9.2 Merged Join and Filter Indexes
| The method I've explained so far points you to the best join order for a robust execution plan that assumes you can reach rows in the driving table efficiently and that you have all the indexes you need on the join keys. Occasionally, you can improve on even this nominal best execution plan with an index that combines a join key and one or more filter columns . The problem in Figure 9-4 illustrates the case in which this opportunity arises. Figure 9-4. A simple three-way join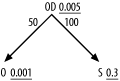 The standard robust plan, following the heuristics of Chapter 6, drives from O with nested loops to the index on OD 's foreign key that points to O . After reaching the table OD , the database discards 99.5% of the rows because they fail to meet the highly selective filter on OD . Then, the database drives to S on its primary-key index and discards 70% of the remaining rows, after reading the table S , because they fail to meet the filter condition on S . In all, this is not a bad execution plan, and it might easily be fast enough if the rowcount of OD and the performance requirements are not too high. However, it turns out that you can do still better if you enable indexes that are perfect for this query. To make the problem more concrete, assume that Figure 9-4 comes from the following query: SELECT ... FROM Shipments S, Order_Details OD, Orders O WHERE O.Order_ID=OD.Order_ID AND OD.Shipment_ID=S.Shipment_ID AND O.Customer_ID=:1 AND OD.Product_ID=:2 AND S.Shipment_Date>:3 Assuming around 1,000 customers, 200 products, and a date for :3 about 30% of the way back to the beginning of the shipment records, the filter ratios shown in the diagram follow. To make the problem even more concrete, assume that the rowcount of Order_Details is 10,000,000. Given the detail join ratio from Orders to Order_Details , the rowcount of Orders must be 200,000, so you would expect to read 200 Orders rows, which would join to 10,000 Order_Details rows. After discarding Order_Details with the wrong Product_ID s, 50 rows would remain in the running rowcount. These would join to 50 rows of Shipments , and 15 rows would remain after discarding the earlier shipments. Where is the big cost in this execution plan? Clearly, the costs on Orders and Shipments and their indexes are minor, with so few rows read from these tables. The reads to the index on Order_Details(Order_ID) would be 200 range scans, each covering 50 rows. Each of these range scans would walk down a three-deep index and usually touch one leaf block for each range scan for about three logical I/Os per range scan. In all, this would represent about 600 fairly well-cached logical I/Os to the index. Only the Order_Details table itself sees many logical I/Os, 10,000 in all, and that table is large enough that many of those reads will likely also trigger physical I/O. How can you do better? The trick is to pick up the filter condition on Order_Details before you even reach the table, while still in the index. If you replace the index on Order_Details(Order_ID) with a new index on Order_Details(Order_ID, Product_ID) , the 200 range scans of 50 rows each become 200 range scans of an average of just a half row each.
With this new index, you would read only the 50 Order_Details rows that you actually need, a 200-fold savings on physical and logical I/O related to that table. Because Order_Details was the only object in the query to see a significant volume of I/O, this change that I've just described would yield roughly a 50-fold improvement in performance of the whole query, assuming much better caching on the other, smaller objects. So, why did I wait until Chapter 9 to describe such a seemingly huge optimization opportunity? Through most of this book, I have implied the objective of finding the best execution plan, a priori , regardless of what indexes the database has at the time. However, behind this idealization, reality looms: many indexes that are customized to optimize individual, uncommon queries will cost more than they help. While an index that covers both a foreign key and a filter condition will speed the example query, it will slow every insert and delete and many updates when they change the indexed columns. The effect of a single new index on any given insert is minor. However, spread across all inserts and added to the effects of many other custom indexes, a proliferation of indexes can easily do more harm than good. Consider yet another optimization for the same query. Node S , like OD , is reached through a join key and also has a filter condition. What if you created an index on Shipments(Shipment_ID, Shipment_Date) to avoid unnecessary reads to the Shipments table? Reads to that table would drop 70%, but that is only a savings of 35 logical I/Os and perhaps one or two physical I/Os, which would quite likely not be enough to even notice. In real-world queries, such miniscule improvements with custom indexes that combine join keys and filter conditions are far more common than opportunities for major improvement.
When you find that an index is missing on some foreign key that is necessary to enable a robust plan with the best join order, it is fair to guess that the same foreign-key index will be useful to a whole family of queries. However, combinations of foreign keys and filter conditions are much more likely to be unique to a single query, and the extra benefit of the added filter column is often minor, even within that query. Consider both the execution frequency of the query you are tuning and the magnitude of the tuning opportunity. If the summed savings in runtime, across the whole application, is an hour or more per day, don't hesitate to introduce a custom index that might benefit only that single query. If the savings in runtime is less, consider whether the savings affect online performance or just batch load, and consider whether a custom index will do more harm than good. The cases in which it is most likely to do good look most like my contrived example:
When you find a large opportunity for savings on a query that is responsible for much of the database load, these combined key/filter indexes are a valuable tool; just use the tool with caution. |
