12.5 Failure and recovery
|
| < Day Day Up > |
|
All application systems, including database systems, are prone to failures. While there are several reasons for these failures, and these failures should be minimized for continuous business operation, they still continue to occur. The database technology should be able to handle many of these failures, providing immediate recovery and placing the systems back in operation.
There are several failure scenarios in a RAC environment. Some of these scenarios could be found in the traditional stand-alone configuration, others are specific to the RAC environment.
Figure 12.2 illustrates the various areas of the system (operating system, hardware and database) that could fail. The various failure scenarios in a two-node configuration, as illustrated in Figure 12.2, are:
-
Interconnect failure
-
Node failure
-
Instance failure
-
Media failure
-
GSD/GCS failure
-
Instance hang or false failure
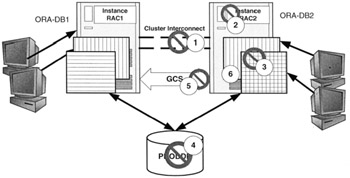
Figure 12.2: RAC configura tion with points of failure.
Let us briefly explain each of these failure scenarios and discuss the various recovery scenarios for these categories.
1. Interconnect failure
If the interconnect between the nodes fails, either because of a physical failure or a software failure in the communication or IPC layer, it appears to the cluster manager (CM) at each end of the interconnect that the node at the other end has failed. The CM software should use an alternative method, such as checking for a quorum disk or pinging the node, to evaluate the status of the system. It may shut down both nodes or just one of the nodes at the end of the failed connection. It will also fence the disks from any node it shuts down to prevent any further writes from being completed.
Recovery operations are not performed because of a cluster interconnect failure. The interconnect failure should cause the instance or node to fail, and only then is Oracle recovery performed. A typical situation under these circumstances would be when one instance (or both) loses communication with the other, and waits until it receives a failure signal. The failure of the cluster interconnect could cause a communication failure between the two nodes. And when the heartbeat mechanism between the two nodes is not successful, the CM, triggered by the heartbeat timeout parameter, signals a node failure. However, since there was no physical failure of the instance and/or node, the LMON process is unable to write to the disk regarding the status of the other instance.
While there is no physical failure of the instance and/or node, every instance would wait to receive a communication from the other instance that it is either up and alive and communication can continue or that the other instance is down and is not reachable. If, after a certain time, there is no response, one of the instances that is currently up will try to force shutdown of the other instance. These repeated tries will be logged in the alert log as illustrated below.
The output below is the instance activity as indicated in the alert log files, where another instance in the cluster is not reachable and the current instance is in a wait state before attempting recovery. It should be noted that after several attempts when the other instance does leave the cluster, the recovery operation begins.
The following output from the alert log indicates the various steps during a recovery operations.
Wed Nov 13 08:51:25 2002 Instance recovery: looking for dead threads Instance recovery: lock domain invalid but no dead threads Wed Nov 13 13:19:43 2002 Communications reconfiguration: instance 0 Wed Nov 13 13:19:51 2002 Evicting instance 1 from cluster Wed Nov 13 13:20:11 2002 Waiting for instances to leave: 1 Wed Nov 13 13:20:31 2002 Waiting for instances to leave: 1 Wed Nov 13 13:20:51 2002 Waiting for instances to leave: 1 Wed Nov 13 14:49:30 2002 Reconfiguration started List of nodes: 1, Wed Nov 13 14:49:30 2002 Reconfiguration started List of nodes: 1, Global Resource Directory frozen one node partition Communication channels reestablished Master broadcasted resource hash value bitmaps Non-local Process blocks cleaned out Resources and enqueues cleaned out Resources remastered 7071 26264 GCS shadows traversed, 0 cancelled, 51 closed 22664 GCS resources traversed, 0 cancelled 24964 GCS resources on freelist, 37877 on array, 37877 allocated set master node info Submitted all remote-enqueue requests Update rdomain variables Dwn-cvts replayed, VALBLKs dubious All grantable enqueues granted 26264 GCS shadows traversed, 0 replayed, 51 unopened Submitted all GCS remote-cache requests 0 write requests issued in 26213 GCS resources 63 PIs marked suspect, 0 flush PI msgs Wed Nov 13 14:49:32 2002 Reconfiguration complete Post SMON to start 1st pass IR Wed Nov 13 14:49:32 2002 Instance recovery: looking for dead threads Wed Nov 13 14:49:32 2002 Beginning instance recovery of 1 threads Wed Nov 13 14:49:32 2002 Started first pass scan Wed Nov 13 14:49:33 2002 Completed first pass scan 27185 redo blocks read, 1197 data blocks need recovery Wed Nov 13 14:49:34 2002 Started recovery at Thread 1: logseq 25, block 745265, scn 0.0 Recovery of Online Redo Log: Thread 1 Group 3 Seq 25 Reading mem 0 Mem# 0 errs 0: /dev/vx/rdsk/oraracdg/partition1G_27 Mem# 1 errs 0: /dev/vx/rdsk/oraracdg/partition1G_29 Wed Nov 13 14:49:35 2002 Completed redo application Wed Nov 13 14:49:36 2002 Ended recovery at Thread 1: logseq 25, block 772450, scn 0.115066397 813 data blocks read, 1212 data blocks written, 27185 redo blocks read Ending instance recovery of 1 threads SMON: about to recover undo segment 1 SMON: mark undo segment 1 as available SMON: about to recover undo segment 2 ....... Wed Nov 13 15:03:21 2002 Reconfiguration started List of nodes: 0,1, Global Resource Directory frozen Communication channels reestablished Master broadcasted resource hash value bitmaps Non-local Process blocks cleaned out Resources and enqueues cleaned out Resources remastered 6966 26984 GCS shadows traversed, 0 cancelled, 601 closed 26383 GCS resources traversed, 0 cancelled 24887 GCS resources on freelist, 37877 on array, 37877 allocated set master node info Wed Nov 13 15:03:24 2002 Reconfiguration complete Wed Nov 13 15:03:24 2002 Instance recovery: looking for dead threads Instance recovery: lock domain invalid but no dead threads
Under such circumstances where the communication between instances fails and one instance is not responding to other's requests, there are considerable performance delays. This is due to the fact that the Oracle kernel is repeatedly trying to shut down the unreachable instance in order to perform recovery.
These circumstances call for a manual intervention, where the database administrator would be required to shut down one of the instances to allow business to continue. To avoid this manual intervention, there are two possible actions:
-
Write a cluster validation code to check for the availability of GCS and GES communication between nodes. This allows for detecting and shutting down an instance when the CM is unable to perform such a task. The validation routine would be an update command that continually loops through a block that performs an update of a record in a table when a single data block is covered by a single PCM lock. This block would run on all the nodes at each end of the interconnect. By running this routine on every possible pair of nodes where each pair is updating a different block, an abnormal delay in obtaining the lock would indicate a problem with the remote GCS or the interconnect between the nodes. The process could be updating the record based on who detected the problem and could force a shutdown of the instance.
-
Another method that would be much more clear and straight forward is to provide redundant interconnects between each pair of nodes. The additional interconnect will act as a standby to the primary interconnect and will be used when the primary inter connect fails. However, the possibility of having additional interconnects depends on the hardware vendor. The additional interconnects should be an important part of the deployment architecture, to provide true high availability of the database cluster. If this is not provided, the cluster interconnect becomes a single point of failure.
Once the instance has been shut down, the instance recovery operation begins.
2. Node failure
RAC comprises two or more instances sharing a common single copy of a physical database. Each instance is normally attached or configured to run on a specific node. In RAC, if the entire node fails, the instance that includes GCS elements stored in its shared pool as well as the GCS processes running on that node will fail. Under such circumstances, the GCS must reconfigure itself in order to remaster the locks that were being managed by the failed node before instance recovery can occur.
Many cluster hardware vendors use a disk-based quorum system that allows each node to determine which other nodes are currently active members of the cluster. These systems also allow a node to remove itself from the cluster or to remove other nodes from the cluster. The latter is accomplished through a type of voting system, managed through the shared quorum disk, that allows nodes to determine which node will remain active if one or more of the nodes become disconnected from the cluster interconnect.
RAC relies on the CM of the operating system for failure detection. Using the heartbeat mechanism, the CM allows the nodes to communicate with the other nodes that are available on a continuous basis at preset intervals, e.g., 2 seconds on Sun and Tru64 clusters.[2] At each heartbeat, every member instance gives its status of the other members' availability. It they all agree, nothing further is done until the next heartbeat. If two or more instances report a different instance configuration among each other (e.g., because the cluster interconnect is broken between a pair of nodes), then one member arbitrates among the different membership configura tions. Once this configuration is tested, the arbitrating instance uses the shared disk to publish the proposed configuration to the other instances. All active instances then examine the published configuration, and, if necessary, terminate themselves.
Another important failure detection criterion is the heartbeat timeout condition. After a predefined timeout period (configurable on most operating systems), remaining nodes detect the failure and attempt to reform the cluster. (The heartbeat timeout parameter, like the heartbeat interval, varies from operating system to operating system; the default heartbeat timeout parameter on Sun clusters is 12 seconds and the default on Linux clusters is 10 seconds.) Based on the timeout interval and the heartbeat interval, the CM will validate the existence of the other node several times (in the case of Sun clusters about four times and in the case of Linux clusters about three times). If the remaining nodes form a quorum, the other nodes will reorganize the cluster membership.
The reorganization process regroups the nodes that are accessible and removes the nodes that have failed. For example, in a four-node cluster, if one node fails, the CM will regroup among the remaining three nodes. The CM performs this step when a node is added to a cluster or a node is removed from a cluster. This information is exposed to the respective Oracle instances by the LMON process running on each cluster node.
Up to this point the CM at the operating system level did the failure detection; since a node failure also involves an instance failure, there are further steps involved before the surviving instances can perform the recovery operation. Instance failure involves database recovery followed by instance recovery.
3. Instance failures
RAC has many instances talking to a common shared physical database. Since several instances are involved in this configuration, one or more instances (or all) are prone to failure. If all instances participating in the configuration fail, the database is in an unusable state; this is called a crash or database crash and the recovery process associated with this failure is called a crash recovery. However, if only one or more, but not all, of these instances fail, this is known as an instance failure and the recovery process associated with this failure is called an instance recovery.
We will now discuss both failure scenarios.
Database crash
All instances in a configuration could fail due to several reasons like a kernel-level exception. When all instances in the clustered configuration fail, the database is in an unusable state; however, this would not necessarily indicate that there is a problem with the database.
Recovery of an instance from a crash is similar to a recovery operation in a single instance configuration, where each instance would perform its instance recovery.
Instance failure
Instance failure could happen in several ways. The common reason for an instance failure is when the node itself fails. The node failure, as discussed above, could be due to several reasons, including power surge, operator error, etc. Other reasons for an instance failure could be because a certain background process fails or dies, or when there is a kernel-level exception encountered by the instance causing an ORA-0600 or ORA-07445 error. A failure by issuing a SHUTDOWN ABORT command by a database administrator could also cause an instance failure.
Instance failures occur where:
-
The instance is totally down and users do not have any access to the instance.
-
The instance is up, but when connecting to it there is a hang situation or user gets no response.
In the case where the instance is not available, users could continue access to the database in an active/active configuration, provided the failover option has been enabled in the application. The failover option, as discussed in Chapter 10 (Availability and Scalability), could be enabled either by using the OCI inside the application or by using the SQL client, where the failover options are configured in the tnsnames.ora file.
Recovery from an instance failure happens from another instance that is up and running, that is part of the cluster configuration, and whose heartbeat mechanism deduces the failure first and informs the LMON process on the node. The LMON process on each cluster node communicates with the CM on the respective node and exposes that information to the respective instances.
LMON provides the monitoring function by continually sending messages from the node on which it runs, often by writing to the shared disk. When the node fails to perform the functions and when LMON stops sending messages to other active instances, the other nodes consider that the node is no longer a member of the cluster. Such a failure causes a change in a node's membership status within the cluster.
The LMON process controls the recovery of the failed instance by taking over its redo log files and performing instance recovery.
Instance recovery is complete when Oracle has performed the following steps:
-
Rolling back all uncommitted transactions of the failed instance, called transaction recovery.
-
Replaying the online redo log files of the failed instance, called cache recovery.
How does Oracle know that recovery is required for a given data file? The SCN is a logical clock that increments with time. The SCN describes a ''version'' or a committed version of the database. When a database checkpoints, an SCN (called the checkpoint SCN) is written to the data file headers. This is called the start SCN. There is also an SCN value in the control file for every data file, which is called the stop SCN. The stop SCN is set to infinity while the database is open and running. There is another data structure called the checkpoint counter in each data file header and also in the control file for each data file entry. The checkpoint counter increments every time a checkpoint happens on a data file and the start SCN value is updated. When a data file is in hot backup mode, the checkpoint information in the file header is frozen but the checkpoint counter still gets updated.
When the database is shut down gracefully, with the SHUTDOWN NORMAL or SHUTDOWN IMMEDIATE command, Oracle performs a checkpoint and copies the start SCN value of each data file to its corresponding stop SCN value in the control file before the actual shutdown of the database.
When the database is started, Oracle performs two checks (among other consistency checks):
-
To see if the start SCN value in every data file header matches with its corresponding stop SCN value in the control file.
-
To see if the checkpoint counter values match.
If both these checks are successful, then Oracle determines that no recovery is required for that data file. These two checks are done for all data files that are online.
If the start SCN of a specific data file does not match the stop SCN value in the control file, then at least a crash recovery is required. This can happen when the database is shut down with the SHUTDOWN ABORT statement or if the instance crashes. After the first check, Oracle performs the second check on the data files by checking the checkpoint counters. If the checkpoint counter check fails, then Oracle knows that the data file has been replaced with a backup copy (while the instance was down) and therefore, media recovery is required.
| Note | Crash recovery is performed by applying the redo records in the online log files to the data files. However, media recovery may require applying the archived redo log files as well. |
Figure 12.3 illustrates the flow during the various stages of the recovery process during an instance failure. Instance failure, as we have discussed above, is a scenario where one or more, but not all, instances have failed. We will now discuss these various steps of the recovery process in detail.
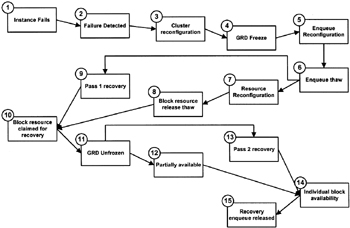
Figure 12.3: Instance recovery.
-
Instance fails: This is the first stage in the process, when an instance fails and recovery becomes a necessity. As illustrated above, an instance could fail for various reasons including operator error, when the database administrator executes the SHUTDOWN ABORT statement, or when the node that the instance is running on crashes.
-
Failure detected: The CM of the clustered operating system does the detection of a node failure or an instance failure. The CM is able to accomplish this with the help of certain parameters such as the heartbeat interval and the heartbeat timeout parameter. The heartbeat interval parameter invokes a watchdog[3] process that wakes up at a stipulated time interval and checks the existence of the other members in the cluster. On most O/Ss this interval is configurable, and can be changed with the help of the systems administrators. This value is normally specified in seconds. Setting a very small value could cause some performance problems. Though the overhead of this process running is really insignificant, on very busy systems, frequent running of this process could turn out to be expensive. Setting this parameter to an ideal value is important and is achieved by constant monitoring of the activities on the system and the amount of overhead this particular process is causing. When the instance fails, the watchdog process or the heartbeat validation interval does not get a response from the other instance within the time stipulated in the heartbeat timeout parameter; the CM clears and declares that the instance is down. From the first time that the CM does not get a response from the heartbeat check, to the time that the CM declares that the node has failed, repeated checks are done to ensure that the initial message was not a false message.
The timeout interval, like the heartbeat interval parameter, should not be set low. Unlike the heartbeat interval parameter, in the case of the timeout interval it is not a performance concern; rather, a potential to cause false failure detections because the cluster might inversely determine that a node is failing due to transient failures if the timeout interval is set too low. The false failure detections can occur on busy systems, where the node is processing tasks that are highly CPU intensive. While the system should reserve a percentage of its resources for these kinds of activities, occasionally when systems are high on resources with high CPU utilization, the response to the heartbeat function could be delayed and hence, if the heartbeat timeout is set very low, could cause the CM to assume that the node is not available when actually it is up and running.
-
Cluster reconfiguration: When a failure is detected, the cluster reorganization occurs. During this process, Oracle alters the node's cluster membership status. This involves Oracle taking care of the fact that a node has left the cluster. The GCS and GES provide the CM interfaces to the software and expose the cluster membership map to the Oracle instances when nodes are added or deleted from the cluster. The LMON process performs this exposure of the information to the remaining Oracle instances.
LMON performs this task by continually sending messages from the node it runs on and often writing to the shared disk. When such write activity does not happen for a prolonged period of time, it provides evidence to the surviving nodes that the node is no longer a member of the cluster. Such a failure causes a change in a node's membership status within the cluster and LMON initiates the recovery actions, which include remastering of GCS and GES resources and instance recovery.
The cluster reconfiguration process, along with other activities performed by Oracle processes, are recorded in the respective background process trace files and in the instance-specific alert log files.
*** 2002-11-16 23:48:02.753 kjxgmpoll reconfig bitmap: 1 *** 2002-11-16 23:48:02.753 kjxgmrcfg: Reconfiguration started, reason 1 kjxgmcs: Setting state to 6 0. *** 2002-11-16 23:48:02.880 Name Service frozen kjxgmcs: Setting state to 6 1. kjxgfipccb: msg 0x1038c6a88, mbo 0x1038c6a80, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (3744,204) kjxgfipccb: msg 0x1038c6938, mbo 0x1038c6930, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (3416,204) kjxgfipccb: msg 0x1038c67e8, mbo 0x1038c67e0, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (3088,204) kjxgfipccb: msg 0x1038c6bd8, mbo 0x1038c6bd0, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (2760,204) kjxgfipccb: msg 0x1038c7118, mbo 0x1038c7110, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (2432,204) kjxgfipccb: msg 0x1038c6fc8, mbo 0x1038c6fc0, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (2104,204) kjxgfipccb: msg 0x1038c7268, mbo 0x1038c7260, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (1776,204) kjxgfipccb: msg 0x1038c6e78, mbo 0x1038c6e70, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (1448,204) kjxgfipccb: msg 0x1038c6d28, mbo 0x1038c6d20, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (1120,204) kjxgfipccb: msg 0x1038c7a48, mbo 0x1038c7a40, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (792,204) kjxgfipccb: msg 0x1038c7508, mbo 0x1038c7500, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (464,204) kjxgfipccb: msg 0x1038c73b8, mbo 0x1038c73b0, type 22, ack 0, ref 0, stat 6 kjxgfipccb: Send cancelled, stat 6 inst 0, type 22, tkt (136,204) *** 2002-11-16 23:48:03.104 Obtained RR update lock for sequence 6, RR seq 6 *** 2002-11-16 23:48:04.611 Voting results, upd 1, seq 7, bitmap: 1 kjxgmps: proposing substate 2 kjxgmcs: Setting state to 7 2. Performed the unique instance identification check kjxgmps: proposing substate 3 kjxgmcs: Setting state to 7 3. Name Service recovery started Deleted all dead-instance name entries kjxgmps: proposing substate 4 kjxgmcs: Setting state to 7 4. Multicasted all local name entries for publish Replayed all pending requests kjxgmps: proposing substate 5 kjxgmcs: Setting state to 7 5. Name Service normal Name Service recovery done *** 2002-11-16 23:48:04.612 kjxgmps: proposing substate 6 kjxgmcs: Setting state to 7 6. kjfmact: call ksimdic on instance (0) *** 2002-11-16 23:48:04.613 *** 2002-11-16 23:48:04.614 Reconfiguration started Synchronization timeout interval: 660 sec List of nodes: 1, Global Resource Directory frozen node 1 * kjshashcfg: I'm the only node in the cluster (node 1) Active Sendback Threshold = 50% Communication channels reestablished Master broadcasted resource hash value bitmaps Non-local Process blocks cleaned out Resources and enqueues cleaned out Resources remastered 2413 35334 GCS shadows traversed, 0 cancelled, 1151 closed 17968 GCS resources traversed, 0 cancelled 20107 GCS resources on freelist, 37877 on array, 37877 allocated set master node info Submitted all remote-enqueue requests Update rdomain variables Dwn-cvts replayed, VALBLKs dubious All grantable enqueues granted *** 2002-11-16 23:48:05.412 35334 GCS shadows traversed, 0 replayed, 1151 unopened Submitted all GCS cache requests 0 write requests issued in 34183 GCS resources 29 PIs marked suspect, 0 flush PI msgs *** 2002-11-16 23:48:06.007 Reconfiguration complete Post SMON to start 1st pass IR *** 2002-11-16 23:52:28.376 kjxgmpoll reconfig bitmap: 0 1 *** 2002-11-16 23:52:28.376 kjxgmrcfg: Reconfiguration started, reason 1 kjxgmcs: Setting state to 7 0. *** 2002-11-16 23:52:28.474 Name Service frozen kjxgmcs: Setting state to 7 1. *** 2002-11-16 23:52:28.881 Obtained RR update lock for sequence 7, RR seq 7 *** 2002-11-16 23:52:28.887 Voting results, upd 1, seq 8, bitmap: 0 1 kjxgmps: proposing substate 2 kjxgmcs: Setting state to 8 2. Performed the unique instance identification check kjxgmps: proposing substate 3 kjxgmcs: Setting state to 8 3. Name Service recovery started Deleted all dead-instance name entries kjxgmps: proposing substate 4 kjxgmcs: Setting state to 8 4. Multicasted all local name entries for publish Replayed all pending requests kjxgmps: proposing substate 5 kjxgmcs: Setting state to 8 5. Name Service normal Name Service recovery done *** 2002-11-16 23:52:28.896 kjxgmps: proposing substate 6 kjxgmcs: Setting state to 8 6. *** 2002-11-16 23:52:29.116 *** 2002-11-16 23:52:29.116 Reconfiguration started Synchronization timeout interval: 660 sec List of nodes: 0,1,
During this stage of recovery when the reconfiguration of cluster member ship takes place, the RAC environment is in a state of system pause and most client transactions are suspended until Oracle completes recovery processing.
Analyzing the LMON trace. In general, the LMON trace file listed above contains the recovery and reconfiguration information on locks, resources, and states of its instance group.
The six substates in the Cluster Group Service (CGS) that are listed in the trace file are:
-
State 0: Waiting for the instance reconfiguration.
-
State 1: Received the instance reconfiguration event.
-
State 2: Agreed on the instance membership.
-
States 3, 4, 5: CGS name service recovery.
-
State 6: GES/GCS (lock/resource) recovery.
Each state is identified as a pair of incarnation number and its current substate. ''Setting state to 7 6'' means that the instance is currently at incarnation 7 and substate 6.
''kjxgfipccb'' is the callback on the completion of a CGS message send. If the delivery of message fails, a log would be generated. Associated with the log are message buffer pointer, recovery state object, message type and others.
''Synchronization timeout interval'' is the timeout value for GES to signal an abort on its recovery process. Since the recovery process is distributed, at each step, each instance waits for others to complete the corresponding step before moving to the next one. This value has a minimum of 10 minutes and is computed according the number of resources.
-
GRD freeze: The first step in the cluster reconfiguration process, before beginning the actual recovery process, is for the CM to ensure that the GRD is not distributed and hence freezes activity on the GRD so that no future writes or updates happen to the GRD on the node that is currently performing the recovery. This step is also recorded in the alert logs. Since the GRD is maintained by the GCS and GES processes, all GCS and GES resources and also the write requests are frozen. During this step of the temporary freeze, Oracle takes control of the situation and balances the resources among the available instances.
Sat Nov 16 23:48:04 2002 Reconfiguration started List of nodes: 1, Global Resource Directory frozen one node partition Communication channels reestablished
-
Enqueue reconfiguration: Enqueue resources are reconfigured among the available instances.
-
Enqueue thaw: After the reconfiguration of resources among the available instances, Oracle makes the enqueue resources available. At this point the process forks to perform two tasks in parallel, resource reconfiguration and pass 1 recovery.
-
Resource reconfiguration: This phase of the recovery is important in a RAC environment where the GCS commences recovery and remastering of the block resources, which involves rebuilding lost resource masters on surviving instances.
Remastering of resources is exhaustive by itself because of the various scenarios under which remastering of resources takes place. The following output from the alert log illustrates the reconfiguration steps:
Sat Nov 16 23:48:04 2002 Reconfiguration started List of nodes: 1, Global Resource Directory frozen one node partition Communication channels reestablished Master broadcasted resource hash value bitmaps Non-local Process blocks cleaned out Resources and enqueues cleaned out Resources remastered 2413 35334 GCS shadows traversed, 0 cancelled, 1151 closed 17968 GCS resources traversed, 0 cancelled 20107 GCS resources on freelist, 37877 on array, 37877 allocated set master node info Submitted all remote-enqueue requests Update rdomain variables Dwn-cvts replayed, VALBLKs dubious All grantable enqueues granted 35334 GCS shadows traversed, 0 replayed, 1151 unopened Submitted all GCS remote-cache requests 0 write requests issued in 34183 GCS resources 29 PIs marked suspect, 0 flush PI msgs Sat Nov 16 23:48:06 2002 Reconfiguration complete
-
Resource release: Once the remastering of resources is completed, the next step is to complete processing of pending activities. Once this is completed, all resources that were locked during the recovery process are released or the locks are downgraded (converted to a lower level).
-
Pass 1 recovery: This step of the recovery process is performed in parallel with steps 7 and 8.SMON will merge the redo thread ordered by SCN to ensure that changes are written in an orderly fashion. SMON will also find BWR in the redo stream and remove entries that are no longer needed for recovery, because they are PI of blocks already written to disk. A recovery set is produced that only contains blocks modified by the failed instance with no subsequent BWR to indicate that the blocks were later written. Each entry in the recovery list is ordered by first-dirty SCN to specify the order to acquire instance recovery locks. Reading the log files and identifying the blocks that need to be recovered completes the first pass of the recovery process.
Post SMON to start 1st pass IR Sat Nov 16 23:48:06 2002 Instance recovery: looking for dead threads Sat Nov 16 23:48:06 2002 Beginning instance recovery of 1 threads Sat Nov 16 23:48:06 2002 Started first pass scan Sat Nov 16 23:48:06 2002 Completed first pass scan 5101 redo blocks read, 490 data blocks need recovery Sat Nov 16 23:48:07 2002 Started recovery at Thread 1: logseq 29, block 2, scn 0.115795034 Recovery of Online Redo Log: Thread 1 Group 1 Seq 29 Reading mem 0 Mem# 0 errs 0: /dev/vx/rdsk/oraracdg/partition1G_31 Mem# 1 errs 0: /dev/vx/rdsk/oraracdg/partition1G_21 Sat Nov 16 23:48:08 2002 Completed redo application Sat Nov 16 23:48:08 2002 Ended recovery at Thread 1: logseq 29, block 5103, scn 0.115820072 420 data blocks read, 500 data blocks written, 5101 redo blocks read Ending instance recovery of 1 threads
-
Block resource claimed for recovery: Once pass 1 of the recovery process completes and the GCS reconfiguration has completed, the recovery process continues by:
-
Obtaining buffer space for the recovery set, possibly by performing write operation to make room.
-
Claiming resources on the blocks identified during pass 1.
-
Obtaining a source buffer, either from an instance's buffer cache or by a disk read.
-
During this phase, the recovering SMON process will inform each lock element's master node for each block in the recovery list that it will be taking ownership of the block and lock for recovery. Blocks become available as they have been recovered. The lock recovery is based on the ownership of the lock element. This depends on one of the various scenarios of lock conditions:
Scenario 1: Let us assume that all instances in the cluster are holding a lock status of NL0; SMON acquires the lock element in XL0 mode, reads the block from disk and applies redo changes, and subsequently writes out the recovery buffer when complete.
Scenario 2: In this situation, the SMON process of the recovering instance has a lock mode of NL0 and the second instance has a lock status of XL0; however, the failed instance has a status similar to the recovery node, i.e., NL0. In this case, no recovery is required because the current copy of the buffer already exists on another instance.
Scenario 3: In this situation, let us assume that the recovering instance has a lock status of NL0; the second instance has a lock status of XG0.
However, the failed instance has a status similar to the recovery node. In this case also, no recovery is required because a current copy of the buffer already exists on another instance. SMON will remove the block entry from the recovery set and the recovery buffer is released. The recovery instance has a lock status of NG1; however, the second instance that originally had a XG0 status now holds NL0 status after writing the block to disk.
Scenario 4: Now, what if the recovering instance has lock status of NL0; the second instance has a lock status of NG1. However, the failed instance has a status similar to the recovery node. In this case the consistent read image of the latest PI is obtained, based on SCN. The redo changes are applied and the recovery buffer is written when complete. The recovery instance has a lock element of XG0 and the second instance continues to retain the NG1 status on the block.
Scenario 5: The recovering instance has a lock status of SL0 or XL0 and the other instance has no lock being held. In this case, no recovery is needed because a current copy of the buffer already exists on another instance. SMON will remove the block from the recovery set. The lock status will not change.
Scenario 6: The recovery instance holds a lock status of XG0 and the second instance has a lock status of NG1. SMON initiates the write of the current block. No recovery is performed by the recovery instance. The recovery buffer is released and the PI count is decremented when the block write has completed.
Scenario 7: The recovery instance holds a lock status of NG1 and the second instance holds a lock with status of XG0. In this case, SMON initiates a write of the current block on the second instance. No recovery is performed by the recovery instance. The recovery buffer is released and the PI count is decremented when the block write has completed.
Scenario 8: The recovering instance holds a lock status of NG1, and the second instance holds a lock status of NG0. In this case a consistent read copy of the block is obtained from the highest PI based on SCN. Redo changes are applied and the recovery buffer is written when complete.
-
GRD unfrozen: After the necessary resources are obtained, and the recovering instance has all the resources it needs to complete pass 2 with no further intervention, the block cache space in the GRD is unfrozen.
The following extract from the alert log illustrates the activities around the GRD:
Sat Nov 16 23:52:29 2002 Reconfiguration started List of nodes: 0,1, Global Resource Directory frozen Communication channels reestablished Master broadcasted resource hash value bitmaps Non-local Process blocks cleaned out Resources and enqueues cleaned out Resources remastered 2415 35334 GCS shadows traversed, 0 cancelled, 1118 closed 34216 GCS resources traversed, 0 cancelled 20096 GCS resources on freelist, 37877 on array, 37877 allocated set master node info Submitted all remote-enqueue requests Update rdomain variables Dwn-cvts replayed, VALBLKs dubious All grantable enqueues granted 35334 GCS shadows traversed, 16435 replayed, 1118 unopened Submitted all GCS remote-cache requests 0 write requests issued in 17781 GCS resources 0 PIs marked suspect, 0 flush PI msgs Sat Nov 16 23:52:30 2002 Reconfiguration complete
At this stage, the recovery process splits into two parallel phases while certain areas of the system are being made partially available; the second phase of the recovery begins.
-
Partial availability: At this stage of the recovery process the system is partially available for use. The blocks not in recovery can be operated on as before. Blocks being recovered are blocked by the resource held in the recovering instance.
-
Pass 2 recovery: The second phase of recovery continues, taking care of all the blocks identified during pass 1, recovering and writing each block, then releasing recovery resources. During the second phase the redo threads of the failed instances are once again merged by SCN and instead of performing a block level recovery in memory, during this phase the redo is applied to the data files.
-
Block availability: Since the second pass of recovery recovers individual blocks, these blocks are made available for user access as they are recovered a block at a time.
-
Recovery enqueue release: When all the blocks have been recovered and written and the recovery resources released, the system is completely available and the recovery enqueue is released.
During normal instance recovery operation, there is a potential that one or more (including the recovering instance) of the other instances could also encounter failure. If this happens, Oracle has to handle the situation appropriately, based on the type of failure:
-
If recovery fails without the death of the recovering instance, instance recovery is restarted.
-
If during the process of recovery the recovering process dies, one of the surviving instances will acquire the instance recovery enqueue and start the recovery process.
-
If during the recovery process, another non-recovering instance fails, SMON will abort the recovery, release the instance recovery (IR) enqueue and reattempt instance recovery.
-
During the recovery process, if I/O errors are encountered, the related fies are taken offline and the recovery is restarted.
-
If one of the blocks that SMON is trying to recover is corrupted during redo application, Oracle performs online block recovery to clean up the block in order for instance recovery to continue.
4. Media failures
Media failures comprise the failure of the various components of the database, such as data files, tablespaces, and the entire database itself. They occur when the Oracle file storage medium is damaged and prevents Oracle from reading or writing data, resulting in the loss of one or more database files. These failures could affect one or all types of files necessary for the operation of an Oracle database, including data files, online redo log files, archived redo log files, and control files.
The reasons for media failures could be bad disk, controller failures, mirrored disk failures, block corruptions, and power surge. Depending on the type of failure, a data file, tablespace, or the database controls the access to the database. The extent of damage to the specific area will determine the amount of time that the media would be offline and the access will be interrupted.
Database operation after a media failure of online redo log files or control files depends on whether the online redo log or control file is setup with multiplexing. Storing the multiplexed files on separate disks protects the copies from failures. For example, if a media failure damages a single disk of a multiplexed online redo log file, then database operation will continue from the other disk without significant interruption. On the other hand, if the files were not multiplexed, damage to the single copy of the redo log file could cause the database operation to halt and may cause permanent loss of data.
In the case of data files, failures could be categorized as read failures or write failures. Read failures are because Oracle is unable to read a data file; this causes an O/S level error message to be returned back to the application. On the other hand, if there are write failures, i.e., when Oracle cannot write to a data file, for example if the database is in ARCHIVELOG mode, then Oracle will return an error in the DBWR trace file and will take the data file offline automatically, and users will be allowed access to the remaining data files. If the write failure was against the system tablespace, the data file that maps to the tablespace is taken offline and the instance that encountered the error is shut down.
Write failures on a data file, when the database is not in ARCHIVELOG mode, cause the DBWR process to fail and this causes a crash on the instance. In this case, if the problem is temporary, then a crash or instance recovery will fix the instance and the instance is restarted. However, if the damage is permanent, the entire database would have to be restored from a most recent copy of the backup.
In a RAC environment, media failure could mean access to the database interrupted from one or more or all instances.
Recovery of media failures also depends on the type of media failure and accordingly either a data file recovery, tablespace recovery, or database recovery is performed.
Data file recovery
When the failure is at the data file level, normally caused by damage or corruption in the data file, a data file recovery is performed. Data file recovery is used to restore a file that is taken offline with immediate option because of an I/O error or to restore a file after disk failure.
The command used to recover a data file is:
SQL>recover datafile '<filename>'[filename2, filename3>;
Tablespace recovery
Tablespace recovery is the one form of media recovery that is specified at a logical level. This is because a tablespace is only related to the media via the data file. Tablespace by itself is an indirect reference or logical name given to one or more data files. Since tablespaces could be mapped to a data file during a tablespace recovery operation, Oracle queries the data dictionary to determine the tablespace to data file mapping. Up to 16 data files assigned to a tablespace can be recovered simultaneously.
The command used for tablespace recovery is:
SQL>recover tablespace <tablespace_name. (tablespace_name)...;
Database recovery
Recovery at this level recovers certain or all of the data files in a database. This operation could also be used to recover a damaged control file. A complete database recovery operation returns all data files and the control file to the same point in time through the redo application.
Database recovery is invoked by the following command:
SQL>recover database (until time 'xxxx'/change xxxx/cancel);
Database recovery could be a complete recovery, where the entire database is brought to the current point in time; or incomplete recovery, where the whole database is brought to a point behind the current time, after which, rolling forward to the same point restores all data files.
If the current or latest version of the control file is not available, database recovery can still be performed using the RESETLOGS option. Using this option will also bring the database to the current state. This is possible because when the database is opened with RESETLOGS, a comparison is done between the data files in the control file and those in the data dictionary table. If a data file is found to be in sys.file$ table but not in the control file, then an entry will be created for it in the control file with the name MISSINGnnnn, where nnnn is the file_id. The file will be marked offline as needing recovery. This file, if it exists, can then be renamed to its correct using the following syntax:
SQL>alter database rename file 'MISSINGnnnn' to '<file_name>';
Following this statement the data file is recovered and brought online.
Conversely, if the data file listed in the control file is not found by querying the sys.file$ table then it is removed from the control file.
Thread recovery
A thread is a stream of redo, for example, all redo log files for a given instance. In a single stand-alone configuration there is usually only one thread, although it is possible to specify more, under certain circumstances.
An instance has one thread associated with it, and recovery under this situation would be like any stand-alone configuration. What is the difference in a RAC environment? In a RAC environment, multiple threads are usually seen; there is generally one thread per instance, and the thread applicable to a specific instance is defined in the server parameter or int<SID>.ora file.
In a crash recovery, redo is applied one thread at a time because only one instance at a time can dirty a block in cache; in between block modifications the block is written to disk. Therefore a block in a current online file can read redo for at most one thread. This assumption cannot be made in media recovery as more than one instance may have made changes to a block, so changes must be applied to blocks in ascending SCN order, switching between threads where necessary.
In a RAC environment, where instances could be added or taken off the cluster dynamically, when an instance is added to the cluster, a thread enable record is written, a new thread of redo is created. Similarly, a thread is disabled when an instance is taken offline through a shutdown operation. The shutdown operation places an end of thread (EOT) flag on the log header.
Figure 12.4 illustrates the thread recovery scenario. In this scenario there are three instances, RAC1, RAC2, and RAC3, that form the RAC configuration. Each instance has set of redo log files and is assigned thread 1, thread 2, and thread 3 respectively.
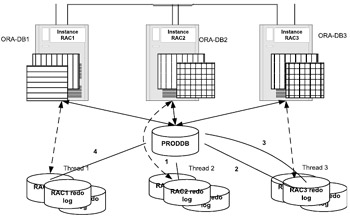
Figure 12.4: Thread recovery.
As discussed above, if multiple instances fail, or during a crash recovery, all instances have to synchronize the redo log files by the SCN number during the recovery operation. For example, in Figure 12.4, SCN #1 was applied to the database from thread 2, which belongs to instance RAC2, followed by SCN #2 from thread 3, which belongs to instance RAC 3, and SCN #3 also from thread 3, before applying SCN #4 from thread 1, which is assigned to instance RAC1.
Steps of media recovery
Oracle has to perform several steps during a media recovery from validating the first data file up to the recovery of the last data file. Determining if the archive logs have to be applied etc. is also carried out during this process. All database operations are sequenced using the database SCN number. Similarly, during a recovery operation, the SCN plays an even more important role because data has to be recovered in the order in which it was created.
-
The first step during the media recovery process is to determine the lowest data file header checkpoint SCN of all data files being recovered. This information is stored in every data file header record.
The output below is from a data file header dump and indicates the various markers validated during a media recovery process.
DATA FILE #1: (name #233) /dev/vx/rdsk/oraracdg/partition1G_3 creation size=0 block size=8192 status=0xe head=233 tail=233 dup=1 tablespace 0, index=1 krfil=1 prev_file=0 unrecoverable scn: 0x0000.00000000 01/01/1988 00:00:00 Checkpoint cnt:139 scn: 0x0000.06ffc050 11/20/2002 20:38:14 Stop scn: 0xffff.ffffffff 11/16/2002 19:01:17 Creation Checkpointed at scn: 0x0000.00000006 08/21/2002 17:04:05 thread:0 rba:(0x0.0.0) enabled threads: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 Offline scn: 0x0000.065acf1d prev_range: 0 Online Checkpointed at scn: 0x0000.065acf1e 10/19/2002 09:43:15 thread:1 rba:(0x1.2.0) enabled threads: 01000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 Hot Backup end marker scn: 0x0000.00000000 aux_file is NOT DEFINED FILE HEADER: Software vsn=153092096=0x9200000, Compatibility Vsn=134217728=0x8000000 Db ID=3598885999=0xd682a46f, Db Name='PRODDB' Activation ID=0=0x0 Control Seq=2182=0x886, File size=115200=0x1c200 File Number=1, Blksiz=8192, File Type=3 DATA Tablespace #0 - SYSTEM rel_fn:1 Creation at scn: 0x0000.00000006 08/21/2002 17:04:05 Backup taken at scn: 0x0000.00000000 01/01/1988 00:00:00 thread:0 reset logs count:0x1c5a1a33 scn: 0x0000.065acf1e recovered at 11/16/ 2002 19:02:50 status:0x4 root dba:0x004000b3 chkpt cnt: 139 ctl cnt:138 begin-hot-backup file size: 0 Checkpointed at scn: 0x0000.06ffc050 11/20/2002 20:38:14 thread:2 rba:(0x15.31aa6.10) enabled threads: 01100000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 Backup Checkpointed at scn: 0x0000.00000000 thread:0 rba:(0x0.0.0) enabled threads: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 External cache id: 0x0 0x0 0x0 0x0 Absolute fuzzy scn: 0x0000.00000000 Recovery fuzzy scn: 0x0000.00000000 01/01/1988 00:00:00 Terminal Recovery Stamp scn: 0x0000.00000000 01/01/1988 00:00:00
If a data file's checkpoint is in its offline range, then the offline-end checkpoint is used instead of the data file header checkpoint as its media-recovery-start SCN.
Like the start SCN, Oracle uses the stop SCN on all data files to determine the highest SCN to allow recovery to terminate. This prevents a needless search beyond the SCN that actually needs to be applied.
During the media recovery process, Oracle automatically opens any enabled thread of redo and if the required redo records are not found in the current set of redo log files, the database administrator is prompted for the archived redo log files.
-
Oracle places an exclusive MR (media recovery) lock on the files undergoing recovery. This prevents two or more processes from starting media recovery operation simultaneously. The lock is acquired by the session that started the operation and is placed in a shared mode so that no other session can acquire the lock in exclusive mode.
-
The MR fuzzy bit is set to prevent the files from being opened in an inconsistent state.
-
The redo records from the various redo threads are merged to ensure that the redo records are applied in the right order using the ascending SCN.
-
During the media recovery operation, checkpointing occurs as normal, updating the checkpoint SCN in the data file headers. This helps if there is a failure during the recovery process because it can be restarted from this SCN.
-
This process continues until a stop SCN is encountered for a file, which means that the file was taken offline, or made read-only at this SCN and has no redo beyond this point. With the database open, taking a data file offline produces a finite stop SCN for that data file; if this is not done, there is no way for Oracle to determine when to stop the recovery process for a data file.
-
Similarly, the recovery process continues until the current logs in all threads have been applied. The end of thread (EOT) flag that is part of the redo log header file of the last log guarantees that this has been accomplished.
The following output from a redo log header provides indication of the EOT marker found in the redo log file:
LOG FILE #6: (name #242) /dev/vx/rdsk/oracledg/partition1G_100 (name #243) /dev/vx/rdsk/oracledg/partition1G_400 Thread 2 redo log links: forward: 0 backward: 5 siz: 0x190000 seq: 0x00000015 hws: 0x4 bsz: 512 nab: 0xffffffff flg: 0x8 dup: 2 Archive links: fwrd: 3 back: 0 Prev scn: 0x0000.06e63c4e Low scn: 0x0000.06e6e496 11/16/2002 20:32:19 Next scn: 0xffff.ffffffff 01/01/1988 00:00:00 FILE HEADER: Software vsn=153092096=0x9200000, Compatibility Vsn=153092096=0x9200000 Db ID=3598885999=0xd682a46f, Db Name='PRODDB' Activation ID=3604082283=0xd6d1ee6b Control Seq=2181=0x885, File size=1638400=0x190000 File Number=6, Blksiz=512, File Type=2 LOG descrip:"Thread 0002, Seq# 0000000021, SCN 0x000006e6e496-0xffffffffffff" thread: 2 nab: 0xffffffff seq: 0x00000015 hws: 0x4 eot: 2 dis: 0 reset logs count: 0x1c5a1a33 scn: 0x0000.065acf1e Low scn: 0x0000.06e6e496 11/16/2002 20:32:19 Next scn: 0xffff.ffffffff 01/01/1988 00:00:00 Enabled scn: 0x0000.065acfa2 10/19/2002 09:46:06 Thread closed scn: 0x0000.06ffc03e 11/20/2002 20:37:25 Log format vsn: 0x8000000 Disk cksum: 0xb28f Calc cksum: 0xb28f Terminal Recovery Stamp scn: 0x0000.00000000 01/01/1988 00:00:00 Most recent redo scn: 0x0000.00000000 Largest LWN: 0 blocks Miscellaneous flags: 0x0
5. GCS and GES failure
The GCS and GES services that comprise the LMS, LMD, and GRD processes provide the communication of requests over the cluster interconnect. These processes are also prone to failures. This could potentially happen when one or more of the processes participating in this configuration fails, or fails to respond within a predefined amount of time. Failures such as these could be as a result of failure of any of the related processes, a memory fault, or some other cause. The LMON on one of the surviving nodes should detect the problem and start the reconfiguration process. While this is occurring, no lock activity can take place, and some users will be forced to wait to obtain required PCM locks or other resources.
The recovery that occurs as a result of the GCS or GES process dying is termed online block recovery. This is another kind of recovery that is unique to the RAC implementation. Online block recovery occurs when a data buffer becomes corrupt in an instance's cache. Block recovery could also occur if either a foreground process dies while applying changes or if an error is generated during redo application. If the block recovery is to be performed as a result of the foreground process dying, then PMON initiates online block recovery. However, if this is not the case, then the foreground process attempts to make an online recovery of the block.
Under normal circumstances, this involves finding the block's pre decessor and applying redo records to this predecessor from the online logs of the local instance. However, under the cache fusion architecture, copies of blocks are available in the cache of other instances and therefore the predecessor is the most recent PI for the buffer that exists in the cache of another instance. If, under certain circumstances, there is no PI for the corrupted buffer, the block image from the disk data is used as the predecessor image before changes from the online redo logs are used.
6. Instance hang or false failure
Under very unusual circumstances, probably due to an exception at the Oracle kernel level, an instance could encounter a hang condition, in which case the instance is up and running but no activity against this instance is possible. Users or processes that access this instance could encounter a hung connection and no response is received. In such a situation, the instance is neither down nor available for access. The other surviving instance may not receive a response from the hung instance; however, it cannot declare that the instance is not available because the required activity of the LMON process, such as writing to the shared disk, did not complete. Since the surviving instance did not receive any failure signal, it attempts to shut down the non-responding instance and is unable to because of the reasons stated above. In these situations the only opportunity is to perform a hard failure of either the entire node holding the hung instance or the instance itself. In either situation human interruption is required.
In the case of forcing a hard failure of the node holding the hung instance, the systems administrator will have to perform a bounce of the node; when the node is back up and alive the instance can be started.
In the case where the instance shutdown is preferred, no graceful shutdown is possible; instead, an operating-system-level intervention by shutting down one of the critical background processes such as SMON will cause an instance crash.
Recovery in both these scenarios is an instance recovery. All steps discussed in the section on instance failures apply to this type of failure.
[2]In the case of Linux and Windows clusters, an Oracle-provided CM is used and the heartbeat mechanism is wrapped with another process called the watchdog process provided by Oracle to give this functionality.
[3]The watchdog process is only present in environments where Oracle has provided the CM layer of the product, for example Linux.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174