Improving Searches
| < Day Day Up > |
| Slow queries are often the first and most visible sign of a sluggish database application. This section reviews how you can coax more performance out of your most listless queries. One important topic that isn't covered here is how to speed up your searches on FULLTEXT information. Instead, this is discussed in more detail in Chapter 11, "MyISAM Performance Enhancement." This is because a number of crucial engine control variables have a direct impact on FULLTEXT search performance; these are best examined as part of our holistic examination of the MyISAM storage engine. Leveraging Internal Engine CachesDevelopers hoping to create high-performance MySQL-based applications are not alone in their efforts; MySQL offers a number of internal engine caching features that automatically leverage system memory to make information retrieval faster. These capabilities are discussed in great detail in Chapters 10, 11, 12 ("General Server Performance and Parameters Tuning," "MyISAM Performance Enhancement," and "InnoDB Performance Enhancement," respectively). For now, let's just describe them at a high level. First, users of any MySQL engine can take advantage of the optional query cache. This cache stores queries and their related resultsets in memory. This can have dramatic benefits when your query profiles and resultsets are relatively static. You review how to exploit the query cache a little later in this chapter, with a much more detailed examination in Chapter 10. Next, the MyISAM storage engine provides a sophisticated, memory-based internal structure known as the key cache. The key cache holds index information from your most frequently accessed tables. You can also use your own, different criteria to prepopulate this cache. In fact, you can create multiple caches, each with its own purpose. Regardless of how information enters the cache(s), MySQL is able to take advantage of the far greater speed of memory when performing operations using this data. You examine how to design, configure, populate, and tune this crucial MyISAM feature in Chapter 11. Finally, the InnoDB storage engine has its own advanced memory-based caching technologies. The memory pool holds internal information, including data dictionary contents. Of greater interest to MySQL developers and administrators is the buffer pool, which holds both data and index information. Ideally, MySQL uses the buffer pool as often as possible to access as much InnoDB-based information as is available in the pool. Performing these operations in memory is far faster than working directly with the disk drives. However, MySQL administrators must understand how to set up and then optimally tune the buffer pool; this is a large part of Chapter 12. Controlling Data RetrievalMySQL offers a number of powerful extensions to the SQL standard that lets developers take a more active role in understanding and controlling how the database returns information to its clients. The following list looks at several of these innovations.
Reducing Security CostsSecurity is a vital component of any well-designed relational database strategy. However, it's important to understand that security isn't free: There is a price to be paid whenever a client issues a request for database access. The more complex your security profile (that is, the privileges and permissions you have defined for access to your MySQL database), the longer it takes for MySQL to navigate through its internal security and resource control records to validate your request. You can instruct MySQL to completely ignore your security profile by launching mysqld with the --skip-grant-tables option. However, this leaves your database completely unprotected, so it should be used with extreme caution. Off-loading Processing WorkSpreading the data and processing load among several machines via replication is a great way to improve performance. Making good replication choices is the focus of Chapter 16, "Optimal Replication." For now, imagine that your MySQL-based application performs both transactional processing and decision support tasks. Over time, the server becomes increasingly bogged down servicing both types of usages. In this case, it makes sense to replicate the information from the prime transactional server to one or more slave servers. The decision support users can then connect to the slave servers to run their reports without impacting performance on the prime, transactional server. Boosting Join PerformanceYou reviewed several ways to make your joins more efficient as part of Chapters 6 and 7 ("Understanding the MySQL Optimizer" and "Indexing Strategies," respectively). These included the SELECT STRAIGHT JOIN request, the importance of indexing join columns, and taking advantage of the join_buffer_size parameter. The following sections look at some additional join improvement suggestions. Join Column ConsistencyIn recent years, MySQL has greatly improved in its ability to accurately join data from columns that have been defined using different types. Nevertheless, it's important that you carefully design your tables so that join columns are consistent in both definition and size. Numeric Versus Nonnumeric Queries and JoinsA common and potentially costly mistake frequently made by database designers and developers is to define columns as strings that truly only contain numeric information. The price of this miscalculation is paid whenever applications filter or join on these values. For example, suppose that you are trying to design a new catering application for High-Hat Airways. As part of its ongoing and relentless cost-cutting strategy, High-Hat's catering division has invested in the newest artificial flavors and preservatives, increasing shelf life of meals from one week to six months. This means that meals need to be inventoried just like any other item. Two key tables are meal_header and meal_inventory: CREATE TABLE meal_header ( meal_id CHAR(20) PRIMARY KEY, meal_description VARCHAR(40), ... ... ) ENGINE = MYISAM; CREATE TABLE meal_detail ( airport_code INT, meal_id CHAR(20), meal_count SMALLINT, ... ... ) ENGINE = MYISAM; As usual, you were given very little time to design this application. During your brief analysis, you observe that there are fewer than 1,000 different possible meals, yet you chose to define meal_id as a CHAR(20). A commonly used query returns a listing of all meals, their descriptions, locations, and quantities: SELECT mh.meal_description, mh.meal_id, md.airport_code, md.meal_count FROM meal_header mh, meal_detail md WHERE mh.meal_id = md.meal_id; To join these two tables together on the 20-byte character meal_id, MySQL needs to evaluate the values in each table, byte-by-byte, up to 20 times per row. This can be very inefficient. Given that you know meal_id is indeed always numeric, and always less than 1,000, it's a much better idea to define these columns as SMALLINT(2), which only consumes 2 bytes. The performance and storage benefits are significant:
Remember to be consistent when choosing data types for columns, especially those that are used for joins. Substring SearchesAfter you've invested the time and effort to create the correct indexes, watch out for situations in which your database operations try to filter, join, or sort on substrings that are not anchored from the leftmost byte. These types of queries bypass your hard-earned indexes, and degrade into lethargic table scans. It's easy to understand why this happens. Suppose that you are given the Manhattan white pages and told to find all people who have a last name beginning with "Mea." You quickly flip to the pages with entries that begin with "Mea," and then retrieve all names until you hit the initial last name beginning with "Meb." Fortunately for you, the phone book is indexed by last name, so locating correct entries doesn't take too long. To represent this in SQL, your syntax looks something like this: SELECT * FROM phone_book WHERE last_name LIKE 'Mea%'; Now, assume that you're told to find all people with "ead" in their last name. How can you go about doing this? To be accurate, you have to go to the start of the book, and then laboriously read each one of the million+ entries, trying to find people who match your search criteria. In this case, the phone book's index on last names is useless. This kind of SQL looks like this: SELECT * FROM phone_book WHERE last_name LIKE '%ead%'; Although the last_name column is indexed, the optimizer can't use it. What should you do if you have many database operations that require substring filters? In these kinds of situations, if at all possible, you should simply split the string field into two or more additional, meaningful, and indexed fields. These extra indexes come with the standard cost of more disk space and slightly slower table writes, but they can have a dramatic impact on filter response. For example, suppose that you're designing a revamped, multitiered, frequent flyer application for High-Hat Airways. This application will extend High-Hat's partnerships with other airlines, hotels, and car rental companies. This requires a renumbering of existing accounts. The revamped frequent flyer account numbers will be structured as follows: AAXXBB-NNNNN "AA" is a code that represents the region where the customer lives. "XX" is the type of program that the customer has joined. "BB" is a code that represents the partner that referred the customer to this new program. "NNNNN" is a numeric sequence. Suppose that the initial table and index design looks like this: CREATE TABLE ff_new ( id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, ff_number CHAR(12), last_name VARCHAR(30), ... ... ); CREATE INDEX ff_new_ix1 ON ff_new(ff_number); If users want to construct database operations that filter on the ff_number field, everything should be fine, right? Not exactly. What happens if someone wants to find all customers that were referred by a particular partner? SELECT * FROM ff_new WHERE substring(ff_number,5,2) = 'UA'; Even though there is an index on ff_number, MySQL is unable to use it; it must run a table scan to find all relevant rows. As you've seen, table scans are very expensive, so you should give serious consideration to a revised table design. In this case, it makes sense to break the ff_number column into several indexed columns as follows: CREATE TABLE ff_revised ( id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, ff_region_code CHAR(2) NOT NULL, ff_program_type CHAR(2) NOT NULL, ff_partner_code CHAR(2) NOT NULL, ff_sequence SMALLINT NOT NULL, last_name VARCHAR(30), ... ... INDEX (ff_region_code), INDEX (ff_program_type), INDEX (ff_partner_code), INDEX (ff_region_code,ff_program_type,ff_partner_code,ff_sequence) ); This table design has several advantages over the old design:
Improving Temporary Table PerformanceMySQL automatically creates temporary tables in a variety of circumstances, including when sorting and grouping large sets of information. Aside from requesting an in-memory temporary table via SELECT SQL_SMALL_RESULT, and a number of server control variables set by your MySQL administrators, you don't have much control over the performance of these tables. However, there might be situations in which you explicitly create temporary tables on your own. These typically involve a need to create and store a subset of information from larger tables for further processing or other specialized tasks. When you include TEMPORARY in your CREATE TABLE statement, MySQL creates a table that is visible to only your session. After your session closes, the temporary table is freed. Under these conditions, you can indeed have a positive impact on system response. Make sure to
Managing View PerformanceChapter 4 discusses the performance and application development benefits of views. Unfortunately, views have the potential to cause performance risks if not managed correctly. The first example occurs when developers and users employ complex views when a simple query might suffice. For example, suppose that you are faced with the need to create a view that joins five tables using sophisticated join syntax, which unavoidably places a load on your MySQL server. However, this view provides real value and is necessary to realize all of the view-creation benefits discussed in Chapter 4. The potential performance problem arises when developers and other users of your MySQL database decide to use the view to extract columns that happen to exist in only one or two of the base tables that make up the view. In this case, MySQL is forced to perform all of the underlying joins in the view, even though the necessary data could be retrieved much more quickly simply by reading only the necessary tables. For this reason, carefully consider the potential implications of views before creating them and notifying your developers and/or users. The next potential performance issue occurs when users attempt to update a view. As you just saw, a simple-looking view can mask great complexity and resource consumption. Updates to this view can be very expensive. However, you do have some protection, as follows: If the query uses the LIMIT directive, and you are running MySQL 5.0.2 or newer, you can block updating of a view that does not contain all primary key columns from the underlying table by setting the updateable_views_with_limit system variable to 0/NO. When set to this value, MySQL blocks this kind of possible performance-impacting operation. If it is set to 1/YES, MySQL simply returns a warning. SubqueriesSubqueries add tremendous power and flexibility to your SQL toolbox. Chapter 6 explores subqueries, including their impact on performance. If you decide to use subqueries, make sure that
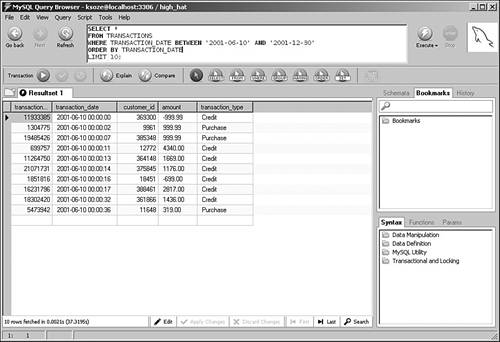
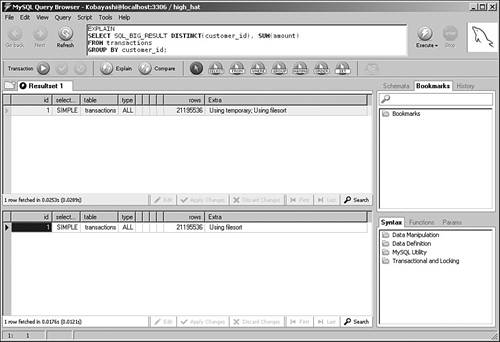
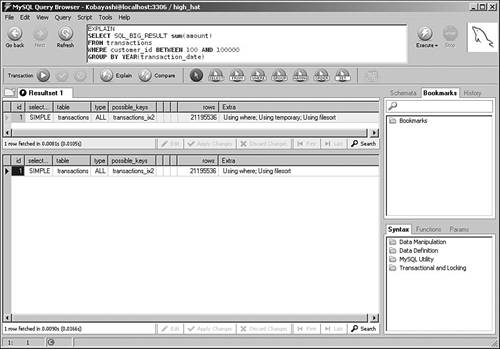
Using Math Within SQLAs a database application developer building distributed solutions, you face many questions about where to deploy your data-processing logic. One common question relates to mathematical calculations: Should you embed them inside your SQL for running at the database server, or retrieve a larger set of information and then process the data in your application on the client instead? Like many other decisions, there are strong advantages for either approach. Processing information on the client reduces the load on the server, but results in much more traffic between the database host and the client running the application code. If you're dealing with a widely distributed application with relatively poor connectivity, you run the risk of significant delays in transmitting all of this information. In addition, you might have no way of knowing the processing power of your clients; they might be unable to efficiently process this data after it arrives. On the other hand, although running heavy calculations on the server can certainly reduce traffic and take load off of the clients, there are situations in which you might inadvertently force MySQL into inefficient server operations, particularly when joining between multiple tables. Take a look at the following simple example. We created two basic tables to hold information about raw materials, and then loaded about 100,000 rows of random data. We're particularly interested in running simulations using the amount column, which is indexed in both tables: CREATE TABLE materials_1 ( id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, description CHAR(20), amount DECIMAL(5,2), INDEX (amount) ); CREATE TABLE materials_2 ( id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, description CHAR(20), amount DECIMAL(5,2), INDEX (amount) ); Figure 8.6 shows the query plans for some single-table queries that perform calculations on amount. Figure 8.6. Query plans for math-based searches.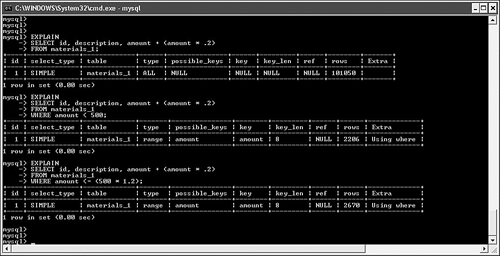 These query plans make sense: The first query forces a table scan because there isn't a filter, whereas the second and third queries are able to employ the index on amount to speed processing. Now, take a look at Figure 8.7, which includes joins to the materials_2 table. Figure 8.7. Multitable math-based query plans.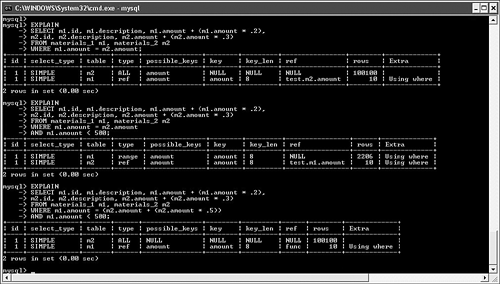 The first two query plans are expected: Because there is no filter, the first query forces a table scan, whereas the second query is able to use the correct indexes because there is now a filter. However, the third query is more interesting (and unexpected). By adding math to the join, we have forced MySQL to perform a table scan because it is now unable to use the index. What should you do if you really need to perform math inside a join clause? One answer is found in MySQL 5.0 and beyond: stored procedures. You may be able to leverage these procedures for additional server-side runtime flexibility. You review all the efficiency benefits of stored procedures in Chapter 9. GROUP BY...WITH ROLLUPAlthough server-side math might be expensive in certain situations, there are other times when you can take advantage of the ROLLUP modifier to GROUP BY. Typically, GROUP BY is used when you want to summarize information by major categories. For example, suppose that you want to write a query that returns the sums of all transactions in the month of January for the last five years. You also want the query to sum up all of the values so that you don't have to perform this calculation on the client. This is where GROUP BY...WITH ROLLUP comes in handy: SELECT YEAR(transaction_date) as 'Year', SUM(amount) as 'Total' FROM transactions WHERE YEAR(transaction_date) BETWEEN 2001 AND 2006 AND MONTH(transaction_date) = '01' GROUP BY YEAR(transaction_date) WITH ROLLUP; +------+----------+ | Year | Total | +------+----------+ | 2001 | 25572.01 | | 2002 | 7162.00 | | 2003 | 9400.00 | | 2004 | 27403.99 | | NULL | 69538.00 | +------+----------+ GROUP BY and SortingUnless you specify otherwise, MySQL sorts your resultset in the same order as your grouping. For example, look at the following query: SELECT YEAR(transaction_date) as 'Year', SUM(amount) as 'Total' FROM transactions GROUP BY YEAR(transaction_date); In this case, your results are returned sorted by the year of the transaction. However, if this sorting is not important to you, append ORDER BY NULL to your query: SELECT YEAR(transaction_date) as 'Year', SUM(amount) as 'Total' FROM transactions GROUP BY YEAR(transaction_date) ORDER BY NULL; With this new directive, MySQL avoids the extra work to sort the resultset, which usually results in a modest performance gain. The increased performance is more noticeable if there are many distinct groups of results. UNIONsAs a relatively recent addition to the MySQL product line, UNIONs are still fairly misunderstood. However, they can add tremendous value to your queries by dramatically speeding response. In addition, version 5.0 offers new query processing algorithms that further extend the power of UNIONs. This section reviews how you can make the most of this valuable database operation. UNIONs are most helpful when you want to conduct a search on two or more filtered conditions that are typically separated by OR. Prior to MySQL 5.0, even if all filter columns are indexed, MySQL still conducts repeated table scans through the table using each filter and then merges the results to provide an answer. This can be excruciatingly slow. Fortunately, MySQL introduced the UNION operator with version 4.0. This new functionality means that you can separate these types of queries with a UNION rather than an OR. By doing this, MySQL uses all relevant indexes in separate passes through the table, and then merges the results back at the end. In version 5.0, things are even better. Its new query processing algorithms can take advantage of multiple indexes on the same table, even if they are separated by OR. However, there are still performance benefits for UNIONs in version 5.0, as you'll see in a moment. For the next few examples, suppose that you have a multimillion row table containing customer information: CREATE TABLE customer_master ( customer_id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, ff_number CHAR(10), last_name VARCHAR(50) NOT NULL, first_name VARCHAR(50) NOT NULL, home_phone VARCHAR(20), mobile_phone VARCHAR(20), fax VARCHAR(20), email VARCHAR(40), home_airport_code CHAR(3), date_of_birth DATE, sex ENUM ('M','F'), date_joined_program DATE, date_last_flew DATETIME ) ENGINE = INNODB; CREATE INDEX cm_ix1 ON customer_master(home_phone); CREATE INDEX cm_ix2 ON customer_master(ff_number); CREATE INDEX cm_ix3 ON customer_master(last_name, first_name); CREATE INDEX cm_ix4 ON customer_master(sex); CREATE INDEX cm_ix5 ON customer_master(date_joined_program); CREATE INDEX cm_ix6 ON customer_master(home_airport_code); Now, assume that you need to locate all customer records for people with either the last name of "Lundegaard" or those who normally fly out of Minneapolis. Both the last_name and home_airport_code columns are indexed. However, look at the results of the EXPLAIN command for version 4.1.7: mysql> explain -> SELECT last_name, mobile_phone, email -> FROM customer_master -> WHERE last_name = 'Lundegaard' -> OR home_airport_code = 'MSP'\ G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: customer_master type: ALL possible_keys: cm_ix3, cm_ix6 key: NULL key_len: NULL ref: NULL rows: 1187067 Extra: Using where 1 row in set (0.00 sec) As predicted, this results in a table scan. On the other hand, if you separate these two conditions with a UNION, observe the new query plan: mysql> explain -> SELECT last_name, mobile_phone, email -> FROM customer_master -> WHERE last_name = 'Lundegaard' -> -> UNION -> -> SELECT last_name, mobile_phone, email -> FROM customer_master -> WHERE home_airport_code = 'MSP'\ G; *************************** 1. row *************************** id: 1 select_type: PRIMARY table: customer_master type: ref possible_keys: cm_ix3 key: cm_ix3 key_len: 50 ref: const rows: 1 Extra: Using where *************************** 2. row *************************** id: 2 select_type: UNION table: customer_master type: ref possible_keys: cm_ix6 key: cm_ix6 key_len: 4 ref: const rows: 53 Extra: Using where *************************** 3. row *************************** id: NULL select_type: UNION RESULT table: (union1,2) type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: NULL Extra: 3 rows in set (0.00 sec) This is much better: MySQL uses not one, but two indexes to get your answer more quickly. How much more quickly? The first table-scanned query was 17 times slower than the second, UNION and indexed query. What happens in version 5.0? Look at the query plan for the original SQL with the OR: mysql> explain -> SELECT last_name, mobile_phone, email -> FROM customer_master -> WHERE last_name = 'Lundegaard' -> OR home_airport_code = 'MSP'\ G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: customer_master type: index_merge possible_keys: cm_ix3, cm_ix6 key: cm_ix3, cm_ix6 key_len: 50,4 ref: NULL rows: 240 Extra: Using sort_union(cm_ix3,cm_ix6); Using where 1 row in set (0.00 sec) This is much better than 4.1.7. MySQL is now able to use the index-merge algorithm to sort and merge the results from both parts of the query. However, UNIONs still have value with version 5.0: mysql> explain -> SELECT last_name, mobile_phone, email -> FROM customer_master -> WHERE last_name = 'Lundegaard' -> -> UNION -> -> SELECT last_name, mobile_phone, email -> FROM customer_master -> WHERE home_airport_code = 'MSP'\ G; *************************** 1. row *************************** id: 1 select_type: PRIMARY table: customer_master type: ref possible_keys: cm_ix3 key: cm_ix3 key_len: 50 ref: const rows: 1 Extra: Using where *************************** 2. row *************************** id: 2 select_type: UNION table: customer_master type: ref possible_keys: cm_ix6 key: cm_ix6 key_len: 4 ref: const rows: 239 Extra: Using where *************************** 3. row *************************** id: NULL select_type: UNION RESULT table: (union1,2) type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: NULL Extra: 3 rows in set (0.00 sec) When we ran the two competing queries in version 5.0, the UNION was approximately 30% faster than the original statement. As you develop or tune your MySQL-based application, be on the lookout for those cases in which including a UNION can both simplify and speed your SQL. SortingIt's an unfortunate fact that no matter how much work you put into planning your database and application, users will find a way to introduce unforeseen, resource-hogging requests, usually at a time when you're least prepared to service them. New sorting requirements are one of the most common of these unplanned performance complications, especially when they involve nonindexed columns from enormous tables. Suppose that you have a table that holds many millions of records of transaction detail: CREATE TABLE transaction_detail ( transaction_id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, transaction_date DATETIME NOT NULL, amount DECIMAL (5,2) NOT NULL, transaction_type ENUM ('Purchase', 'Credit'), payment_ref VARCHAR(30), INDEX (transaction_date, amount) ); A few weeks pass after the application has gone live, and now management wants a new report that shows all transactions, sorted first by the payment_ref and then by the TRansaction_date columns. This query is especially slow because there are no filter criteria and these columns are not indexed together. What makes this situation even worse is that because the query returns all rows, MySQL needs to create a temporary table to hold the sorted results. It's very possible that you will run out of necessary resources, and the query will hang (or worse). Even though you can't prevent new requirements, you can do some things to avert the potential side effects that these new situations typically introduce:
HANDLERMany database application developers have also written or maintained applications that perform file-based I/O. These applications typically open a text or binary storage file, seek to a certain position, and then return results from the file to the invoking application. These types of programs are often very fast and involve minimal overhead. For MySQL-based application developers, there might be times that this type of capability is useful. In fact, MySQL AB made this functionality available in both the MyISAM and InnoDB storage engines, beginning with version 4.0.3. This section explores this new information retrieval option and pays special attention to ways you can take advantage of it to boost response, as well as some things to keep in mind if you decide to employ HANDLER. Recall the simple table that tracks customer mileage transactions from Chapter 7: CREATE TABLE customer_mileage_details ( customer_id INT NOT NULL, ff_number CHAR(10) NOT NULL, transaction_date DATE NOT NULL, mileage SMALLINT NOT NULL, INDEX (customer_id), INDEX (ff_number, transaction_date) ) ENGINE = MYISAM; This table contains many millions of rows. Suppose that you need to create a data analysis application that has the following requirements:
With all these criteria in place, using HANDLER makes sense. The table would be opened as follows: HANDLER customer_mileage_details OPEN; Next, suppose you want to seek to the section of this table that matches a particular value for ff_number. Normally, a SELECT statement would trigger the optimizer to determine the correct query plan. However, HANDLER bypasses the optimizer, so you're on your own to pick the correct retrieval method: HANDLER customer_mileage_details READ ff_number FIRST WHERE ff_number = ('aaetm-4441'); +-------------+------------+------------------+---------+ | customer_id | ff_number | transaction_date | mileage | +-------------+------------+------------------+---------+ | 23782 | aaetm-4441 | 2001-12-21 | 4204 | +-------------+------------+------------------+---------+ After you've found your place in the table, you now want to read the next 10 rows from this position: HANDLER customer_mileage_details READ NEXT LIMIT 10; +-------------+------------+------------------+---------+ | customer_id | ff_number | transaction_date | mileage | +-------------+------------+------------------+---------+ | 12934 | aaaoh-1730 | 2004-10-02 | 20645 | | 19170 | aaawk-5396 | 2001-12-19 | 3770 | | 18520 | aabas-1028 | 2000-12-17 | 14982 | | 30396 | aabzt-5102 | 2003-03-20 | 18204 | | 14363 | aacit-1012 | 1999-07-09 | 5111 | | 16343 | aaclf-5747 | 2002-10-10 | 2030 | | 7781 | aacqb-1420 | 2002-04-06 | 29931 | | 29118 | aacwp-2267 | 2003-11-05 | 21146 | | 3690 | aacys-7537 | 2004-09-14 | 14433 | | 3750 | aadaa-7803 | 1999-07-04 | 27376 | +-------------+------------+------------------+---------+ As mentioned earlier, this HANDLER call retrieves data in the physical order that the data is stored on disk (that is, in the MyISAM file). In this case, it is stored in ff_number, transaction_date order. Also, because the HANDLER is already open, the engine has minimal parsing and other overhead to process the statement. When you've finished processing the information that you retrieved from the database (usually within your application logic), you should close the HANDLER: HANDLER customer_mileage_details CLOSE; Many more permutations and possibilities are available with HANDLER than just shown. If you decide to make use of it, be aware of a few important facts:
|
| < Day Day Up > |
EAN: 2147483647
Pages: 131