Creating and Querying Views
| SQL Views have been around for some time, and if you've worked with any serious SQL engine, you've doubtless used Views to dereference complex queries. Of course, SQL Server implements Views according to the ANSI standards, but it also takes a number of big steps beyond those modest standards. Let's step through the "view" features you're most likely to use. T-SQL ViewsA T-SQL view is basically a query containing a SELECT that returns a single rowset from one or more tables or other viewsit can be considered to be a "virtual" table or (simple) stored query. No, when a View is referenced, the rows are not persisted any differently than when they're fetched with a SELECT. Once created, a View can be used in T-SQL syntax just as you would use a table. Why would one want to use a T-SQL View instead of just coding a SELECT? Well:
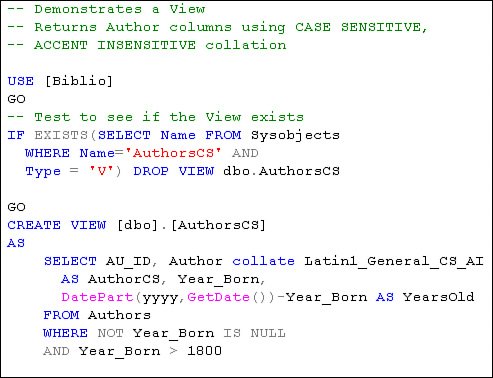
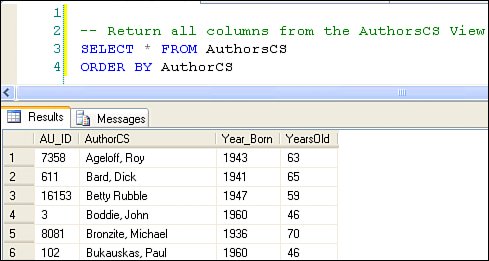
Creating ViewsVisual Studio and SQL Server Management Studio can both create Views using the Server Explorer and the Object Explorer (see Chapter 5 for details)however, Views are not "compiled" or stored anywhere except in the system catalogs (as T-SQL). When referenced, the query optimizer simply uses the View definition as a compiler would insert macro code, so they have no impact on performanceother than developer performance. IMHO A View is referenced in your T-SQL code just like any other table. In this case, it can make sense to use SELECT *. Let's step through some examples. I'm going to show you the T-SQL code used to create a View, as the Visual Studio IDE tool to do the job is very intuitive. In the example shown in Figure 2.51, I start by testing to see if the View is already defined. This is accomplished by executing a SELECT against the system object catalog (sysobjects). If the View exists, I execute a DROP VIEW to remove it from the catalogs. Sure, you can use an ALTER view to change an existing VIEW, but this script syntax is typical of what you see when DBAs set up scripts to rebuild the database from scratch. Figure 2.51. Creating a TSQL View. Next, I create the T-SQL View. This view returns selected columns from the Authors table, including an expression-generated column. The expression computes the author's age and returns the value as a column named "YearsOld". The View's WHERE clause restricts the rows returned by filtering out authors without a stated Year_Born or whose age is beyond reason. This filters out irrelevant and test data. The View also resets the default collating sequence so the rowset returned is set to a case-sensitive and non-accent-sensitive order. This means expressions executed against the columns returned will be case-sensitive. Note that a T-SQL View cannot include an ORDER BY clause, but it can include special collation instructions, as shown in Figure 2.51. There is nothing to stop you from sorting the data in the SELECT statement that returns the rows, as shown in Figure 2.52. Figure 2.52. Accessing a View with a SELECT statement. If the View returns a lot of rows you might get better performance by applying an Index on the View. This was new for SQL Server 2000, so you might already be aware of this feature. However, be sure to consult BOL[20] before attempting to set up an indexed viewthere are a number of limitations that you should consider before wasting a lot of time. For example, an indexed View definition cannot contain:
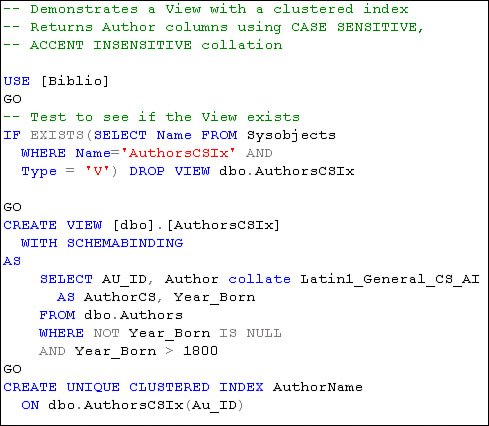
The example shown in Figure 2.53 shows the T-SQL code needed to create an index on a View. Notice that the View itself has been simplified. I had to remove the age expression. SQL Server forced me to create a UNIQUE CLUSTERED index on the Au_ID column, as it's the only unique column in the table. As the BOL documentation suggests, Indexed views won't help in all situationsas a matter of fact, it looks like their usefulness is fairly limited in scope. Figure 2.53. Creating a View and an index on the View. Database SnapshotsPeter and I are very excited (if that's the right word) about Database Snapshots. This new feature permits a developer (or DBA) to "snapshot" the database in time so that one can get a stable view of the database without the overhead of creating another parallel database. As the main database is changed, the Snapshot version keeps its own copy of the original pages as they are modified. This can be really handy if you need to recover from an accidental change simply by reapplying the original pages (stored in the Snapshot database) to the main database. We also think that this approach is interesting for reporting applications that need a "static" copy of the databaseagain, without the overhead of an entirely separate database against which you run your reports. |
EAN: 2147483647
Pages: 227