A with the root DN "o = LdapAbc.org" has the organizational unit ou = US. This entry in reality does not live on server A, but is a referral pointing to Server B with root DN "ou = US, o = LdapAbc.org." Since not everybody has two machines to test out the example, this exercise uses two LDAP servers listening on two different ports: one on the standard port and one on port 700. For this experiment, you should create a configuration file equal to server A, but with root DN ou = US, o = LdapAbc.org, and start it on port 700. Look at the documentation shipped with your directory server software to learn how to do that.
Furthermore, you should create some entries. I suggest creating the same entries as in server A, only with different root DN and different surnames/given names to test out queries on both servers. You have to configure two things:
-
The subordinate knowledge information on server A:
ref: ldap://127.0.0.1:700/ou=US,o=LdapAbc.org
-
The superior knowledge information on server B:
referral ldap://127.0.0.1
After configuring and restarting the server, we can try it out using the LDAP command-line tools as well as a Java program to test our implementation.
Let us first search an entry on the first server using the command-line tool. The entry with sn = Voglmaier resides on server A. The command shown in Exhibit 7 does the job. The response to our request gives the hint that there could be further information available using the reported URL. It is now the job of the client software to decide if it should follow the LDAP URL
ldapsearch -LLL -b "o=LdapAbc.org" -h localhost -p 389 "(sn=Voglmaier)" dn: uid=RVoglmaier,ou=IT,o=LdapAbc.org objectClass: top objectClass: person objectClass: organizationalPerson objectClass: inetOrgPerson cn: Reinhard Erich Voglmaier sn: Voglmaier givenName: Reinhard Erich ou: IT uid: RVoglmaier mail: RVoglmaier@LdapAbc.org # refldap://127.0.0.1:700/ou=US,o=LdapAbc.org??sub
Exhibit 7: Search Command to Find Entry on Server A— Its Output
ldapsearch -LLL -b "o=LdapAbc.org" -h localhost -p 700 "(sn=Voglmaier)"
or instead deliver the following result:
Referral (10) Referral: ldap://127.0.0.1/o=LdapAbc.org??sub
Again, we see the hint to have a look at the localhost that could contain further information.
The query:
ldapsearch -LLL -b "ou=US, o=LdapAbc.org" -h localhost -p 700"(sn=King)"
results in the output shown in Exhibit 8, which shows as the entry of Stephen King. Here the directory server knows that only itself has information about the base ou = US.
dn: uid=SKing,ou=Marketing,ou=US,o=LdapAbc.org objectClass: top objectClass: person objectClass: organizationalPerson objectClass: inetOrgPerson cn: Stephen King sn: King givenName: Stephen ou: Marketing uid: SKing mail: SKing@LdapAbc.org
Exhibit 8: Output from Search Command against Host B
ldapsearch -LLL -b "ou=US, o=LdapAbc.org" -h localhost -p 700"(sn=Voglmaier)"
The search for Voglmaier, which does not exist in ou = US, does not deliver anything because Voglmaier resides in Italy. Leave out "ou=US'' and you should get back the referral.
Exhibit 9 shows a brief program in Java that does the same thing.
1 import netscape.ldap.* ; 2 import java.util.* ; 3 4 /** 5 * Simple example of referral usage 6 */ 7 8 public class Referrall { 9 10 public static void main(String args[]) { 11 12 String name = args[0] ; 13 String baseDN = args[1] ; 14 String host = args[2] ; 15 int port = Integer.parseInt( args[3]); 16 17 int searchScope=LDAPConnection.SCOPE_SUB; 18 String searchFilter = "(sn=" + name + ")"; 19 String getAttrs[] = {"cn," "mail," "uid"}; 20 21 LDAPConnection ld = new LDAPConnection(); 22 23 try { 24 ld.connect(host,port); 25 ld.getSearchConstraints().setReferrals( true ); 26 LDAPSearchResults res = ld.search( baseDN, 27 searchScope, 28 searchFilter, 29 getAttrs, 30 false ); 31 while ( res.hasMoreElements() ) { 32 LDAPEntry Entry = null ; 33 Entry = (LDAPEntry) res.next(); 34 System.out.println("DN: " + Entry.getDN()) ; 35 } 36 ld.disconnect(); 37 } catch ( LDAPReferralException e) { 38 LDAPUrl refUrls[] = e.getURLs(); 39 for ( int i=0 ; i < refUrls.length; i++ ) { 40 System.out.println(refUrls[i].getUrl() ); 41 } 42 } catch ( LDAPException e ) { 43 System.out.println( e.toString() ); 44 } 45 46 } 47 } Exhibit 9: Java Program following Referrals
Chaining
Exhibit 10 shows the concept of chaining in action. The concept is nearly the same as for referrals. The objective of chaining is to keep the directories together in a logical unit.
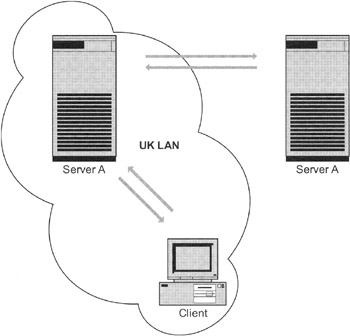
Exhibit 10: Chaining Client Requests
If a client in the United Kingdom wishes information located in Germany, it will first ask the directory server in the United Kingdom. The directory server checks to see if it contains the requested data. If it does not, it will search to identify the server that contains the information required. In the case of a referral, the directory server would send this information back to the client, which then decides whether to follow the referral or not. In the case of chaining, however, the server does not report anything to the client. Instead, it contacts the server it thinks contains the information on the behalf of the client. Once it has the information, the server sends it back to the client. In the meantime, the client waits.
In this case, too, the knowledge information is stored in the server. There is not yet a standard defining the chaining process, so check your vendor's documentation for guidance.
Security Aspects Using Chaining
Look again at Exhibit 10. The client contacts server A. Server A does not hold the information required by the client and therefore asks Server B, which does hold the information. Server B then sends the information to server A, and server A relays it back to the client. This is okay if the information exchanged is public. However, if the information can only be accessed upon previous authentication, things get slightly more complicated. In this case, when server A asks for the information from server B on behalf of the client, server A must also pass the user credentials to Server B.
Such an authentication scheme may be good enough for an intranet environment. In an insecure environment like the Internet, things get even more complicated. In this environment, the client must have assurance that server A really is server A and not an impostor running an LDAP server. This impostor could then steal the user's credentials and use them to gain access to the system. Thus when communicating over the Internet, it is absolutely necessary to use certificates to ensure that communicating parties really are who they claim to be.
Difference between Chaining and Referrals
Chaining and referrals are both used to contact another server if one server cannot provide an answer. However, referrals and chaining are two very different concepts as seen from the client's and the server's points of view. Using the referral strategy, the server simply sends a referral back to the client if it cannot execute the operation requested by the client. With the referral, the server also sends back a message identifying the server where the requested information resides. Thus the server acts nearly as it would upon receiving a request for data that it actually holds. The server does its job by informing the client, and then it is the client's job to handle the situation from there. In this case, the client has to do the work of interpreting the answer it got from the original server and then constructing the new address and distinguished name so that it can request the information from the new server identified in the referral. The client also has to decide whether to follow the request automatically or allow the user to decide what to do. In the case of a referral, the burden of work lies on the client and, consequently, on the client programmer.
In the case of chaining, the client knows nothing about these server transactions. Now the server has to do the work, and the vendor implementing the LDAP server has to invest much more work in the programming of the server software. In a chaining scheme, the originally contacted server handles all of the traffic from the final server holding the requested information as well as the directory client that made the request. Because a single request can result in more than one response, the original server may have to collect multiple responses and send them to the client. The client programmer has no direct control of the information flow between client, which is speaking with a kind of broker and not with the server itself.
A last difference between chaining and referrals lies in network performance. Obviously, performance is affected by the number of requests arriving at a server. If the server does not hold the requested information and thus must redirect the requests to other servers, the effect on performance is even greater. Because the client knows nothing about the chained transactions among the servers, it continues to send subsequent information to the original server, generating even more server-to-server transactions. Depending on the number of requests traveling this way and on the network architecture, this could have a negative effect on network performance. If the client is configured to recognize that the original server cannot execute the desired operation, it may be possible to switch its focus to the relevant server that can execute the requests directly. However, this feature is not available in all applications.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 149