Managing Concurrency by Design or Collision
| Managing concurrency is one of the toughest aspects of making changes to any database, whether it's a 3 x 5 card file or a 40TB server farm supporting an ecommerce site selling used fruit. The struggle is deciding what to do when more than one user has update access to the database. Over the years, I keep coming back to a few fundamental solutionsmost of which have to do with designing systems where multiple access is prevented in the first place. Sure, there are systems where this approach is simply not possible, but on closer inspection, the developers (and I) often find reasonable ways that this "prevent collision" strategy can be implemented. If this is possible, it makes your collision handlers far simpler. One approach that implements this strategy is the "no insert" paradigm. I've also called this the "waitress" or "anvil salesman's" technique over the years. Imagine a restaurant where the waitresses use pre-numbered pads to take orders so no two waitresses in the restaurant have the same range of numbers. This is a "disconnected" database of sorts. It requires no connection to the restaurant system until the order is actually entered in the systemand then only momentarily. Collisions are not possible unless waitress Sally tries to change waiter Sam's chicken-fried steak order to liver and onions. Again, this is a clear violation of the system rules and could be handled with a clear system policyno one is permitted to order liver and onions. To implement this and similar schemes, set up your system so applications (users) "check out" a set of rows to update and post at a later timeeven days or months in the future. When the new rows are created, the identity values are assigned by the server in bulkestablishing the "ownership" of the rows. Typically, the application calls a stored procedure that creates a block of pre-filled Customers rowsenough to last until the application is connected again. These new Customers rows are fetched into application memorythey already contain unique PKs or identity values and default settings that reflect the users/application's attributes. The connection need not remain open any longer than it takes to fetch the new rows (the new receipt pad). If the application ends and the list of new rows is lost, a fresh list could be refetched from the server or reloaded from a client-side data store (possibly persisted in a SQL Server Everywhere database). In a similar fashion, your application can call stored procedures to create pre-populated Orders and Items rows ahead of time and fetch these into application memorythese can be based on one of the Customers rows you've already checked out, but that's not really necessary, as the ownership chain starts with the parent (Customer) rows. This means the application could create new Orders and Items rows and set the PK with confidence that the relational hierarchy would be correcteven when persisted to the server database. These could also be persisted locally (a SQL Server Everywhere or SQL Express database might be a good choice for this). Because your application "owns" these uncompleted rowsthe server has them checked out to your applicationyou don't have to worry about collisions. When reconnected, your application need not worry about some other application altering your rowsand you can't change theirs. Sure, your database might have to accommodate some "placeholder" rows, but given the capacities of today's databases (and hard drives), this seems far less of a concern now than when databases needed to fit on a 10MB drive. Managing an @@Identity Crisis[3]
As some of you know, I spend a portion of my day trolling the newsgroups, fishing for interesting topics. Nowadays, I stay away from JET/Access questionsI'm no longer impartial enough to answer these folks without putting a knot in my stomach. I keep thinking, "You wouldn't be asking this question if you weren't using a toy database engine." But that's fodder for another article. Each week, there are several questions that discuss how to handle new Identity values. For example, once you add a new row to a database table that includes an Identity column, how can you tell what value the server assigned to the Identity column? This section further illuminates the mechanics of managing a system that depends on Identity column update strategies, as illustrated by the examples shown earlier in this chapter. I call this strategy "Post-INSERT fetching," as it executes an additional SELECT query that returns the newly created Identity value after the INSERT is executed. This SELECT can return a rowset or OUTPUT parameters to ADO.NET, which (if cajoled) can be used to post the newly created Identity value back into the client-side row. Both of the examples just shown in this chapter implement this strategy. But there's more to handling Identity values than simply fetching the newly generated valuethat's actually fairly easy (unless you're using the CommandBuilder, as I also discussed earlier in this chapter). What about the "identity" values for child rows that are created on the client? How should you manage these values when you're creating parent-child relationships and need to have valid Identity values to manage inter-table relationships? We'll discuss that, too. What Are Identity Columns?Before we wade into the swamp of Identity details, let's clear up a few concepts for those not up-to-speed on the fundamentals. An Identity column is used to provide a unique Integer value that's guaranteed to be unique in the table within the scope of the serverand no further. That is, if you have several servers spread all over the world, there's no guarantee that Identity values generated for the CustomerOrders table in Boston won't collide with the values generated for the same table in another identical database in Cleveland or Calcutta. This means that if you want a unique number that's guaranteed to be unique worldwide, you can't use an Identity without a further qualifier (such as a system ID). In this case, you should consider use of a GUID UNIQUEIDENTIFIER instead. For the context of this section, let's just assume that we're working with a single DBMS server and don't care about replicating with another server's database. How Does SQL Server Manage Identity Values?When you execute INSERT against a table row containing an Identity column, the T-SQL does not include a value for the Identity column because the DBMS server automatically adds an increment (usually 1) to the highest Identity value in the table and uses this value for the new row's Identity value. SQL Server also saves the value in a connection-global variable: @@IDENTITY. This means that if an INSERT statement (however it's executed) causes a trigger to fire that also adds a row to a table, the @@IDENTITY value is set to the new value. That's fine (unless your database uses triggers), but what happens when a row is deleted? Is the deleted row's Identity value forever orphaned? Yep, unless you reseed the Identity (DBCC CHECKIDENT), deleted Identity values are lost. Identity values are also orphaned when a transaction is rolled back. This means that when you use Identity columns, you'll need to be prepared for gaps in the series. It also means that eventually, the Integer you're using will overflow, so it's important that you use an Integer datatype large enough for your needsnow and well into the future. The "integer" datatype in SQL Server can identify about 2 billion rows, while a "bigint" can identify 9,223,372,036,854,775,807 rows (that's a lot of rows). However, a "smallint" can identify only about 32,000 rows. I actually had someone complain that he ran out of Identity valuesthey had used a "tinyint", which ran out after 255 rows. Sigh. I'm not going to delve into techniques to recover orphaned Identity valuesit's tough to do, and over the years, I've found it's not worth the trouble. Just make sure to define an integer wide enough to get you through the next century or corporate takeover when they rewrite everything anywayperhaps they'll bring you out of retirement to fix it. How ADO.NET Handles Identity ValuesADO.NET has its own mechanism to handle client-side Identity values because ADO.NET works with "disconnected" data and does not expect to have live access to the "real" server-side data table. This means that as you add rows to a DataTable object on your client, the Identity value generated locally by ADO.NET won't have any bearing on the Identity values of existing rows in the database or on the rows in the local DataTable. Huh? How can that work? Well, ADO.NET does not make any effort to test the Identity values it generates against existing Identity values in the client-side, disconnected DataTable. It sets the new Identity values based on the AutoIncrementSeed and AutoIncrementStep. This means that if your existing DataTable has Identity values ranging from 1 to 10 and you set the AutoIncrementSeed value to 10, ADO.NET does what it's toldit starts at 10 and you'll likely end up with two rows with the same Identity value (not good). These "autoincrement" properties can be set before you add any rows to the DataTableafterward, it does not seem to matter. The demonstration application included with this section illustrates this behavior. "Tricking" ADO.NETWhen setting a client-side Identity value, the trick is to set a value that the server-side database table is not using or not likely to be used by rows being added by other clients. That way, any new rows won't collide with existing rows in the current DataTable. Since server-side Identity values are invariably positive integers, you have only one other set of numbers to use on the clientnegative numbers. ADO.NET is ready to handle this contingencyset both the AutoIncrementSeed and the AutoIncrementStep to 1. This way, each new row is created with an Identity unique to the client. This also means that a row in a parent-child relationship can easily identify its relations before the server assigns their "real" Identity value when you execute the INSERT query. These negative numbers are used to interrelate parents with their children until ADO.NET inserts the new rows into the server-side database with the Update method. Remember, the INSERT statements you or ADO.NET generates (via the CommandBuilder) don't include the client-side Identity valuesthey're needed only to identify client-side rows and relationships. Updating Parent-Child RelationshipsOnce you create a new parent row (for example, a row in the Customers table) and let ADO.NET generate its new client-side Identity value, you can create as many child rows (for example, Orders) as necessary and safely use the parent's ADO.NET-generated Identity value as a foreign key (so the child row is related back to the correct parent). Yes, ADO.NET knows how to handle these relationships correctly when it comes time to post these new rows to the server. When you execute the Update method, ADO.NET executes the INSERT for the parent row first and then all associated child rows. If you set up your InsertCommand correctly, the server-generated Identity value is propagated to the child foreign key valueI showed you how to do this in the previous section.
This sample application did not avail itself of any of the client-side hierarchy-management features (if you can call them that) in ADO.NETthere was no need. Figure 12.26 illustrates the routine that walks through the hierarchy used in this application. In this case, it's the typical Customer, Orders, Items hierarchy. The Customer table is a parent to the Orders table, which is a parent to the Items table. Because of this three-tiered approach, we must perform the updates in a specific sequence to maintain referential integrity. In other words, this sequence means that no child is created without an immediate parent, and no parent is deleted if it has an immediate child. Since there are three levels of hierarchy here, the Orders table is both a parent (to the Items table) and a child (of the Customers table). Figure 12.26. Posting changes to a hierarchy of DataTable objects. To implement this hierarchical update:
This way, children are added after their parents but are deleted only after the parents are deleted. The last updates delete any parent rows marked for removal, so the children are deleted first (before their parents).
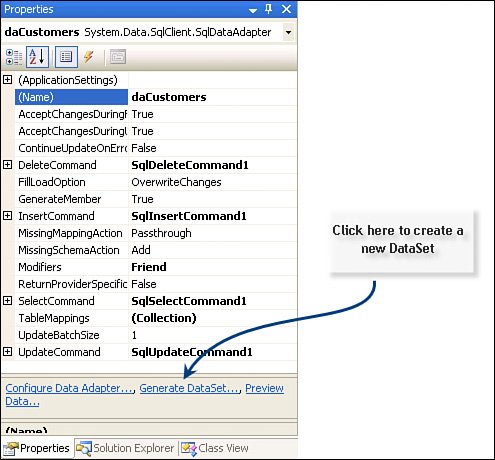
Nope, you don't see a call to the AcceptChanges method in this codeit's not necessary, as it's called automatically by the Update method after it posts its changes to the database. Retrieving New Identity ValuesThe real problems come when you want to find out what Identity values were generated by SQL Server. No, ADO.NET does nothing on its own to help. Visual Studio's DataAdapter Configuration Wizard (DACW) can help generate additional SQL for your InsertCommand to retrieve the new row's Identity, but the CommandBuilder is clueless in this regard, so it's no help at all. In the example I wrote for this section (see "Managing Identity Hierarchies" on the DVD), I used the DACW three times to build SqlDataAdapter objects for each of the three database tablesCustomers, Orders, and Items. I then created DataSet objects for each of these using the Generate DataSet "button" in the DataAdapter Property dialog. This can be referenced by right-clicking on the tooltray icon created for each SqlDataAdapter and choosing "Properties"as shown in Figure 12.27. Figure 12.27. Creating a new DataSet from the DataAdapter Properties dialog. These DataAdapters were created to invoke stored procedures to fetch and perform the action commands. The InsertCommand stored procedure (as shown in Figure 12.28) includes a SELECT to fetch the newly created Identity value. ADO.NET fetches this automatically, as discussed earlier in this chapter. In this case, the value is returned as an OUTPUT parameter, but ADO.NET also recognizes a rowset containing the new Identity value. Figure 12.28. Fetching the newly created Identity value.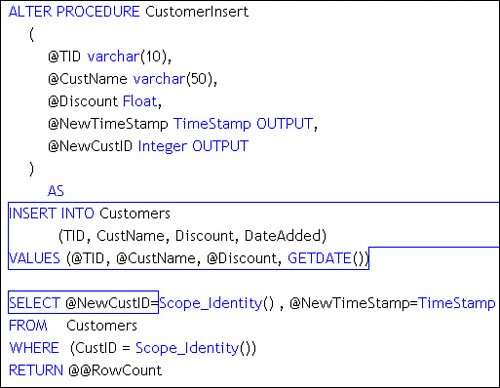 Problems with @@ IDENTITYThe example I wrote for this section did not depend on any code generated by the CommandBuilder or the DACW. I was worried that the problems mentioned in 2003 had not been addressed. To circumvent the issue, I simply pointed the DACW to my own stored procedures that fetched the rows and performed the action commands. However, when I first wrote about this issue, the DACW-generated code included a reference to @@IDENTITY, the global variable I mentioned earlier that contains the last Identity value generated on the connection. In the current version of Visual Studio, this problem has been addressed (I guess someone read my article)the generated code uses the new (implemented in SQL Server 2000) SCOPE_IDENTITY() function that returns the Identity value created in the programmatic scope of the procedure that inserted the new row. If you find code that still uses @@IDENTITY, do yourself a favor and replace it with SCOPE_IDENTITY(). That's because use of @@IDENTITY assumes that your database does not expect any triggers to fire when the INSERT is executed. If a trigger fires after you insert a new row, and if that trigger adds another row to a table (any table that has an Identity column), the @@IDENTITY global variable is set to that new Identity valuenot the one your INSERT generated. This makes the V1.1 DACWgenerated code work for simple situations, but not when your database gets more sophisticated. Hopefully, that won't happen until after you retire. |
EAN: 2147483647
Pages: 227