5.2 Full Query Diagrams
| Example 5-1 is a simple query that illustrates all the significant elements of a query diagram. Example 5-1. A simple query with one joinSELECT D.Department_Name, E.Last_Name, E,First_Name FROM Employees E, Departments D WHERE E.Department_Id=D.Department_Id AND E.Exempt_Flag='Y' AND D.US_Based_Flag='Y'; This query translates to the query diagram in Figure 5-1. Figure 5-1. A full query diagram for a simple queryFirst, I'll describe the meaning of each of these elements, and then I'll explain how to produce the diagram, using the SQL as a starting point. 5.2.1 Information Included in Query DiagramsIn mathematical terms, what you see in Figure 5-1 is a directed graph : a collection of nodes and links, where the links often have arrows indicating their directionality. The nodes in this diagram are represented by the letters E and D . Alongside both the nodes and the two ends of each link, numbers indicate further properties of the nodes and links. In terms of the query, you can interpret these diagram elements as follows . 5.2.1.1 NodesNodes represent tables or table aliases in the FROM clause ”in this case, the aliases E and D . You can choose to abbreviate table or alias names as convenient , as long as doing so does not create confusion. 5.2.1.2 LinksLinks represent joins between tables, where an arrow on one end of the link means that the join is guaranteed to be unique on that end of the join. In this case, Department_ID is the primary (unique) key to the table Departments , so the link includes an arrow on the end pointing to the D node. Since Department_ID is not unique in the Employees table, the other end of the link does not have an arrow. Following my convention, always draw links with one arrow with the arrow pointing downward. Consistency is useful here. When you always draw arrows pointing downward, it becomes much easier to refer consistently to master tables as always being located below detail tables. In Chapter 6 and Chapter 7, I describe rules of thumb for finding optimum execution plans from a query diagram. Since the rules of thumb treat joins to master tables differently than joins to detail tables, the rules specifically refer to downward joins and upward joins as a shorthand means of distinguishing between the two types. Although you might guess that Department_ID is the primary key of Departments , the SQL does not explicitly declare which side of each join is a primary key and which side is a foreign key. You need to check indexes or declared keys to be certain that Department_ID is guaranteed to be unique on Departments , so the arrow combines information about the nature of the database keys and information about which keys the SQL uses. 5.2.1.3 Underlined numbersUnderlined numbers next to the nodes represent the fraction of rows in each table that will satisfy the filter conditions on that table, where filter conditions are nonjoin conditions in the diagrammed SQL that refer solely to that table. Figure 5-1 indicates that 10% of the rows in Employees have Exempt_Flag='Y ' and 50% of the rows in Departments have US_Based_Flag='Y '. I call these the filter ratios . Frequently, there are no filter conditions at all on one or more of the tables. In that case, use 1.0 for the filter ratio ( R ), since 100% of the rows meet the (nonexistent) filter conditions on that table. Also, in such cases, I normally leave the filter ratio off the diagram entirely; the number's absence implies R =1.0 for that table. A filter ratio cannot be greater than 1.0. You can often guess approximate filter ratios from knowledge of what the tables and columns represent (if you have such knowledge). It is best, when you have realistic production data distributions available, to find exact filter ratios by directly querying the data. Treat each filtered table, with just the filter clauses that apply to that table, as a single-table query, and find the selectivity of the filter conditions just as I describe in Chapter 2 under Section 2.6. During the development phase of an application, you do not always know what filter ratio to expect when the application will run against production volumes. In that case, make your best estimate based on your knowledge of the application, not based on tiny, artificial data volumes on development databases. 5.2.1.4 Nonunderlined numbersNonunderlined numbers next to the two ends of the link represent the average number of rows found in the table on that end of the join per matching row from the other end of the join. I call these the join ratios . The join ratio on the nonunique end of the join is the detail join ratio , while the join on the unique end (with the arrow) is the master join ratio . Master join ratios are always less than or equal to 1.0, because the unique key ensures against finding multiple masters per detail. In the common case of a detail table with a mandatory foreign key and perfect referential integrity ( guaranteeing a matching master row), the master join ratio is exactly 1.0. Detail join ratios can be any nonnegative number. They can be less than 1.0, since some master-detail relationships allow zero, one, or many detail rows, with the one-to-zero case dominating the statistics. In the example, note that the average Employees row matches (joins to) a row in Departments 98% of the time, while the average Departments row matches (joins to) 20 Employees . Although you might guess approximate join ratios from knowledge of what the tables represent, query these values when possible from the real, full-volume data distributions. As with filter ratios, you might need to estimate join ratios during the development phase of an application. 5.2.2 What Query Diagrams Leave OutAs important as what query diagrams include is what they do not include. The following sections describe several things that query diagrams omit, and explain why that is the case. 5.2.2.1 Select listsQuery diagrams entirely exclude any reference to the list of columns and expressions that a query selects (everything between SELECT and FROM , that is). Query performance is almost entirely determined by which rows in the database you touch and how you reach them. What you do with those rows, which columns you return, and which expressions you calculate are almost irrelevant to performance. The main, but rare, exception to this rule is when you occasionally select so few columns from a table that it turns out the database can satisfy the query from data in an index, avoiding access to the base table altogether. Occasionally, this index-only access can lead to major savings, but it has little bearing on decisions you make about the rest of the execution plan. You should decide whether to try index-only access as a last step in the tuning process and only if the best execution plan without this strategy turns out to be too slow. 5.2.2.2 Ordering and aggregationThe diagram excludes any indication of ordering ( ORDER BY ), grouping ( GROUP BY ), or post-grouping filtering ( HAVING ). These operations are almost never important. The sort step these generally imply is not free, but you can usually do little to affect its cost, and its cost is usually not the problem behind a badly performing query. 5.2.2.3 Table namesQuery diagrams usually abstract table names to table aliases. Once you have the necessary table statistics, most other details are immaterial to the tuning problem. For example, it makes no difference which tables a query reads or which physical entities the tables represent. In the end, you must be able to translate the result back to actions on the original SQL and on the database (actions such as creating a new index, for example). However, when you are solving the abstract tuning problem, the more abstract the node names, the better. Analogously, when your objective is to correctly add a series of numbers, it's no help to worry about whether you are dealing with items in an inventory or humans in a hospital. The more abstractly you view a problem, the clearer it is and the more clearly you notice analogies with similar, past problems that might have dealt with different entities. 5.2.2.4 Detailed join conditionsThe details of join conditions are lost when you abstract joins as simple arrows with a couple of numbers coming from outside of the SQL. As long as you know the statistics of the join, the details of the join columns and how they are compared do not matter. 5.2.2.5 Absolute table sizes (as opposed to relative sizes)The diagram does not represent table sizes. However, you can generally infer relative table sizes from the detail join ratio, by the upper end of the link. Given a query diagram, you need to know overall table sizes to estimate overall rows returned and runtime of the query, but it turns out that you do not need this information to estimate relative runtimes of the alternatives and therefore to find the best alternative. This is a helpful result, because you often must tune a query to run well not just on a single database instance, but also on a whole wide range of instances across many customers. Different customers frequently have different absolute table sizes, but the relative sizes of those tables tend not to vary so much, and join and filter ratios tend to vary far less; in fact, they tend to vary little enough that the differences can be ignored.
5.2.2.6 Filter condition detailsThe details of filter conditions are lost when you abstract them to simple numbers. You can choose an optimum path to the data without knowing anything about the details of how, or using which columns, the database excludes rows from a query result. You need only know how effective, numerically , each filter is for the purpose of excluding rows. Once you know that optimum abstract path, you need to return to the detailed conditions, in many cases, to deduce what to change. You can change indexes to enable that optimum path, or you can change the SQL to enable the database to exploit the indexes it already has, but this final step is simple once you know the optimum abstract path. 5.2.3 When Query Diagrams Help the MostJust as some word problems are too simple to really require abstraction (e.g., "If Johnny has five apples and eats two, how many apples does he have left?"), some queries, like the one in Example 5-1, are so simple that an abstracted representation of the problem might not seem necessary. If all queries were two-way joins, you could manage fine without query diagrams. However, in real-world applications, it is common to join 6 or more tables, and joining 20 or more is not as rare as you might think, especially among the queries you will tune, since these more complex queries are more likely to need manual tuning. (My personal record is a 115-way join, and I routinely tune joins with more than 40 tables.) The more fully normalized your database and the more sophisticated your user interface, the more likely it is that you will have many-way joins. It is a myth that current databases cannot handle 20-way joins, although it is no myth that databases (some more than others) are much more likely to require manual tuning to get decent performance for such complex queries, as compared to simple queries. Apart from the obvious advantages of stripping away irrelevant detail and focusing attention on just the abstract essentials, query diagrams offer another, more subtle benefit: practice problems are much easier to generate! In this chapter, I begin each problem with realistic SQL, but I cannot use real examples from proprietary applications I have tuned . So, for good examples, I invent an application database design and imagine real business scenarios that might generate each SQL statement. Once I have thoroughly demonstrated the process of reducing a SQL statement to a query diagram, the rest of the book will have problems that start with the query diagrams. Similarly, most of a math text focuses on abstract math, not on word problems. Abstraction yields compact problems and efficient teaching, and abstraction further saves me the bother of inventing hundreds of realistic-sounding word problems that correspond to the mathematical concepts I need to teach. You might not worry much about how much bother this saves me , but it saves you time as well. To better learn SQL tuning, one of the best exercises you can do is to invent SQL tuning problems and solve them. If you start with realistic SQL, you will find this a slow and painful process, but if you just invent problems expressed through query diagrams, you will find you can crank out exercises by the hundreds. 5.2.4 Conceptual Demonstration of Query Diagrams in UseI have stated without proof that query diagrams abstract all the data needed to answer the most important questions about tuning. To avoid trying your patience and credulity too severely, I will demonstrate a way to use the query diagram in Figure 5-1 to tune its query in detail, especially to find the best join order. It turns out that the best access path, or execution plan, for most multitable queries involves indexed access to the first, driving table, followed by nested loops to the rest of the tables, where those nested loops follow indexes to their join keys, in some optimum join order.
However, for many-way joins, the number of possible join orders can easily be in the high millions or billions. Therefore, the single most important result will be a fast method to find the best join order. Before I demonstrate the complex process of optimizing join order for a many-way join using a query diagram, let's just see what the diagram in Figure 5-1 tells us about comparative costs of the two-way join in the underlying SQL query, if you were to try both possible join orders. To a surprisingly good approximation , the cost of all-indexed access, with nested loops, is proportional to the number of table rows the database accesses , so I will use rows touched as the proxy for query cost. If you begin with the detail node E , you cannot work out an absolute cost without assuming some rowcount for that table. However, the rowcount is missing from the diagram, so let it be C and follow the consequences algebraically:
Beginning with the other end of the join, let's still express the cost in terms of C , so first work out the size of D in terms of C . Given the size of D in terms of C , the cost of the query in terms of C follows:
The absolute cost is not really the question; the relative cost is, so you can choose the best plan and, whatever C is, 0.198 x C will surely be much lower than 0.5145 x C . The query diagram has all the information you need to know that the plan driving from E and joining to D will surely be much faster (about 2.6 times faster) than the plan driving from D and joining to E . If you found these alternatives to be much closer, you might worry whether the cost estimate based on simple rowcounts was not quite right, and I will deal with that issue later. The message here is that the query diagram answers the key questions that are relevant to optimizing a query; you just need an efficient way to use query diagrams for complex queries. 5.2.5 Creating Query DiagramsNow that you see what a query diagram means, here are the steps to create one from an SQL statement, including some steps that will not apply to the particular query shown earlier, but that you will use for later queries:
If you have available production data, it is the ideal source of filter and join ratios. For Example 5-1, you would perform the following queries ( Q1 through Q5 ) to determine these ratios rigorously: Q1: SELECT COUNT(*) A1 FROM Employees WHERE Exempt_Flag='Y'; A1: 1,000 Q2: SELECT COUNT(*) A2 FROM Employees; A2: 10,000 Q3: SELECT COUNT(*) A3 FROM Departments WHERE US_Based_Flag='Y'; A3: 245 Q4: SELECT COUNT(*) A4 FROM Departments; A4: 490 Q5: SELECT COUNT(*) A5 FROM Employees E, Departments D WHERE E.Department_ID=D.Department_ID; A5: 9,800 With A1 through A5 representing the results these queries return, respectively, do the following math:
For example, the results from queries Q1 through Q5 ”1,000, 10,000, 245, 490, and 9,800, respectively ”would yield precisely the filter and join ratios in Figure 5-1, and if you multiplied all of these query results by the same constant, you would still get the same ratios. 5.2.6 A More Complex ExampleNow I illustrate the diagramming process for a query that is large enough to get interesting. I will diagram the query in Example 5-2, which expresses outer joins in the older Oracle style (try diagramming this query yourself first, if you feel ambitious). Example 5-2. A more complex query, with eight joined tablesSELECT C.Phone_Number, C.Honorific, C.First_Name, C.Last_Name, C.Suffix, C.Address_ID, A.Address_ID, A.Street_Address_Line1, A.Street_Address_Line2, A.City_Name, A.State_Abbreviation, A.ZIP_Code, OD.Deferred_Shipment_Date, OD.Item_Count, ODT.Text, OT.Text, P.Product_Description, S.Shipment_Date FROM Orders O, Order_Details OD, Products P, Customers C, Shipments S, Addresses A, Code_Translations ODT, Code_Translations OT WHERE UPPER(C.Last_Name) LIKE :Last_Name'%' AND UPPER(C.First_Name) LIKE :First_Name'%' AND OD.Order_ID = O.Order_ID AND O.Customer_ID = C.Customer_ID AND OD.Product_ID = P.Product_ID(+) AND OD.Shipment_ID = S.Shipment_ID(+) AND S.Address_ID = A.Address_ID(+) AND O.Status_Code = OT.Code AND OT.Code_Type = 'ORDER_STATUS' AND OD.Status_Code = ODT.Code AND ODT.Code_Type = 'ORDER_DETAIL_STATUS' AND O.Order_Date > :Now - 366 ORDER BY C.Customer_ID, O.Order_ID DESC, S.Shipment_ID, OD.Order_Detail_ID; As before, ignore all parts of the query except the FROM and WHERE clauses. All tables have intuitively named primary keys except Code_Translations , which has a two-part primary key: (Code_Type, Code) . Note that when you find a single-table equality condition on part of a primary key, such as in this query on Code_Translations , consider that condition to be part of the join , not a filter condition. When you treat a single-table condition as part of a join, you are normally looking at a physical table that has two or more logical subtables. I call these apples-and-oranges tables : tables that hold somewhat different, but related entity types within the same physical table. For purposes of optimizing a query on these subtables, you are really interested only in the statistics for the specific subtable the query references. Therefore, qualify all queries for table statistics with the added condition that specifies the subtable of interest, including the query for overall rowcount ( SELECT COUNT(*) FROM <Table> ), which becomes, for this example, a subtable rowcount ( SELECT COUNT(*) FROM Code_Translations WHERE Code_Type='ORDER_STATUS '). If you wish to complete the skeleton of the query diagram yourself, as an exercise, follow the steps for creating a query diagram shown earlier up to Step 4, and skip ahead to Figure 5-4 to see if you got it right. 5.2.6.1 Diagram joins to the first focusFor Step 1, place the alias O , arbitrarily, in the center of the diagram. For Step 2, search for any join to O 's primary key, O.Order_ID . You should find the join from OD , which is represented in Figure 5-2 as a downward arrow from OD to O . To help remember that you have diagrammed this join, cross it out in the query. Figure 5-2. Beginnings of the diagram for Example 5-25.2.6.2 Diagram joins from the first focusMoving on to Step 3, search for other joins (not to Order_ID , but to foreign keys) to Orders , and add these as arrows pointing down from O to C and to OT , since these joins reach Customers and Code_Translations on their primary keys. At this point, the diagram matches Figure 5-3. Figure 5-3. After Step 3 for the second diagram 5.2.6.3 Change focus and repeatThis completes all joins that originate from alias O . To remember which part is complete, cross out the O in the FROM clause, and cross out the joins already diagrammed with links. Step 4 indicates you should repeat Steps 2 and 3 with a new focus, but it does not go into details about how to choose that focus. If you try every node as the focus once, you will complete the diagram correctly regardless of order, but you can save time with a couple of rules of thumb:
By following these rules of thumb you can complete the diagram faster. If at any stage you find the diagram getting crowded, you can redraw what you have to spread things out better. The spatial arrangement of the nodes is only for convenience; it carries no meaning beyond the meaning conveyed by the arrows. For example, I have drawn C to the left of OT , but you could switch these if it helps make the rest of the diagram fit the page.
You find no joins to the primary key of Order_Details (to OD.Order_Detail_ID , that is), so all links to OD point downward to P , S , and ODT , which all join to OD with their primary keys. Since S and P are optional tables in outer joins, add downward-pointing arrowheads midway down these links. Cross out the joins from OD that these three new links represent. This leaves just one join left, an outer join from S to the primary key of A . Therefore, shift focus one last time to S and add one last arrow pointing downward to A , with a midpoint arrowhead indicating this outer join. Cross out the last join and you need not shift focus again, because all joins and all aliases are on the diagram.
At this stage, if you've been following along, your join diagram should match the connectivity shown in Figure 5-4, although the spatial arrangement is immaterial. I call this the query skeleton or join skeleton ; once you complete it, you need only fill in the numbers to represent relevant data distributions that come from the database, as in Step 5 of the diagramming process. Figure 5-4. The query skeleton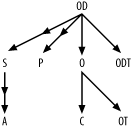 5.2.6.4 Compute filter and join ratiosThere are no filter conditions on the optional tables in the outer joins, so you do not need statistics regarding those tables and joins. Also, recall that the apparent filter conditions OT.Code_Type = ' ORDER_STATUS ' and ODT.Code_Type = ' ORDER_DETAIL_STATUS ' are part of the joins to their respective tables, not true filter conditions, since they are part of the join keys to reach those tables. That leaves only the filter conditions on customer name and order date as true filter conditions. If you wish to practice the method for finding the join and filter ratios for the query diagram, try writing the queries to work out those numbers and the formulae for calculating the ratios before looking further ahead. The selectivity of the conditions on first and last names depends on the lengths of the matching patterns. Work out an estimated selectivity, assuming that :Last_Name and :First_Name typically are bound to the first three letters of each name and that the end users search on common three-letter strings (as found in actual customer names) proportionally more often than uncommon strings. Since this is an Oracle example, use Oracle's expression SUBSTR(Char_Col, 1, 3) for an expression that returns the first three characters of each of these character columns. Recall that for the apples-and-oranges table Code_Translations , you should gather statistics for specific types only, just as if each type was in its own, separate physical table. In other words, if your query uses order status codes in some join conditions, then query Code_Translations not for the total number of rows in that table, but rather for the number of order status rows. Only table rows for the types mentioned in the query turn out to significantly influence query costs. You may end up querying the same table twice, but for different subsets of the table. Example 5-3 queries Code_Translations once to count order status codes and again to count order detail status codes. The queries in Example 5-3 yield all the data you need for the join and filter ratios. Example 5-3. Queries for query-tuning statisticsQ1: SELECT SUM(COUNT(*)*COUNT(*))/(SUM(COUNT(*))*SUM(COUNT(*))) A1 FROM Customers GROUP BY UPPER(SUBSTR(First_Name, 1, 3)), UPPER(SUBSTR(Last_Name, 1, 3)); A1: 0.0002 Q2: SELECT COUNT(*) A2 FROM Customers; A2: 5,000,000 Q3: SELECT COUNT(*) A3 FROM Orders WHERE Order_Date > SYSDATE - 366; A3: 1,200,000 Q4: SELECT COUNT(*) A4 FROM Orders; A4: 4,000,000 Q5: SELECT COUNT(*) A5 FROM Orders O, Customers C WHERE O.Customer_ID = C.Customer_ID; A5: 4,000,000 Q6: SELECT COUNT(*) A6 FROM Order_Details; A6: 12,000,000 Q7: SELECT COUNT(*) A7 FROM Orders O, Order_Details OD WHERE OD.Order_ID = O.Order_ID; A7: 12,000,000 Q8: SELECT COUNT(*) A8 FROM Code_Translations WHERE Code_Type = 'ORDER_STATUS'; A8: 4 Q9: SELECT COUNT(*) A9 FROM Orders O, Code_Translations OT WHERE O.Status_Code = OT.Code AND Code_Type = 'ORDER_STATUS'; A9: 4,000,000 Q10: SELECT COUNT(*) A10 FROM Code_Translations WHERE Code_Type = 'ORDER_DETAIL_STATUS'; A10: 3 Q11: SELECT COUNT(*) A11 FROM Order_Details OD, Code_Translations ODT WHERE OD.Status_Code = ODT.Code AND Code_Type = 'ORDER_DETAIL_STATUS'; A11: 12,000,000 Beginning with filter ratios, get the weighted-average filter ratio for the conditions on Customers ' first and last name directly from A1 . The result of that query is 0.0002. Find the filter ratio on Orders from A3 / A4 , which comes out to 0.3. Since no other alias has any filters, the filter ratios on the others are 1.0, which you imply just by leaving filter ratios off the query diagram for the other nodes. Find the detail join ratios, to place alongside the upper end of each inner join arrow, by dividing the count on the lower table (the master table of that master-detail relationship) by the count on the join of the two tables. The ratios for the upper ends of the joins from OD to O and ODT are 3 ( A7/A4 ) and 4,000,000 ( A11 / A10 ), respectively.
The ratios for the upper ends of the joins from O to C and OT are 0.8 (from A5 / A2 ) and 1,000,000 (or 1 m , from A9 / A8 ), respectively. Find the master join ratios for the lower ends of each inner-join arrow, by dividing the count for the join by the upper table count. When you have mandatory foreign keys and referential integrity (foreign keys that do not fail to point to existing primary-key values), you find master join ratios equal to exactly 1.0, as in every case in this example, from A7 / A6 , A11 / A6 , A5 / A4 , and A9 / A4 . Check for any unique filter conditions that you would annotate with an asterisk (Step 6). In the case of this example, there are no such conditions. Then, place all of these numbers onto the query diagram, as shown in Figure 5-5. Figure 5-5. The completed query diagram for the second example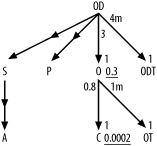 5.2.7 ShortcutsAlthough the full process of completing a detailed, complete query diagram for a many-way join looks and is time-consuming , you can employ many shortcuts that usually reduce the process to a few minutes or even less:
The key value of diagramming is its effect on your understanding of the tuning problem. With practice, you can often identify the best plan in your head, without physically drawing the query diagram at all! |
