Creating SELECT Queries
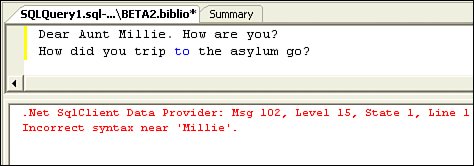
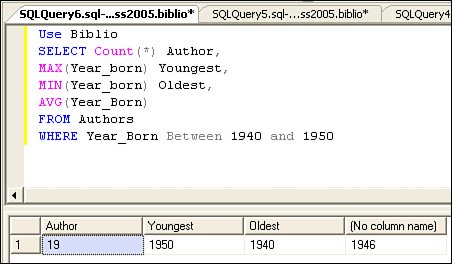
| Once a connection is established, SQL Server launches a process (identified by a process ID or PID) that permits the client application (through ADO.NET via TDS) to submit Structured Query Language (SQL) queriesthus the name "SQL Server". The TDS protocol does not care what kind of string ADO.NET sends as a "query"it's simply a transport mechanism. Sure, you could put a letter to your Aunt Mildred in the T-SQL string, if you're so inclined. When the server processes the TDS packet, it "compiles" the string as a T-SQL query. This process involves a simple syntax check followed by additional steps to ensure the objects referenced in the SQL actually exist and the connected user has sufficient rights to the objects. In other words, SQL Server checks to see if the database, tables, stored procedures, or other objects or elements you reference actually exist in the master or user database catalogs of objects and that the current user (the one that was permitted to open the connection) has been granted permission to "see" the objects referenced. If the T-SQL syntax check fails (and it should fail if you sent Aunt Millie's letter as a query, unless, of course, she expects a SQL queryin which case she needs counseling), a TDS packet is returned with details about the problems, and ADO.NET throws an exception with the details in the Exception Message property. These details can be pretty skimpy, as only the first layer of errors is returned. If you've worked with Query Analyzer, you've seen these syntax errors (as shown in Figure 2.28). Figure 2.28. SQL Server checks your SQL for syntax errors before executing it. Frankly, I've found that SQL Server Management Studio provides a better editor than Visual Studio for authoring SQL statementsthe error handling is more informative and complete. However, even SQL Server Management Studio does not always get the line numbers correct. That is, it sometimes gets confused by comments and ancillary commands. I'll show you how to edit SQL in both SQL Server Management Studio and Visual Studio in later chapters. If the syntax of your query is acceptable, the next phase of the query compile can also return exceptions if the objects your SQL references (databases, tables, columns, views, stored procedures, and so forth) don't exist or the connected user doesn't have permission to access them. These exceptions are passed back to ADO.NET via TDS, and your application (or Visual Studio) throws an exception. If the object references are valid, the query optimizer is executed to determine the optimal query plan, given the submitted TSQL. The SELECT statement is the SQL[14] operator you use to choose acceptable rows from a relational database based on criteria you include in the statement. While I don't really show you how to create SELECT statements in this book (there simply isn't room), consider that a simple SELECT statement (shown in Figure 2.29) specifies the table columns to return (Au_ID and Author) from a specified table (Authors) and returns a set of rows containing data from the specified table columns (if the condition specified in the WHERE clause is metin this case, rows where the Year_Born column value is between 1945 and 1947). The row(s) that results from any SQL query is called a "product" in SQL terms (in case you're asked this question on Jeopardy!).
Figure 2.29. A (very) simple SELECT statement. The SELECT statement usually specifies (and possibly names) the data table columns to be included in the rows to be returned. One option you'll see used very often when coding a SELECT statement is use of the "*" operator to indicate that all columns should be returned, as shown in Figure 2.30. Figure 2.30. Using the SELECT * option to return all columns Yes, this seems easy, but it's not a good idea to use unless you're writing table-management utilities. To make your applications perform better and provide explicit column referencing and fewer problems debugging later, I recommend that you explicitly specify each column you need to reference. One of the problems is that when you use SELECT *, you never know what is going to be returned by the query sometime in the future as the table schema matures. Someone could add a TEXT or IMAGE (what we call binary large object, or BLOB) column to the table, and your query could unknowingly pull back far more data than you need. You'll also discover that the Visual Studio tools now convert many SELECT * queries to return the specific columns by name. In any case, you must make sure that the column names you specify are unambiguous. That is, the query compiler (and your code) must know how to address the data from the source tables using unique column names. Because SQL Server won't let you create two columns with the same name in a single table, this is not an issue until you pull data from more than one column at a time using the JOIN syntax (which is discussed later in this chapter). To make the job of the compiler easier, each column in the database is addressed by four namesthe database name, the table owner's (or schema) name, the table name, and the column name. For example, to address the Price column in the Parts table, which is owned by Fred in the Pieces database, you would code: Pieces.Fred.Parts.Price in the SELECT statement. Sure, one can shorthand most of these names. First, you can usually leave off the database name because one can (should) set a default database (or initial catalog) when opening a connection. A connection points to a default database, but you can change it in code with ADO or add a USE <database> to your script. If you want to JOIN information from another database on the same server, you can include the database name in the query. It's also possible to include data from an external data source in your query using a Linked server. See BOL for more information on this technique. One can also (sometimes) assume that the currently logged-on user is the owner or has rights to the table, so you can leave off the table owner's name as well. You can also leave off the table name if you are fetching data from only one table or the name is unique in all of the tables referenced in the FROM clause.
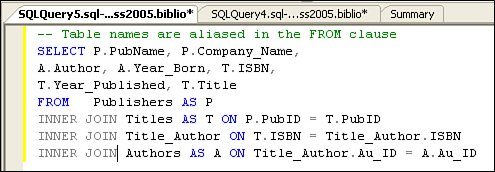
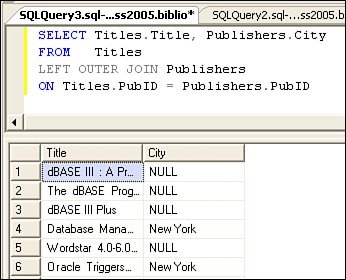
When folks migrate their code from Access/DAO/JET, they often find that the names assigned to their tables and columns don't seem to work. The problem is that if an object name has embedded spaces (as many Access examples include), the object needs to be framed in square brackets so that SQL Server's syntax validator understands how to parse the name. However, it makes a lot more sense to remove the embedded spaceseveryone will thank you later. For example, instead of naming an object "Production Parts", it would be better to use either "ProductionParts" (with CamelCase notation) or "Production_Parts" with an underscore character instead of the space. Using Aliases for Table and Column NamesOne technique I often use to shorten and simplify the T-SQL is to use an "alias" for the table name. This way I can use shorthand notation to refer to ambiguous column names. An example is shown in Figure 2.31. Actually, SQL Server does not require the AS clause, so you can alias a table name in the FROM clause simply by adding the alias after the table name. In this example, I alias the Publishers table as "P", the Authors table as "A", and the Titles table as "T". Figure 2.31. Using the AS clause to alias table names. In some cases, I want to rename the returned column, as when there are two columns with the same name in the SELECT. In this case, I can (should) return an alternate name for one or both columns. This is also useful when columns are generated by an expression, as shown in Figure 2.32. Note that if you don't provide an aliased name for the column (as I did for the AVG expression), SQL Server does not return any column name at all. This can confuse some of the tools. Figure 2.32. Aliasing columns in a TSQL query. Note that I forced the default database to "Biblio" by using the T-SQL USE operator. Note that USE changes the initial catalog/default database on the connection. This means that subsequent operations on this connection will use this new setting. This same rule applies whenever you use a SET statement (as I discuss later in this chapter). When the application (or connection pooling mechanism) closes or resets the connection, these settings are discarded and the connection is reverted to their initial settings. Walking Through the SELECT OperationIn the example shown in Figure 2.33, SQL Server is requested to find the name, city, state, zip code, and telephone number of any publisher whose zip code is between "90000" and "99000". Figure 2.33. Executing a simple SELECT statement.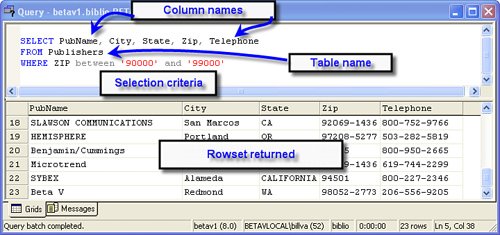 If any rows are found that meet the condition in the WHERE clause, SQL Server returns a resultset that contains:
Understanding the WHERE ClauseBasically, the T-SQL WHERE clause specifies the condition(s) that must be met to permit qualifying rows to be included in the rowset returned from your query. It's very important and should rarely be left out of a TSQL statement. The WHERE clause can:
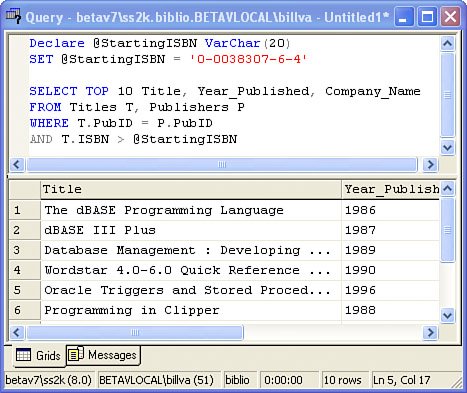
Using Parameters to Pass Literal ValuesEventually, you'll find that parameters play a pivotal role in T-SQL statements. Basically, they're placeholders for values supplied when the query is actually executed on SQL Server. When creating a parameter-driven SELECT query (or an UPDATE, DELETE, or INSERT statement), you replace specific values in the T-SQL with marked variables. No, you can't replace table, column, or other object names with parametersonly those values that can be expressed as literals can be parameterized. That's because the T-SQL compiler needs to resolve all object names at compile time. In T-SQL, parameter variable names are always prefixed with the "@" symbol. The value of the parameter can be set in code, as in Figure 2.34, or passed to SQL Server, as when executing a T-SQL procedure stored on the serverthese are called stored procedures, and I'll talk about them later in this chapter. The query parameter @StartingISBN, in Figure 2.34, is declared in T-SQL using the DECLARE statement (similar to a Visual Basic Dim statement). In this case, I use the SET statement to set its initial value, but it would generally be set by creating a Parameter object in ADO.NET and setting its value in your application instead of hard-coding the value. When ADO.NET is asked to execute the query, the Parameter Value is passed along to SQL Server to be inserted into the T-SQL as it executes. Sure, a query can have lots of parametersmost do. In Chapter 10, "Managing SqlCommand Objects," I'll discuss how to set up your ADO.NET code to handle all types of parameters, including input, output, input/output, and return value types.
Why is it bad to return lots of rows? Well, it's not reallynot all bad. If you plan to create a high-performance (or even reasonably well-performing application) or an application that scales, you'll want to limit the number of round-trips to the server, the amount of work the server has to do, and the number of rows that have to be sent to and from the server. These suggestions are only common sense. Sure, if you execute fewer queries, you'll have fewer round-tripsthat's good. However, if these queries take longer to execute or involve so many rows that the queries interfere with other application's resource demands and hog network resources moving the resultsets to your client, then it's bad. Consider that a sound design returns just the rows needed in the immediate to short-term future and fetches more only if needed. This approach means more round-trips but makes better use of the server and its resources. Limiting the Number of Rows ReturnedBefore I lose focus, remember I'm talking about ways to limit the number of rows returned from the server. Let's look at a number of other ways to limit the number of rows returned besides using a WHERE clause expression:
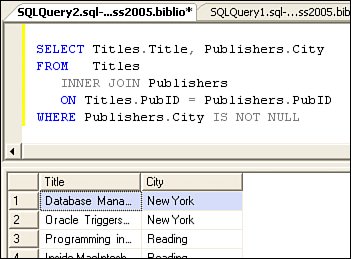
IMHO More rows are bad. Fewer rows are fast. Using the WHERE Clause to Perform JOINsWhen you need to return information from two or more tables, your T-SQL query must include WHERE-clause logic to identify the rows whose columns are to be included in the final rowsetthe product. This is called a "Join" operation. Typically, the tables being joined are "related". That is, they have primary key (the column[s] that uniquely identify a row) and foreign key relationships. For example, in the Biblio database, the Customers and Orders tables have a relationshipthere are 0 to N orders for each customer. This is called a "one-to-many" relationship. The Orders table refers back to the Customers table, with the CustID column as a foreign-key relationship. Figure 2.35 is a database diagram created by SQL Server Management Studio (or Visual Studio's Server Explorer) that illustrates the primary key and foreign key relationships between the aforementioned tables. When Visual Studio generates T-SQL queries for you, it uses these defined relationships to conger the correct JOIN syntax. Generally, you won't have to write your own JOIN clause, as that'll be done for you. But if you do want to do so, the best way to learn how is to inspect the queries that Visual Studio (or SQL Server Management Studio) creates for you. Figure 2.35. A database diagram illustrating the Customer, Order, Item, and Addresses relationships.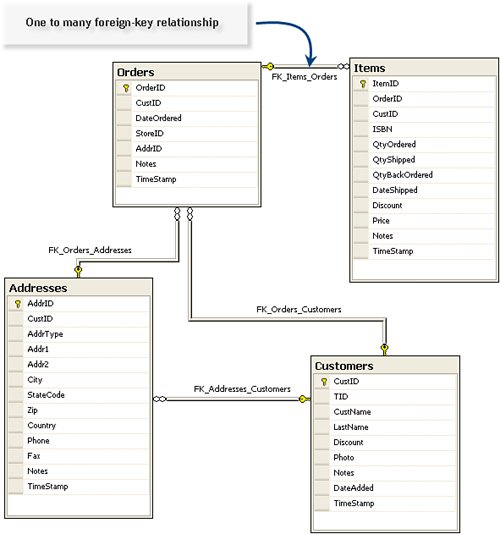 In the early days, I also used the WHERE clause to indicate how tables were to be joined relationally. This Code and Date technique was easy to teach but did not always work with other relational engines. For example, one could code a T-SQL query to relationally "join" the Titles and Publishers tables by simply cross-referencing the primary keys (as shown in Figure 2.36). Figure 2.36. Joining tables using a WHERE clause. No, this syntax is no longer in vogue, but it's still supported and works (and is optimized) just the same (in most cases) as a JOIN clause. Sometimes, it's easier for developers to "see" the join using this syntax, so it crops up from time to time. Essentially, a JOIN instructs SQL Server to collect information from two or more tables and combines the result (the "product") into a single rowset that's returned to ADO.NET. Be carefulif the JOIN is incorrectly coded, you might end up with a "Cartesian product," which contains all rows from one table combined with all rows from another. If you end up with 400,000 rows from a couple of smallish tables, that's likely what has happened. Coding TSQL JOIN SyntaxCoding a JOIN operation between two (hopefully) related tables defines how the SQL product (the rowset) is built by specifying which columns in the two tables being joined are "related." As I've said earlier, the two columns typically specify a foreign key from one table (the "left" table) and a primary key from another (the "right" table). Since SQL Server (and Visual Studio) adopted the SQL-92 syntax, we've encouraged code joins using the JOIN operator. Depending on how the JOIN logic is intended to work, you can code the JOIN in either the FROM clause (which specifies the tables to use in the query) or the WHERE clause (which limits the rows returned by the query). Joins are categorized as:
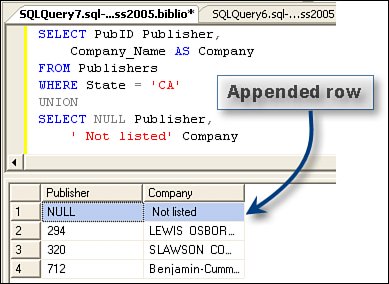
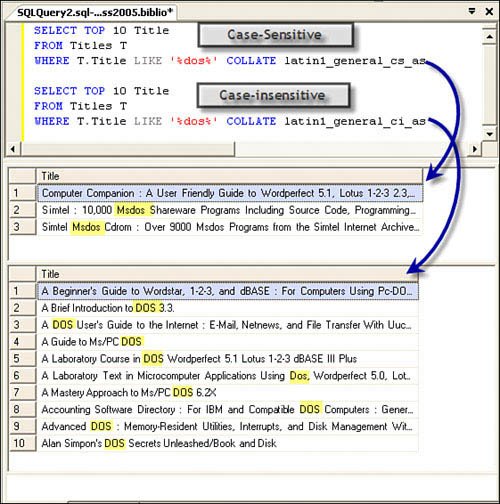
Coding a UNION QuerySuppose you have a situation where you need to return two or more rowsets from several tables in a single rowset. Sure, in most cases, a SELECT statement can join the tables, but when you simply want to return multiple rowsets as one, you can use the UNION statement. The UNION can append columns from expressions or literals as well. For example, when creating a pick-list query, it's useful to have the first row of the list show a "not selected" or NULL value without having to add code on the client to deal with it, as shown in Figure 2.39. Figure 2.39. Using the UNION statement to append data to a rowset. This technique is especially helpful when working with Reporting Services, as it does not accept more than one rowset. The only caveat here is that the datatypes for each column you append must match (to some extent) the datatype, and the number of columns must be the same as the columns in the original SELECT. Note that the columns in the resulting rowset are set by the first SELECT, so you might want to alias these (as shown in Figure 2.39). Ordering the Rows ReturnedWhen you use a SELECT statement to return rows from a data table, the rows are not returned in any particular order (that you can depend on). Even if a clustered index (which physically sorts the data rows as they are added) is defined for the table, SQL Server 2000 and later do not guarantee the order in which rows are returned. This is because SQL Server might perform "parallel" processing on your query and simultaneously extract qualifying rows from different parts of the table. To define (and guarantee) the order in which rows are returned, you must add an ORDER BY clause to the SELECT statementor accept the rows in pseudo-random order (however, SQL Server decides to return them). The ORDER BY clause permits you to specify one or any number of columns (or combinations of columns) to sort by in either ascending (ASC) or descending (DESC) order. In the example shown in Figure 2.40, the ORDER BY clause sorts the data based on the publisher's name (PubName), and since no direction is indicated, ascending is assumed. It also sorts on the author's name (ascending) and the year published (descending). Figure 2.40. Using the ORDER BY clause to order the returned rowset.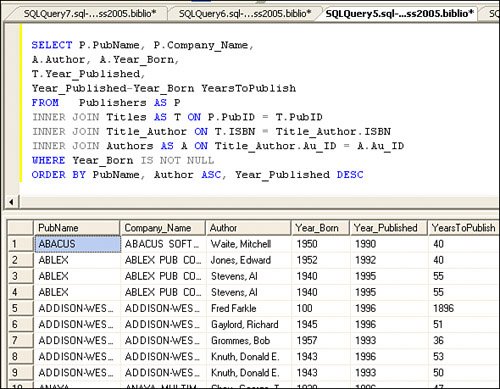 Note that this query also returns the results of an expression (Year_Published-Year_Born) and labels the column as "YearsToPublish". Yes, this is easy to do, but when you try to get Visual Studio to generate UPDATE statements for this rowset, it gets confused. When you install SQL Server, and again when you create a new database or column, you can define (using the COLLATE argument) how data is to be sorted by the ORDER BY statement. A collation defines the sort order to use for Unicode data (nchar, nvarchar, and ntext) and non-Unicode (char, varchar, text) data. The selected collation defines the order in which specific characters are stored and ordered when an ORDER BY expression is added to a SELECT or how expressions are evaluated. Generally, each (human) language defines specific collating ordersfor example, French, German, Thai, and English all have different collating orders for some (or most) characters. When the data arrives at the client, the Windows locale selected on the computer is used to determine character ordering. Dealing with Special-Case Query ProblemsMost of the documentation shows you how to write simple queries, and Visual Studio will even help you write most of these. The problem comes when you're asked to do something out of the ordinary. Well, based on my experience, these "special cases" seem to take up quite a bit of my time to figure out. Perhaps, these scenarios will help shorten the time it takes to solve a few of these for you. Managing Case-Sensitive QueriesFrom time to time, I've been asked to write queries to locate data (usually names) based on a case-sensitive expression. Don't confuse this query technique with "politically correct" or "person-sensitive" queriesthat's an entirely different kind of sensitivity. Case-sensitive queries differentiate between strings in UPPER- and lowercase. Suppose you want to find books whose titles contain the letters "DOS", but you don't want to include titles on "Pcdos" or titles about Mexican beer. Yes, this is a bit contrived, but in situations where you need a case-sensitive search, you might find it tough to find rows based on the character case. Consider that when you install SQL Server, you have a choice of what collating sequence to use for all databases in the server. I discussed this option earlier in this chapter. Generally, when I install SQL Server, I don't configure it to be case-sensitive because if I do, each and every T-SQL query I and every other developer writes must match the required case of the T-SQL operators in addition to all database object names, including the database, table, column, view, rule, trigger, stored procedure, and every other object in the database. This means you would have to code: SELECT MyCol FROM MyTable instead of: select mycol from myTable In a non-case-sensitive installation, either query would compile and work the same way. I've had to troubleshoot sites that chose to install a case-sensitive server, and I can tell you it's a royal PIA to deal with (and that's not a primary interop assembly). Every example the customer tries seems to have syntax problems. Sure, most of the tools are careful about how T-SQL is generated, so they use the correct case and I try to adhere to these standards in my books, but it's tough to do sowe're only human. It's not surprising that many sites insist on non-case-sensitive installations and don't send flowers to DBAs that insist on it. Fortunately, SQL Server 2005 and more recent versions permit you to specify case-sensitivity and other collation criteria as properties of the database, table, column, and querysettings that over-ride the server default. This way, you can code your T-SQL to specifically indicate how the server is to compare the values in any given expression, even though the server is set to not be case-sensitive. For example, you can specify several different attributes using a collation string.
Sometimes, you can help SQL Server resolve the query, and you won't need to write a query that specifies a special collating sequence. Let's walk through some approaches to managing case-sensitive queries.
This approach can be used only for any char, varchar, text, and the equivalent Unicode types. That makes sense, as you shouldn't really care about the case of numeric values. The COLLATE clause is not needed if you apply collating rules to individual columns when the database object (like a table column) is first created or when you execute a query against the data. Framing Dates and LiteralsWhenever a T-SQL query includes a string literal, it has to be enclosed in single quotes, as shown in Figure 2.41, where I frame the literal 'HITCH%' in single quotes. I refer to these as "string framing" quotes. If you use an ADO.NET Parameter object to manage your query parameters, the framing quotes are handled for you automatically. One of the most common problems with framing quotes is called the "O'Malley" issue because it crops up when you have Irish or other surnames or other strings that include single quotes. There are several ways to deal with the O'Malley issue. One way is to remove all of the offending names from the database. This has been tried at various times in history with limited success. Another (more acceptable) way is to let ADO.NET handle it for you by using Parameter objects to manage strings passed into SQL queries. If you must code your T-SQL hard-coded queries, you'll have to make sure that any strings that include (or could include) single quotes are handled a bit differently. To pass a single quote inside a string destined to be sent to SQL Server, you need to double the single quote. For example, "O'Malley" becomes "O''Malley". Yes, that's two single quotes, not a single double quote. Confused? Well, remember that it's best to let ADO.NET handle these issues for you. Note that dates also require special handling. SQL Server also frames dates with "#" characters or single quotes. Dates can be passed in a variety of formats, as SQL Server is smart enough to parse them (more or less) correctlyas long as you take them out of the husk and express them in U.S. format (mm/dd/yyyy). Yes, in the U.S., we use month, day, year notation (which is admittedly pretty strange to data processing types who like data to be stored in a more orderly fashion). In most of the rest of the world, other sequences are used, but SQL Server always stores dates in U.S. format. When you test for a date (as shown in Figure 2.43), if you don't strip off the "time" part of the date, it's tough to get an equality expression (X = Y) to work. That's why I either strip off the critical parts or use a BETWEEN expression to search for an acceptable range of dates. Figure 2.43. Framing a date passed as a string literal.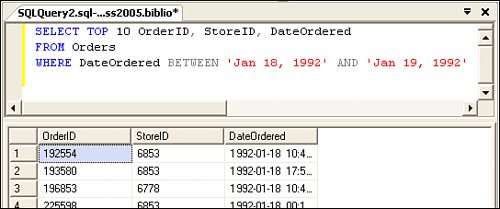 As with single quotes, if you need to include special characters (like double quotes, arithmetic operators, and other special characters) in your string literals, you'll need to double them up to get the T-SQL syntax parser to accept them.
Before you try to perform date arithmetic, be sure to check out the "date" functions in T-SQL. There are functions to add, compare, parse, and assemble dates. See DATEADD, DATEDIFF, DATENAME, DATEPART, and the other date functions for more information. Sadly, there are no date functions available to help some of you single folks find someone to go out with on Friday night. Concatenating T-SQL ExpressionsOne technique you're going to see in a number of online examples is concatenated T-SQL. For example, when you want to create a complex query but haven't learned how to use the Command object's Parameters collection to manage query parameters, you'll likely try to simply concatenate the arguments together. This is not that terrible, as long as the values are all machine-generated, as shown in Figure 2.44. Figure 2.44. Creating a concatenated TSQL query. First, you should learn to avoid use of the concatenation "&" operator in Visual Basic (the "+" in C#). It's extremely inefficient. Peter hooked me on the String.Format function some time ago, and I've pretty much converted my concatenation code to use it almost exclusively. With this conversion, the statement now looks like Figure 2.45. Figure 2.45. Using String.Format to concatenate TSQL strings. Okay, this is certainly not a big change. However, what if you want to pass in the value from a TextBox or other UI control? What impact does this have? Well, you might be tempted to simply substitute the TextBox.Value for the hard-coded value (1947)something like Figure 2.46. Figure 2.46. Concatenating from a user control. Notice that I even cast the Text value to an integer, even though the String.Format would have handled that conversion for me. So what's wrong with this approach? It seems clean enough. The problem is that it opens your application to a "SQL injection" attack. No, I'm not going to show you how to hack into a site that uses this approach. Suffice it to say that it's really easy to do and it's documented all over the Internet. Let's take this exercise one step further and add T-SQL to the WHERE clause to filter for a specific Author by name. Take a look at Figure 2.47. Figure 2.47. Using a string parameter in a WHERE clausewithout a parameter. In this case, we add another argument to the String.Format expression and fill it with the value from a string captured from another TextBox. In this case, your application will workright up to the point that someone tries to find Mr. George O'Malley. Remember that issue I discussed when talking about framing? Notice that the String.Format expression includes single framing quotes, but that does not correct the problem of a string being concatenated that includes a single quote. When I get to Chapter 10, I'll revisit how to build a Command object with a Parameters collection that can handle both issueswithout additional code. Coding WHERE-Clause LIKE ExpressionsMany application scenarios need to return rows based on an expression that helps locate rows in the table based on a "soft" string comparison. Since SQL Server was "born" in and around Berkley, California, you can imagine how the developers were accustomed to hearing and using the word "like" while describing like something, or like anything. Anyone with teenage sons or daughters in the last two decades can attest to the popularity of this manner of speechespecially on the West Coast of the U.S. In a single half-hour car trip, a teen could, like, use the word "like", like, a thousand timeslike, okay? I used a LIKE expression in Figure 2.42 to locate titles that contained the characters "dos". Suppose you need to locate all rows in a table where the city name starts with the string "San". This would return "San Francisco", and half the cities and hamlets in the Southwest U.S. would qualify. You can use a LIKE expression (WHERE City LIKE 'San%') to implement a query whose WHERE clause filters in this manner. Note that in T-SQL, the "%" is the wildcard operator[18]. If you place the wildcard character at the end of the LIKE expression, SQL Server can usually leverage an available index to locate the rows (in this case, I would need an index on the City column). However, if you code your LIKE expression to find the string anywhere in the column (WHERE City LIKE '%San%'), the server usually has to search the entire tableit can't effectively use the table's index.
There are a bevy of options available to you when you use the LIKE expression, as shown in Table 2.2.
Sure, you can pass the LIKE expression to a query as a parameter. As I'll discuss in Chapter 10, you can build an ADO.NET Parameter object to accept the LIKE expression as a string (including the wildcard characters). ADO.NET handles the framing quotes for you. Coding IN ExpressionsAnother powerful way to focus your query on the desired rowset is to use the IN expressions. This operator permits you to specify a fixed set of values to test against at runtime. Yes, this set can point to a table, a function, or a literal string. The syntax is fairly simple (as shown in Figure 2.48). In the example, the first query uses a fixed set of values. No, these values cannot be provided with a parameterthey must be available when the query is compiled. In the second example, I use a SELECT statement to return the list of acceptable values. Yes, the list of IN clause items can be a stringin this case, I provided a couple of date strings. Figure 2.48. Examples of IN expressions.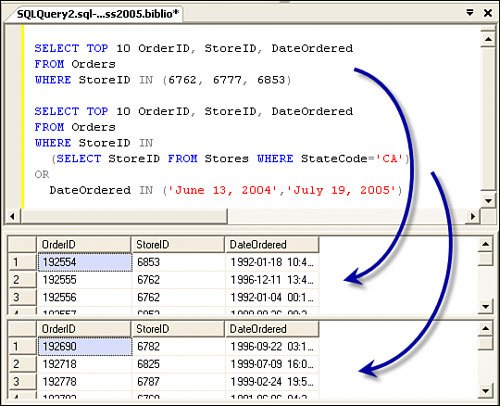
No, the IN, LIKE, and BETWEEN operators don't have to be capitalized, as I (try to) showunless you've configured a case-sensitive database (please don't). One other point about IN expressions that needs to be mentioned before I move on: No, you can't pass a parameter to the IN expression. That is, if you wanted to let your application choose the available IN expression values (as the set of dates passed to the IN expression in Figure 2.48), you could not pass them as a query parameterthey must be hard-coded when the routine is compiled by SQL Server. I discuss a way to get around this issue in Chapter 14, "Creating and Managing Reports," by creating a T-SQL (and CLR) function to convert a parameter containing a delimited string to a table that can be consumed by the IN expression. Coding TSQL BETWEEN ExpressionsWhen you need to test for a range of values, you can use the BETWEEN operator, as I used in Figure 2.43. The BETWEEN operator is handy when you're testing for a date value (as in the example), as it can "bracket" the values more easily. The syntax is easy and can also be "notted"that is, you can code "<test expression> NOT BETWEEN <beginning expression> AND <ending expression>". BETWEEN returns a Boolean TRUE if the value of the test expression is greater than or equal to the beginning expression and less than or equal to the ending expression. Sure, you can use the ">" and "<" instead of BETWEEN to create a more focused expression. I use BETWEEN quite a bit when testing for date values because the date datatypes (datetime, Smalldatetime) include the time, which can confuse a simple comparison test. For example, if I want to test for equality on a specific date, it won't match unless the time is also exactly the same. Of course, you could (perhaps should) go to the trouble of using the T-SQL DatePart functions to break off the specific part of the date for which you're testing. See BOL for more information on DatePart and the other date-handling functions. Handling NULLsWhen a column contains a value, it must comply with the datatype specified for the column. However, if the column cannot contain a value because it's simply not known, you might be able to assign NULL to the columnassuming you've defined the column to permit NULLs in the table definition. For example, when you're filling out a form and it asks for "date married", not all of us can provide a dateespecially those trying to remain single long enough to graduate from high school. There are many situations where assigning a column to NULL makes senseand some that don't. When you define a table's PRIMARY KEY or IDENTITY property, it cannot be permitted to have a NULL value. Any other critical information in the table should not be permitted to be set to NULL. When your table has a primary key/foreign key (a parent/child) relationship, you cannot permit the parent value to be set to NULL. That is, there must be a valid parent (primary key value) for each child row. Handling and Comparing NULL ValuesThere are several special rules when it comes to handling NULLs. First, remember that a NULL is not an empty string (""), a zero, or blankit's a definitive "state". In addition, you can't simply compare a value against a NULL. "IF 5 = NULL" does not make sense, just as comparing a column value against NULL. If you need to determine whether a column contains a NULL value, you must use the IF NULL or IS NOT NULL T-SQL syntax. When you want to assign a NULL value to a column in T-SQL, you can use the keyword "NULL" in the INSERT or UPDATE statementor by leaving the column value out of the INSERT statement. In this case, the INSERT operation first checks to see if there is a default value defined for the columnin which case, it's used; otherwise, the column is set to NULL. When searching a table by referencing a column that might contain NULL values, SQL Server ignores any NULL columns and does not include them in the rowset membership. When I get to Chapter 10, I'll discuss how to handle NULLs in ADO.NET queries and parameters. How SQL Server handles NULL comparisons is determined by the connection-specific SET ANSI_NULLS setting:
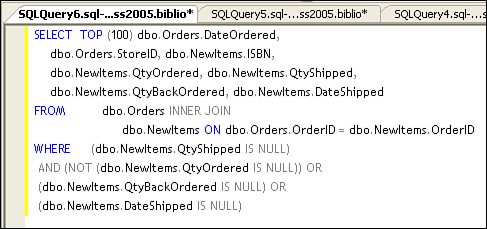
You can change the state of the ANSI_NULLS switch using the SET statement in your T-SQL or use the Query Options properties dialog (shown in Figure 2.49) to change it. Figure 2.49. Setting ANSI options using the Query Options dialog.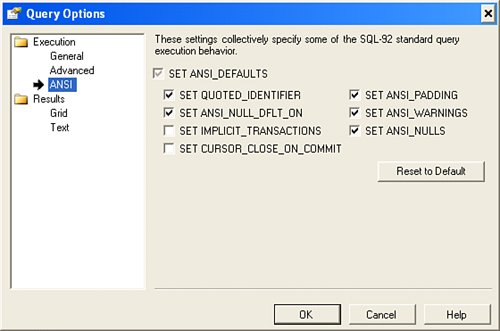 It makes sense that computations involving NULL values also return NULL. Consider that if TotalSales is NULL, the expression (TotalSales * 1.25) should also return NULL. It's like asking the head of your sales division, "Hey, Sally. I hear that the sales figures aren't in for the fourth quarter, but if they were up 2.5%, what would that be more than last year?" If she answers, you might need to find another sales managerpreferably one that had not worked for the government. Okay, so how does one code a T-SQL expression when ANSI_NULLS is ONas it will be unless you over-ride the default? It's not that hard. Take a look at the example in Figure 2.50. In this case, I'm testing the Orders and Items tables to see if any of the orders were not shipped even though there were confirmed orders. Note the syntax for the "IS NOT NULL" case. This T-SQL code was generated by Visual Studioit negates the IS NULL expression instead of using the IS NOT NULL syntax. You're free to use either technique. Figure 2.50. Testing for NULL values in a TSQL SELECT. Using the sql_variant DatatypeAny Visual Basic developer who has transitioned to Visual Basic.NET can tell you how the Variant datatype has changed how data access problems can be addressed. In situations where the data being passed from tier to tier or even in-process is unstructured or "fuzzy," the Variant datatype can be a good choice. This is the datatype most favored by political partieseven George W. Bush made reference to "fuzzy" data in the Presidential debates; making an obvious reference to Variant data. In Visual Basic, the Variant datatype permits developers to specify a program variable that refers to virtually any type of data, be it a number, string, picture, or object. Visual Basic stores the data and additional data description information to help Visual Basic and the programmer manage the information. I won't get into how efficiently (or inefficiently) Visual Basic handles Variants, but consider that the new Visual Basic.NET framework no longer supports the Variant datatype. (It's replaced with the Object datatype.) Now, suppose you have a situation where your application calls for additional information to be stored for a given customer, but you don't really know ahead of time what that information looks like. However, you do know it's going to either be a number (an integer, float, or decimal), a string, or perhaps even a Boolean value. (It might also be a binary large object [BLOB], as would be stored in a TEXT or IMAGE datatype, but SQL Server sql_variant datatypes don't let you store BLOBs, so let's pretend that these are not an option for your design.) One approach you might take is to create a table that looks something like Table 2.3.
This table defines 100 columns, each specifying a "property," each with a different purpose and each with a use-appropriate datatype. The ObjectID column provides a relational reference to a unique entitypossibly an object in the database or perhaps just a customer. If you wanted to determine what the Prop3 value was for a particular customer, you could easily fetch it using a simple SELECT. However, the sheer width of this table would make a relational database designer cringe or perhaps bring C. J. Date[19] back from the grave. As you can imagine, this table is mostly filled with nothing (Null values), so it's not particularly efficient to manage. And what if you have to define more (and more) properties as your business rules evolve? What if there is more than one row that defines a specific property or if the combination of several properties exhausted the row capacity of SQL Server (a little under 8K)? From here on, you're on your own.
Another ApproachSQL Server 2000 and later (thankfully) support Variantsat least, in a way. While the implementation is not the same as that supported by the Visual Basic 6.0 Variant datatype, the sql_variant SQL Server datatype is flexible enough to solve our rule-morphing problem. Since sql_variant can take on (almost) any SQL Server datatype, our customer data property table (as shown in Table 2.4) now looks a little different.
In this case, I define the table with three columns: one to identify the object, another to name the property being managed, and a third to hold the data for that property. This is an example of a "sparse" table. This permits us to define as many properties as the current business rules dictate. Since the sql_variant "Info" column can hold any (non-BLOB) datatype, we can easily store whatever information that presents itselfeven if we didn't anticipate that type of data during the design phase. The challenge here is to write a front-end application that knows how to adapt itself to this ever-changing set of properties. |







EAN: 2147483647
Pages: 227