216.
| [Cover] [Contents] [Index] |
Page 292
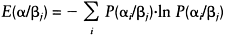 |
(7.32) |
and the overall measure for all observed data classes and information classes can be expressed as:
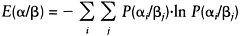 |
(7.33) |
It should be noted that, as entropy is being used to quantify the relationship between data classes and information classes, the higher the value, the less weight should be allocated to the data source.
The methodology discussed above only provides a rough estimation of data source weighting parameters. One has to determine a mapping function to convert the measured results into the weighting parameters. It is not always easy to define such a mapping function, and the determination of weighting parameter still relies on the analyst’s ad hoc decisions, which cannot guarantee to obtain an optimal solution. Moreover, when the MRF-MAP estimate is attempted, the parameter selection issue will become more complicated because both weighting and potential parameters have to be determined simultaneously.
A straightforward approach to achieve optimal parameter assignments is to perform an exhaustive search of the total parameter space and then select the best solution. Searching for the best combination of weights can be time-consuming. For example, if there are ten data sources, and if the weights are defined within the range [0, 1] with steps of 1/256, the total search space will be 25610. A more efficient search tool is needed in order to reduce the computational cost. The genetic optimal search algorithm (Holland, 1975; Goldberg, 1989) appears to be a good tool for locating optimal solutions.
7.5.4 The genetic algorithm
Many practical search and optimisation problems require the investigation of multiple maximum or minimum. Genetic algorithms (GA) have been increasingly used in solving such problems, and their general performance has been empirically shown to be robust (Holland, 1975; Goldberg, 1989). The central concept of GA is based on the mechanics of natural selection and natural genetics. GA operates by maintaining a set of trial structures, forming a population. Each trial structure is a finite length string and generally is represented through special coding techniques (such as grey code or binary code). Once the trial structure has been determined by the user, the GA then starts a series of search processes within which, at each generation,
| [Cover] [Contents] [Index] |
EAN: 2147483647
Pages: 354