| After seeing a JDBC example in this chapter and JDO throughout the book, you probably agree that the two APIs definitely "feel" very different to use. So what really makes this difference? JDO is a high-level API for transparent object persistence. The programmer can write Java code and work with Java objects as always. The data of the objects is almost automatically made persistent and can be reused in a different run of the application, can be queried, and possibly can be accessed by other applications. All this is achieved in a relatively transparent manner. You may have noticed that the JDO API does not make any explicit reference on what the specification calls the "datastore," the place where persistent objects are ultimately stored, queried, and retrieved from. In some cases, a developer chooses to use a relational datastore. In this case, the JDO implementation generates the required SQL statements and translates JDOQL queries into SQL. This specific combination is often referred to as "object/relational mapping." The developer uses objects, and some framework transparently maps access to objects into the relational world. [5] Object/relational (O/R) mapping tools for Java existed before JDO; see the second part of Appendix E of this book. Before JDO was standardized, each tool used its own proprietary persistence API. [5] Names of tables and columns in the relational database are usually set in an XML mapping descriptor. This allows you to easily change SQL table and column names , independently of the Java class and field name . The current JDO specification (1.0) does not standardize the format of this mapping description, in the interest of staying 100 percent datastore-neutral, and each vendor uses a similar but slightly different syntax. This may change with future releases of the JDO specification. This datastore independence allows developers to switch to a different datastore, e.g., an object database, or an in-memory only store, or maybe a pure XML database. [6] Because JDO completely hides the SQL coding from the programmer, SQL generation is happening behind the scenes. There usually is no SQL in the business application itself. [6] At the time of this writing, the authors were not aware of any commercially available JDO implementation using a pure XML database as a datastore; however, this may be only a question of time. JDBC, on the other hand, is a lower-level API designed specifically to access relational databases, and at no point attempts to "hide" the relational database in any way. In JDBC, developers explicitly code things like "update this information stored in this column of that table." This is done using another language: SQL. Statements written in the SQL language are spread throughout the Java code as Strings and are sent to a RDBMS via JDBC. SQL really has nothing to do with the language that was chosen to develop an application in Java. This " disjoint " is often referred to as "impedance mismatch." The two APIs were clearly designed with different goals in mind, and although both serve to "persist data" on a high-level, in practice they use fairly different means of achieving this goal. In this way, there is limited scope for direct comparison. The following sequence of diagrams further illustrates the difference. The UML class diagram in Figure 12-2 shows some domain classes of a typical small application. Figure 12-2. UML class diagram. 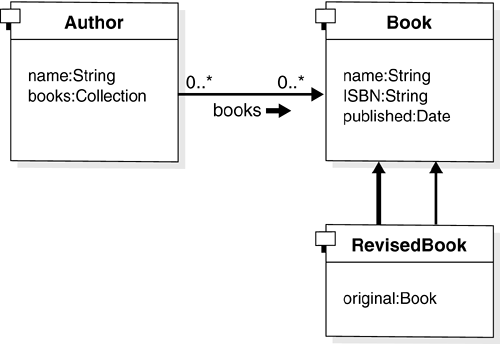 This illustration represents the Java object-oriented view of the business domain: A Book has an ISBN number, here modeled as a field of type String , so the Book class generally has setISBN() and getISBN() methods . Some books are special; they are subclasses of general books, so there is a RevisedBook Java subclass that inherits from Book . Authors publish books, so the Author class has a books field with, for example, a getBooks() method that returns some java.util.Collection of persistent Book objects. A new author can created using the new Author() constructor, just like any other object in Java is instantiated : Author author1 = new Author(); author1.setName("Donald Duck"); pm.makePersistent(author1); Using JDO, working with authors and books in a persistent database means working directly with these persistent domain objects. The JDO API is used for calls like makePersistent() and executing queries expressed via a query language (JDOQL) that is syntactically very close to Java code syntax. JDOQL can, for example, use navigational expressions and familiar methods like Collection.contains() , Collection.isEmpty() , String.startsWith() , and so on. For example: String filter = " original.name == \"Donald Duck\""; Query query = pm.newQuery(RevisedBook.class, filter); Collection result = (Collection) query.execute(); revisedBook = (RevisedBook) result.iterator().next(); query.close(result); With JDO, it really doesn't (have to) go much beyond the few lines shown. Write a domain model with Java classes, create new persistent instances, work with them as if they were good-old plain simple Java objects, and use JDOQL to find collections of them. Many JDBC-only based business applications today also have domain data object classes similar to the above example in the Java application. However, to work with authors and books in a persistent database in this case means working on a different view, that of relational databases. The logical ER diagram in Figure 12-3 illustrates how authors and books live in an RDBMS. Figure 12-3. Logical ER (entity-relationship) diagram. 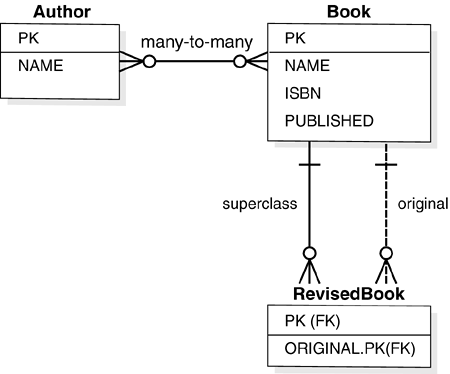 Although this logical diagram may look fairly similar to the UML class diagram, JDBC code works with SQL at the level of a physical ER diagram, where what's expressed as a "many-to-many" relationship in a relational model becomes the intermediate AUTHOR_BOOK table, and where Strings are VARCHAR s. In Figure 12-4, there are no object relationships or queries "following" an object reference. There are only tables, with rows and INSERT , columns and SELECT , object references that become NUMBER types, and SQL queries to be formed with JOIN and other SQL keywords. In which model would you rather work? Figure 12-4. Physical ER (entity-relationship) diagram (e.g., for Oracle). 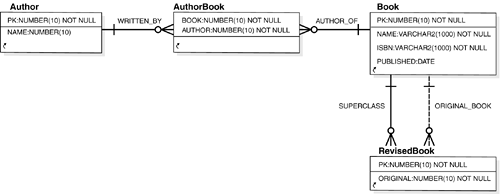 In review, JDO scores much higher on programmer convenience. JDO hides SQL from the programmer; that is, a developer using the Java programming language does not need to learn SQL. On the other hand, the JDBC API provides greater control by giving programmers direct access to the relational database access. 12.3.1 Feature comparison of JDBC versus JDO This section provides a brief one-on-one feature comparison of JDBC and JDO, insofar as the two APIs can actually be compared. They were designed for different purposes, as is evident in Table 12-1. Table 12-1. Feature Comparison of JDBC and JDO | Feature | JDBC (alone) | JDO | | Transparent object persistency | No | Yes | | Object references support | No | Yes | | Persistence by reachability | No | Yes | | Class inheritance support | No | Yes | | Transactional (JTS/JTA) | Yes | Yes [*] | | Lazy/deferred/partial loading | No, manual | Yes | | Locking | Manual | Automatic [*] | | Standard Java API | Yes, java.sql ( core package) | Yes, javax.jdo (extension package) | | Platforms applicable | J2SE and J2EE [  ] ] | J2SE, J2EE, and J2ME ready | | Formally part of J2EE | Yes | No, but... not an issue [  ] ] | | Maturity | Fairly mature | Recent, but rapidly adopted | | Developer community | Large | Small, but growing | | Compile-time type checking | Limited | Better | | Connection pooling possible | Yes | Yes | | Data caching | None | Usually yes, various [*] | | Scalability | Limited | Cluster with distributed cache [*] | | Datastores | Relational only | Independent API, today often relational or native object, basically completely open , including EAI | | Query language | SQL only | JDOQL, possibly others (SQL [*] ) | | DDL / metadata access | SQL / yes | No, datastore dependant | | RDBMS views, stored proc. | Yes, sure | No, but [*] | | Renaming tables and columns | Often hard-coded | Easily changed in descriptors [*] | | Persistence- related code | Often scattered and intermixed with application business logic [ §] | Separate by design | [*] JDO implementation-dependent. [ ] JDO fits into the larger J2EE picture as a JCA resource adapter. [ ] JDBC cannot be used on the Java Micro Edition (J2ME) platform. However, a similar but much simplified vaguely similar API is available on J2ME devices. [ §] Unless elaborate design patterns such as DAO are implemented. Although it is technically possible to cleanly separate persistence-related code from domain model and business logic classes, the point is that with direct JDBC programming, this requires good architecture and discipline. With JDO, the separation comes for free, out of the box. It is only natural that JDO, as an emerging Java technology, has a smaller experienced user base than JDBC, which has been around since almost the beginning of Java and has been widely used. However, as mentioned, JDO merely standardizes an API for transparent object persistency, for which products have existed for some time. Senior enterprise developers often have knowledge of previous O/R products and are able to adopt JDO easily. Junior developers usually find JDO easy to adopt because it's intuitive and by design extremely close to "normal" Java. Sometimes people realize that they have actually been writing an in-house persistent framework and are keen to jump on a now standardized API. In summary, for many Java applications, technologies that solve the impedance mismatch between an Object Model and a Data Model are of strong interest, and are often redeveloped in one form or the other in many projects. Transparent persistency, persistence by reachability, object/relational (O/R) mapping, lazy/deferred/partial loading, and caching are highly desirable features for many applications. JDO-compliant implementations provide these features out of the box and are an interesting alternative to direct JDBC programming. 12.3.2 Misconceptions about JDBC and JDO Because JDO takes a different approach to persistence than JDBC, misunderstandings often come up in related discussions. The next few pages shall address some of them, namely: Is JDO a replacement for JDBC? Is JDO slower/faster than JDBC? How datastore independent is JDO really, and how easy is it to switch between different types of relational datastores? 12.3.2.1 JDO is not a replacement for JDBC You may be thinking, "Using JDO, I can completely forget about JDBC!" We say: Be careful. Although it is true that JDO allows you to develop simple applications entirely without reference to the JDBC API in the application code, you may want to think twice before throwing away your JDBC and SQL documentation. First, as long as you are in an O/R mapping scenario where you want to use a relational database as the final datastore for your JDO-based application, you or at least some people on a project's development team will still be dealing with Connection URLs or Data Sources, JDBC drivers, Connection Pools, and the like. In this scenario, JDO does not really replace JDBC; rather, it isolates business application developers from its details, allowing them to code at a higher level, while a JDO implementation internally still uses JDBC and a JDBC driver to access the relational datastore at the lower level. (Think of this as a bit like using JSPs at a higher level that simplifies Servlet programming, even though JSPs are still translated into Servlets; similarly, in JDO many operations ultimately lead to JDBC calls.) Of course, if you use a non-relational datastore, this will be different. Second, for more sophisticated enterprise applications, sometimes a mix of JDO with special cases relying on some JDBC is required. You may well hang onto those PreparedStatements and ResultSets for specific modules of your applications for some time to come. Regarding mixed use, see the section "When to use JDBC" later in this chapter for more details. Last but not least, it is certainly useful to have a sound understanding of JDBC should you need to troubleshoot any issues with an O/R-based JDO implementation. Figure 12-5 shows a typical system architecture for a solution running inside an application server, where some business logic uses the JDO API, which in turn uses the JDBC API internally. Figure 12-5. Layers of a typical Web-based application when using JDO on a relational JDBC-based datastore within an application server. 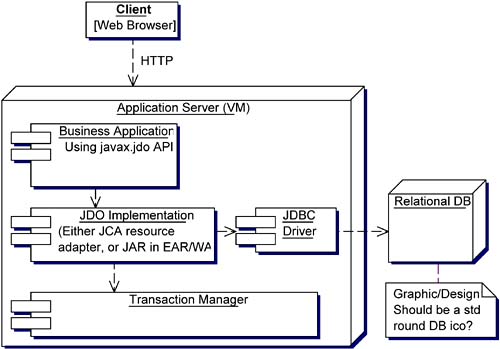 It is best to think about JDO as a complementary technology to JDBC, both with unique strengths, usable by programmers with different skill sets and applicable to projects or modules of projects with different development objectives. 12.3.2.2 Performance Now you may be thinking "JDBC is faster than JDO." But you'll find that is not necessarily so. To compare the performance of a JDO-based application with a JDBC-based application, much depends on the actual application scenarios, specific use-case, and details of how JDBC is used. Here are some of the factors that contribute to the performance discussion: -
Mapping: When reading and writing persistent objects from and to a datastore, a JDO implementation is usually required to do some sort of mapping between the Java instances and the objects in the datastore. For example, when using a relational JDBC-based datastore, at some point in time a JDO implementation will have received a ResultSet internally and will want to set the fields of a persistent object from it. Although this mapping always consumes time, what's more important is that during the mapping, data that the application may not need may unnecessarily be read or written and mapped. Depending on the sophistication of an alternative JDBC-based application, this point can actually come out in favor of JDO, instead of against it (see the next item). Furthermore, this applies to relational datastores; other JDO implementations that are, for example, using an object database as a datastore may have a simpler (or no) mapping function, and this point does not apply. In the overall performance picture, mapping does not generally lead to a significant performance penalty, taking into account that many JDBC-based applications include some sort of mapping, sometimes more hidden (i.e., spread all over the code) or more explicit (if using home written) in application code. -
Unnecessary reading: When reading data from a datastore, performance obviously depends on how much data is read and how. A JDBC-based application may use a specific SQL statement for each specific read access, or some more generic ( SELECT *, JOIN in case we may need the data later) construct. JDO implementations, on the other hand, are able to fetch data only from a datastore that is actually required, thus minimizing database hits and network traffic. Today, this is usually implemented using a technique referred to as Deferred Reading, wherein a JDO implementation fetches some data only initially (see the default-fetch- group field of the field tag in JDO XML metadata descriptors) and fill in other fields only later, only if actually accessed. More sophisticated mechanisms can be envisioned ”e.g., a Prefetch API that is being discussed for future versions of the JDO standard. This would allow an application to specify a policy whereby instances of persistence-capable classes are prefetched from the datastore when related instances are fetched . Similarly, automatic detection of reading patterns to optimize fetching may be available in advanced JDO implementations. The bottom line of this point is "it depends." Performance could be in favor of JDO versus a simple generic JDBC application, or against JDO versus a sophisticated JDBC application with different handcrafted specific queries. However, JDO generally wins for simplicity: For the same performance, a JDO application developer does not have to be concerned with datastore fetch details. With JDBC, the developer writes the SQL code and has to think ahead about unnecessary reads. -
Unnecessary writing: When writing data to a datastore, most JDO implementations today are able only to write modified fields, because they automatically keep track of write access to fields of persistent objects. Furthermore, if optimistic transaction management is used, many JDO implementations are able to "batch" writes, to avoid writing fields that are changed again within the same transaction, to avoid any datastore roundtrip if a transaction is aborted, and other optimizations based on leveraging the in-memory object model and cache. These points can again contribute to minimizing database cycles and network traffic. -
Caching: By far, the most important aspect of performance discussions between JDO and straight JDBC is caching, as any experienced developer will confirm. Most JDO implementations keep a global cache of objects, according to different implementation-specific and often configurable caching strategies. Therefore, many JDO implementations do not read and map an object previously fetched again, because it is kept in a memory cache in the JVM. For a JDO application developer, this caching is fully transparent; there is no "load this from cache instead of from datastore," and so on, code in the application. Again, the performance impact of this depends on the actual application, amount of data, available memory, and use-case; in general, however, this leads to a huge performance benefit in favor of JDO. The usual JDBC application sends a new query statement each time data is required. Using prepared statements and similar "optimizations" are of minimal impact in the bigger picture of having an actual domain object cache in memory. There is little to no performance penalty for using a cache; however, there is an impact on memory requirements. Of course, all the above points regarding performance could be implemented in one form or the other in a JDBC-based application as well; they are not technically specific to JDO only. However, your general JDBC applications often won't implement caching, lazy load/write, and so on, strategies. If they do, you have in fact developed an in-house persistence layer that's similar to what's now available in various JDO implementations, according to a standard API. See the "build versus buy" discussion in Chapter 2 for more about this. 12.3.2.3 Database independence Okay, maybe you're thinking, "JDBC abstracted differences between relational databases, and now JDO abstracts even access to non-relational datastores." Let's have closer look at the details: -
Although the SQL 92 standard exactly defines the syntax of the SQL language, and a simple " SELECT * FROM table " certainly works across all relational databases, vendors often implement more advanced requirements differently. Sometimes seemingly trivial issues like maximum table and column name length can cause troubles in projects that need to work across different relational databases. Often, such differences end up being accounted for in the Java code of the business application or in some database abstraction layer written in-house. Although JDBC driver classes abstract (necessarily, because there is no standard) the product-specific client/server connection protocol details (e.g., Oracle OCI, MySQL port 3306 protocol, and so on), JDBC does not make any attempt to "translate" SQL code. [7] JDO implementations, however, translate the datastore-independent JDO query language (JODQL) according to the underlying datastore, and can and do take slight SQL differences into account and map accordingly (for example, differences in OUTER JOIN syntax between major relational database vendors). [7] The JDBC 3.0 Specification suggests that "Because scalar functions are supported by different DBMSs with slightly different syntax, it is the driver's job either to map them into the appropriate syntax or to implement the functions directly in the driver." In practice, however, most JDBC drivers ”even from established vendors ”do not seem to respect such requirements as of today. -
The O/R mapping-based JDO implementations often provide this database product abstraction layer; it is in fact not unusual to find some sort of implementation-specific "database type" configuration property. Most JDO implementations also list which relational databases their implementation has been explicitly tested and approved against. So to switch from one relational database to another ”for example, from a simple Java embedded database running in the same VM to a full-fledged remote relational database from one of the leading vendors ”the same JDO implementation, configured differently, can often be used without too much trouble. Although such claims naturally sound suspicious to anyone who has tried this with JDBC and become disappointed, this does generally work fairly well with JDO in practice. For these reasons, using different relational databases from one project is easy with JDO, which hides possibly database vendor-specific SQL in favor of a data-store-neutral query language, than with JDBC. If non-relational datastores, such as object databases, are a possible future target, JDBC is not an option as persistence API anyway. Switching JDO Implementation to Switch Datastore? Sometimes a switch from one type of datastore to another one ”for example, from a relational datastore to a scalable object database datastore ”requires a switch in the JDO implementation that you have chosen. As the market stands today, JDO implementations are relatively clearly split into "for relational database" and "for (often the same vendor's) object databases" products. Of course, switching JDO implementation without rewriting code is possible only if the standard JDO API has been used; using non-standard JDO extensions "locks" you into that particular implementation. As long as only the standard API has been used, switching implementation is generally relatively easy, because the JDO specification is specific and strict, and implementations can pass a technology compatibility kit (JDO TCK) from Sun. |
12.3.3 When to use JDBC after all Some applications may need to implement use-cases where JDBC is required after all. Often, these are not your trivial example applications, but some medium to complex solutions. Broadly, this situation often falls into one of these cases: -
Specific SQL queries that cannot be expressed in JDOQL. -
Need to use existing, often vendor-specific, relational datastore features. -
Data-centric, processing intensive , performance-sensitive (batch) applications. -
Existing relational database schemas, potentially complex and not modifiable. 12.3.3.1 SQL queries It is important to understand that the JDO standard query language, JDOQL, does not attempt to be a drop-in replacement for SQL. Its aim is not to be capable of expressing any SQL query one can possibly think of. The most common and widely used SQL statements ”such as INSERT , UPDATE , SELECT , and DELETE ”of course have their equivalents in the JDO API, as well as many SELECT options such as WHERE and ORDER BY have equivalents in JDOQL. Similarly, the BEGIN , SET TRANSACTION , COMMIT , ROLLBACK , and related keywords have equivalents as JDO Transactions. [8] [8] These transaction-related statements are never issued as such even in JDBC; the JDBC driver usually issues these (or uses another DB-proprietary transaction demarcation mechanism) after each individual SQL statement as soon as it is complete, if auto-commit is enabled, or when the client code calls Connection.commit() or Connection.rollback() if auto-commit is disabled on the Connection. Other SQL constructs, however, have no direct equivalent in the JDO API or JDOQL. This is "a feature, not a bug," in the sense that JDOQL was conceptually not meant to suit such needs. And although minor extensions may be made in the future, most of such constructs probably will never be expressible using JDOQL. These include the following: -
SELECT options like GROUP BY and HAVING (and aggregate functions such as AVG , COUNT DISTINCT , MAX , MIN , SUM ) have no direct equivalent in JDOQL. -
SELECT options JOIN , IN , and EXISTS as well as subqueries do not directly translate into JDOQL. However, sometimes these SQL operations, particularly IN and JOIN , may not be required to express the same goal in JDOQL, simply because it's closer to the object model. A good example for this is JOIN operations in typical relational database applications on helper tables used to express multi-multi (M:N) relationships. In a JDO model, this is expressed as Collection fields of the respective data object, and queried using contains() operations or simple navigation through a reference field, which gets translated to the correct JOIN operations in SQL, if running on a relational datastore. At the JDOQL level, explicit mention of the intermediate tables and JOINs is simply not required anymore. Still, sometimes such an SQL query cannot be translated into JDOQL. -
Unions and intersections ( SELECT UNION/INTERSECT/EXCEPT SELECT constructs) cannot be expressed directly in JDOQL. These SQL keywords are not formally part of the SQL standard. Similarly to the above comment, the same goal can often be achieved differently using JDO. Specifically, sometimes such constructions are used to "hack" in SQL what would be correctly modeled as class inheritance in a JDO application. -
Some operators, most importantly string functions like the SQL LOWER , UPPER , SUBSTRING , TRIM , and LIKE , as well as case-insensitive string comparisons, are not standardized by the JDOQL specification, which mandates only support for the String.startsWith() and String.endsWith() methods. However, O/R-based JDO implementations frequently provide extensions to use these operators. Make sure that you understand and highlight in your code when you are using such implementation-specific extensions. Future releases of the JDO specification may define more supported String methods for JDOQL query filters. -
SQL commands, like CALL for stored procedures or TRIGGER-related functions, are not covered by JDO. These statements are often database-specific . -
Last but not least, schema manipulation statements such as CREATE / ALTER / DROP of TABLE , INDEX , and so on, are not directly supported by the JDO specification. These Data Definition Language (DDL) statements are not usually executed at the runtime of an application, but during development and build. O/R-based JDO implementations usually provide tools that create and/or upgrade the required database schema, which do issue these statements. When looking at an existing application with SQL code and evaluating JDO migration, it is important to work on a query-by-query basis, before prematurely concluding something like "this application has queries that are too complex and that cannot be expressed in JDOQL." If, after all, your application does requires some SQL, this is not necessarily a reason for the entire application to be written using JDBC instead of JDO. In practice, there are three basic choices to use SQL queries in JDO applications: -
Use JDBC API to execute SQL query in an otherwise JDO-based application. If transactional semantics across calls into the two APIs need to be ensured, this is possible to achieve. -
Use JDO standard to send off a pure SQL query via the JDO API. As seen in Chapter 6 about JDOQL queries, the JDO specification deliberately lets a developer specify the query language when creating a JDO Query object, and although it usually is JDOQL, several implementations available today offer the possibility to "pass through" full SQL code. (Note that the expected result set still generally must be a collection of persistent objects.) -
Use JDO implementation-specific extensions to mix JDOQL and SQL syntax in one and the same query filter. Similarly, use a JDO implementation-specific API to develop custom query expressions. For example, this can be used with some implementations to "pass through" relational datastore-specific SQL query hints or operators, if really needed. 12.3.3.2 Specific relational datastore features Regarding the use of specific relational datastore features, often vendor proprietary SQL extensions or entire applications, consider this example: A document/content management solution wants to use JDO. It will have domain classes to represent Document, Author, Version, and so on. However, it also needs to interface to a database-specific full-text indexing engine, for which vendor-specific SQL calls are required. This in itself is not a reason to develop the entire application in JDBC; it is perfectly legal to use JDBC/SQL for that part of your application. As explained above, the choices are either to use SQL as an alternative query language from the JDO API, if the JDO implementation chosen permits this, or simply through good old real JDBC API calls. See below for an example of how to correctly use both APIs mixed to perform transactional work. 12.3.3.3 Data-centric applications versus domain-model centric Other than these technical issues, it is sometimes also argued that although JDO is great for domain-model centric applications, other applications lend themselves more for JDBC than JDO. For example, heavily data-centric processing, including decision support, ad hoc query, and reporting applications may want to offload processing using existing relational database features. 12.3.3.4 Existing legacy relational database schemas Some applications are required to work on an existing legacy database schema. If such database schemas are actually complex relational database "applications" ”for example, using SQL views (instead of direct SELECT on underlying tables) and stored procedures (instead of direct INSERT ) to access data ”raw JDBC may be a better fit than JDO. Although some implementations do claim to actually support stored procedures, for example, it is generally not possible to "map" an arbitrary complex relational schema to an object world. However, simpler and more straightforward existing database schemas may be understood and correctly mapped by a good JDO implementation. For example: -
Identity mapping: Just because the standard schema generator of your JDO implementation of choice generates an automatically incrementing sequence number as primary key does not mean that it could not also use a FirstName / LastName pair that models the primary key in an existing schema. This could be modeled with a multi-field Application Identity class in JDO. -
Simple field mapping: Although String fields usually are mapped to VARCHAR columns, int , to NUMBER columns, and so on, most JDO implementations can be flexible about this. For example, mapping a VARCHAR(1) column with 'Y' / 'N' in a table to a Boolean is usually possible. Often, more complex mappings (using application-provided translators) can be implemented. -
Collection field mapping: In relational modeling, either a one-to-many or a many-to-many mapping expresses what in a Java class model is usually written as a Collection-type field. With a one-to-many mapping, the persistent objects contained in the collection are linked to exactly one containing object (or none), but never more than one; this is modeled with a foreign key on the contained records associating to the containing record and corresponds to what UML refers to as an aggregate link. With a many-to-many mapping, the persistent objects added to the Collection-type field can be linked by many of the same objects; this is modeled with an intermediate table holding the foreign keys of both records. Because a pure Java class model does not (need to) distinguish between these two cases, most O/R-based JDO implementations by default use a many-to-many mapping for Collection-type field. However, most JDO implementations are perfectly able to work with a one-to-many mapping as well. (The relational one-to-one mapping is less ambiguous and simply corresponds to a persistent object reference in the respective class.) -
Inheritance mapping: Another area is relational schemas, which use the same primary-key values in more than one table, aiming at expressing some sort of "this record actually is an 'extension' of that record" relationship. Although this could be mapped into two separate classes with an association, such relational structures often map well into a class model using inheritance. -
JDO specific tables and columns: O/R-mapping implementations often require extra tables or columns ”for example, a column on each table to keep an incrementing locking value used to implement optimistic transaction management, and one holding the name of the class of a persistence object used to properly interpret subclasses. If such columns are not part of an existing schema, some implementations permit disabling their usage if the required feature (e.g., optimistic transactions or subclassing) is of no interest. Some O/R-based JDO implementations provide schema reverse engineering tools, promising to generate Java classes and JDO metadata with mapping information from an existing database schema. This could greatly simplify (or at least support) such a mapping process as outlined above, as opposed to manual configuration. Last but not least, consider that it may be quite acceptable to enhance an existing schema for a new application without changing its structure. For example, the point on JDO-specific columns would really only apply if the legacy schema is completely non-modifiable, which may not always be the case. For example, slight additions to a database may be acceptable. Sometimes, even more profound schema changes of a legacy database may be perfectly acceptable. For example, if no legacy application continues to use it in parallel with a new JDO-based application, then the schema can be completely adapted and the data migrated , thus easily used with JDO anyway. The above few paragraphs should have illustrated that even if a legacy schema cannot be changed, it may be worth investigating whether a JDO implementation can actually work with that schema. It should be expected that this area will see some interesting developments in the future, with JDO implementations becoming more mature and able to tackle some of the issues. Data Access by Other Applications Sometimes, it is not the application to be developed that is the element causing doubt between a JDO versus a JDBC choice, but rather existing external applications that should interface with the application to be written. Reporting tools are a typical candidate. Most industry-standard reporting tools today access data at the relational level, via JDBC or other relational APIs like ODBC or native drivers, and are only slowly beginning to gear up to be able to leverage object domain model representations of business data. However, this should generally not prevent a new application from being written in JDO, because if a relational datastore is chosen, other applications are still perfectly able to access the data. This system architecture is sketched out in Figure 12-6 below. Figure 12-6. JDO application and another application both accessing relational datastore. 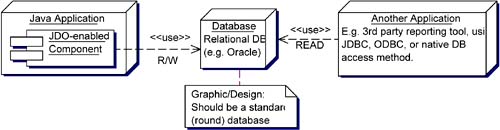 This approach generally works well, particularly if only read access is required, as is usually the case for reporting tools. The case data structures from JDO need to be simplified for human report designers ”for example, when using several tables for inheritance mapping ”then creating some SQL views for the non-JDO application may simplify things. However, if the other application requires write access to the same data, the scenario can get more complex because of cache synchronization. This issue, however, is not strictly related to JDO and would equally arise with a JDBC-based application that attempted to cache data. Possible solutions include disabled caches, which is perfectly possible with many JDO implementations, or some sort of manual cache refreshing or synchronization. |
12.3.4 When to use JDO and JDBC in an application You may sometimes wish to use JDO code mixed with some JDBC. Although such a mixed architecture should be avoided unless there is a good reason for it and it severely limits portability to another datastore (among other issues), it is technically possible. One approach is to use implementation-specific API extensions to use SQL instead of (or mixed with) JDOQL as query language, as described above. Another road, depending on why the application desires to use a mixed architecture, is to use a JDO implementation-specific method to obtain the JDBC Connection generally from a JDO PersistenceManager , among other things. A different road, and, as opposed to the above, a portable and clean (albeit slightly more complicated) architecture is to perform work within the same transaction in a portable manner. Both JDO and JDBC calls can be made within a JTA UserTransaction in a managed environment. Chapter 11 explains this topic and its background, shows how to obtain a PM inside a JTA transaction, and presents a complete example illustrating how to use JDO alongside another transactional resource such as JDBC.  |