WCR
| WCR, simply put, is making use of the intelligence of a content switch and steering or redirecting the traffic to the cache farm. This method requires no caching protocols such as ICP or WCCP. By using the content switch, caches can retrieve and serve content extremely quickly. There are no processing overheads required in order to understand which device has what data. In addition, routers can perform the function for which they are designed, and that is to route. Overloading them with other tasks can impact other business critical traffic, delay routing updates, and degrade convergence times. There are typically two methods for WCR:
Using Layer 4 WCR is often seen as the traditional method, as it typically redirects TCP port 80 to the cache farm. Some tuning of load balancing metrics can maximize cache hits, but other than that, no more intelligence is achieved. Layer 7 WCR, on the other hand, offers much more granularity and allows for caching on:
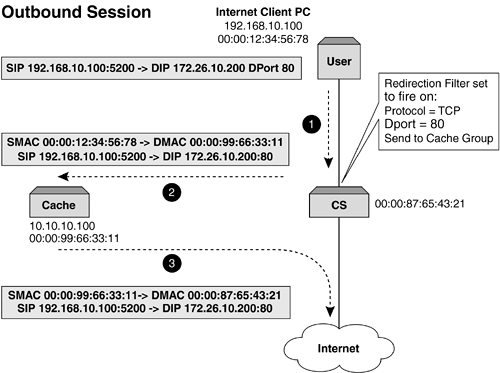
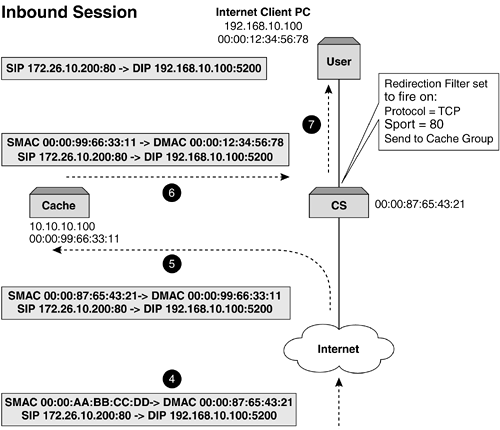
This functionality allows a much richer and intelligent spread of traffic, as caches can be configured to handle specific types of content and management of this is more easily achieved. Before we progress, let's quickly cover a topic that can determine and influence how WCR on a content switch is implemented. IP SpoofingJust mentioning this can get security administrators in a spin. IP spoofing disregards traditional network rules and allows a transparent proxy device to perform the request on its behalf , but, and it is this that causes security concerns, uses the IP address of the source device. In other words, the proxy device will receive the request and forward it on maintaining both the SIP and DIP addresses but expect the response to come back to the proxy device. This function is seen as a security breach, and some firewalls and routers will alert the security administrator that there is a possible intruder or hacker within the network. Care must be taken when deploying a cache (or any appliance) that performs IP spoofing. It is the content switch that ensures that the spoofed packet returns to the "correct" device, which in this case would be the cache (or appliance). IP spoofing is an important function when upstream sites want to understand who is accessing them. ISPs also like to use IP spoofing to ensure that they are not seen as masquerading as a mega proxy. Layer 4 Web Cache RedirectionRegardless of which cache method is used (forward, transparent, or reverse), Layer 4 WCR can be deployed. By its very nature, the cache will receive a packet either destined for it or for the origin server. By inspecting the HTTP header and understanding the location of the content, the request is then forwarded on. In Figure 8-7, we can see that using a content switch and its redirection filters or processes ensures that packets get sent to the cache. This is relatively simple to set up, as all we are redirecting on is port 80. On redirection, the destination port could be changed by the content switch if required (e.g., from 80 to 8080) in order to adhere to the cache's listening port. Understanding how we ensure that the packets get to the cache is easy. The cache then requests the data and the request is routed to the origin server. If the cache is not performing a proxy function but rather maintaining the users source IP address, also known as IP spoofing, how will we ensure that the packet returns to the cache? The problem here is that the response packet will have a destination IP address equal to that of the user, and the content switch should route it directly to the user in order to adhere to the Layer 3 rules. It is imperative that the cache gets this request back in order to store it for later use. If it did not allow this, then the function of caching would be severely jeopardized. In addition, as the cache is out of the data path , there is no way of it seeing this traffic. So, what do we do with the return packet? Well, it is the content switch that needs to be configured to ensure that the return packets are sent back into the cache. This can be easily achieved, as all that is required is that the inverse of the redirection filter set up for outbound traffic needs to be configured for inbound traffic as illustrated in Table 8-1. Figure 8-7a. Layer 4 WCR showing traffic flow and address substitution. This ensures that all HTTP traffic is returned back to the cache that requested it. There is, however, another problem here: How do we ensure that traffic is returned to the correct cache if more than one cache is deployed? The next section describes how to solve this problem. Figure 8-7b. Layer 4 WCR showing traffic flow and address substitution. Table 8-1. Redirection Filters
WCR and Load Balancing MetricsWithout doubt, understanding the traffic flows and what will happen when configuring WCR on the content switch is critical to ensuring a successful installation. In Chapters 5 and 6, we discussed load balancing and the different metrics used to provide persistence versus load. With caching, persistence is not a definite requirement but one that makes a lot of sense. If we had a request leaving our device and it was redirected to a cache farm, surely we would want the response to return via the initiating cache and not another cache within the farm. The reasons for this are:
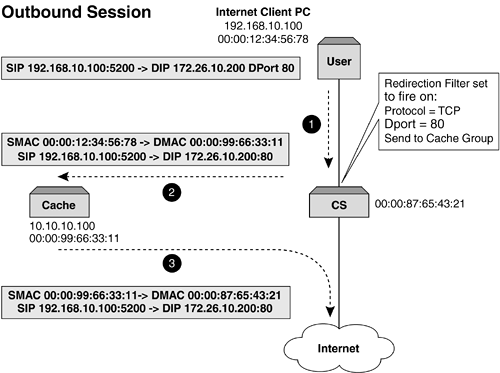
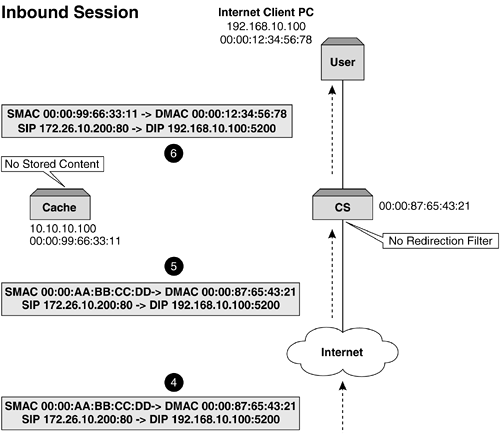
It is important to understand that caches are treated exactly the same as real servers within a load balancing configuration. They are health checked just like any other device, they can have a load balancing weight associated to them, have maximum connections configured, or any other valid real server parameter that may be required. They are added to a group and are seen as a group of devices with equal resources that can be selected by the content switch when performing redirection. Because redirection is to a group of servers, and a group must have a load balancing metric associated with it, it is imperative that we understand what happens with the different types of metrics. For starters, the classic round robin and least connections are nonstarters because this would severely minimize your cache hits. As we have discussed throughout this book, IP address hashing is an excellent method for ensuring persistence. Addresses are typically unique, and it is this that we exploit when using Layer 4 WCR. Using DIP hashing is an extremely popular method for WCR as it allows for maximum cache hits and ensures that all data for that DIP (or site) is serviced by that particular cache. Using SIP hashing can also yield persistent results, but will not maximize cache hits. As can be guessed, the SIP will be unique for all users; therefore, caches would need to store all content, as a request to the same Web site from two different source addresses could get serviced by two different caches. This is not making optimal use of the caching infrastructure. However, depending on vendor, SIP or DIP hashing is not always the answer when performing IP spoofing to the caching farm. Let's look at what would happen if redirection was carried out and the content switch maintained no session information relating to the request. We can see in Figure 8-8, what happens when we enable hashing on the DIP. The initial packet gets redirected or steered to the cache farm and then is sent on to the origin server. On return, without some rule set up on the return path it would get sent directly back to the user bypassing the cache. This is not acceptable, as the content would not be returned to the cache and would not be stored for later retrieval. This totally negates the deployment of the cache, as it breaks what we are trying to achieve. A rule needs to be configured to ensure that the requests are sent back to the cache. Now with no session information, the content switch would just run the same redirection filter as seen in Table 8-2. If the DIP was used, the request could get sent to the wrong cache because the DIP will not be the same on the return path, so the switch's algorithm would potentially calculate a different cache to answer the request. The same would apply if the SIP was used. It must be pointed out that this is a vendor-specific issue and would need to be investigated when deploying WCR and IP spoofing. Figure 8-8a. IP spoofing and WCR using IP DIP hashing. Figure 8-8b. IP spoofing and WCR using IP DIP hashing. Table 8-2. Redirection Filters
If the cache is acting as a proxy and using its address as the source for all requests, then obviously this issue is nonexistent because the DIP on returning packets will be that of the requesting cache. Dependent on requirements and content switches, it will always be possible to set up a solution that works. By using Layer 7 WCR we can ensure that the correct cache is resolved regardless of SIP or DIP address. Layer 7 WCRInspecting further into the packet to determine what content is being requested is an extremely attractive method of WCR. A number of different attributes can be inspected to provide more granular traffic management:
Before we look at each, let's quickly point out the advantages of Layer 7 WCR:
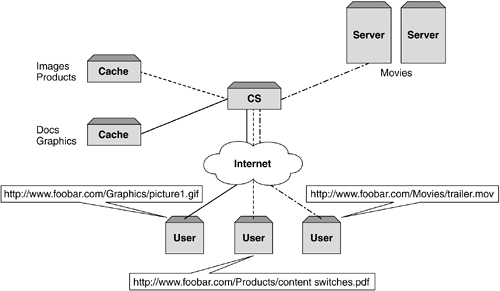
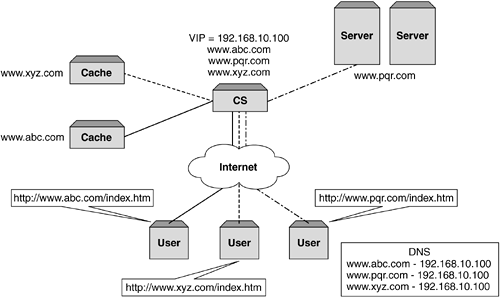
URL/URI InformationAs a refresher, let's look at the difference between a URL and a URI. http://www.foocorp.com ” the host portion or URL and typically refers to the protocol type and network location. The URI, on the other hand, typically includes the entire argument and as well as the actual file, object application, and so forth, that is requested. http://www.foocorp.com/products/content_switches/technical_specifications/data.pdf Both of these make up a URI that is used to determine Web objects and their location. Using URL/URI information to perform WCR on is a very powerful mechanism that allows the network administrator to set up different content rules to intelligently steer traffic to different caches, and in some instances, to totally bypass the cache farm when noncacheable content is being requested. In addition, the content switch can now also look at the HTTP header information, and in some cases can ignore the header directive (discussed earlier in this chapter) and send it on to the cache farm. By using the intelligence within the content switch, the caches can be optimized to cache on a per-page basis rather than a per-site basis. This also allows for certain types of content to be stored on certain types of caches. For example, a low-end cache could be used for small text type objects, while a large high-end cache could be used for caching large files and in some cases streaming media. This is shown in Figure 8-9. Figure 8-9. Layer 7 URL WCR. Host HeaderCaching on Host header allows a similar functionality to caching on DIP. Typically, the Host header is associated to a single DIP. However, in the case of virtual hosting, multiple Web sites (or domain names ) are associated with the same IP address. As can be seen in Figure 8-10, the use of Host headers can distribute the content to multiple caches that would otherwise have all been serviced by a single cache if DIP hashing was used. This particular mechanism is popular with service providers who often provide smaller organizations with this function. By using reverse proxy caching on the Host header, the cache farms would be optimized for cache hits even though all requests were destined for the same DIP. Figure 8-10. Virtual hosting and WCR. URL ParsingThis approach is very similar to IP hashing except instead of using an IP address the content switch takes the URL and parses it (parsing is discussed in Chapter 6). Based on the value, it then sends all requests for that URL to the selected cache. This means that all requests for a specific object such as .gif are sent to a specific cache regardless of host header. Due to the granularity of this the spread and retrieving of data is much more efficient than SIP or DIP hashing. Browser BasedUsing the User-Agent (or browser type) HTTP header to determine which cache, or group of caches, to select provides network administrators with the opportunity to allow multiple different topologies to use the same infrastructure. The thought process behind this approach is that it allows for different formatting for different access devices. In a wireless world where a PDA or mobile phone is accessing Web content, formatting this to fit the device output format is important. Mobile phones and PDAs do not have the computing power to operate in 16-bit color or have large 15" or 17" screens, so ensuring that content requested is specific to them is key. In a world where we will always have access to content, service providers and content owners will not know what end device a user is using based on IP address. However using the User-Agent allows content for those specific devices to be cached and returned, thus optimizing both the user experience and the infrastructure. Layer 7 Streaming MediaWith streaming media being seen as a high bandwidth application, caching of this makes a lot of sense to enterprises wanting to minimize operational and bandwidth costs. However WCR is typically configured to use TCP port 80, and caches are also configured for this port. Streaming clients , while TCP port 80 is configurable, prefer to use their native TCP and UDP ports and protocols that in most cases are unique to each application. Having the ability to determine that the content is a streaming application and redirect it to a Web cache offers network administrators a compelling reason for bandwidth savings and user performance. Let's take a quick look at what makes up a streaming session. Streaming Media ProtocolsWhile most streaming media applications allow the content to be sent over HTTP and played at the end device, this method of delivery does not allow for controlling the stream like a video (fast forward, pause, etc.) as it does when using the native protocols. Streaming media expects the client to set up bidirectional signaling and control channels in order to receive data. These channels typically run over TCP and UDP and use the standards-based protocols RTSP and RTP. To understand the complexities of using streaming media, we will look at just a single delivery method ”RTP over UDP. It should be pointed out that there are different methods in which to carry out these communications, but for simplicity's sake, we will look at only one. When a session is set up, the RTSP client will set up a bidirectional TCP channel between the RTSP server and itself for control and negotiation of the stream. In addition, a unidirectional RTP UDP channel is set up from the RTSP server to the client and this is what the data will flow down, while any synchronization or packet loss information is provided over an additional bidirectional UDP channel. Figure 8-11 demonstrates this. Figure 8-11. Signaling and control channels set up when using RTP over UDP for delivery of streaming media. As Real Networks and Apple QuickTime both use RTSP as their protocol of choice, the content switch needs to be able to redirect this into the cache in exactly the same fashion as its HTTP cousin. Obviously, this is a little more complex than HTTP, as there are two other TCP/UDP sessions associated with this single user stream. It is imperative that the content switch can correlate these streams and understand that they belong to the same user. This functionality is a key requirement when performing Layer 7 streaming protocol redirection. As the cache is handling these streams on behalf of the origin server, it is important that the associated user streams (control, signaling, and data) are sent to the same cache. In a single cache environment this would be simple as there is only one destination, but as cache farms increase, then the need to use Layer 7 properties is key to ensure that all sessions associated to one stream are delivered to a single device in order to function correctly. Redirection of Microsoft's MMS protocol is also possible and would benefit the user and provider in exactly the same way. Noncacheable ContentSome content cannot be cached due to its dynamic nature, and there is some that maybe the content owner or network administrator does not want to cache. As an example, financial stock pricing and online games may not be able to be cached and are usually configured to bypass any caches in the request response path. In addition, some sites require IP address authentication, and using a proxy cache will disallow this to happen. Therefore, caching vendors allow for dynamic bypass and if not supported, content switches can be configured to allow these types of request through without being sent to the cache. Whatever the reason, there is no sense in sending it to the cache and incurring processing overhead on files that cannot be cached. Most content switch manufacturers also include a list of known noncacheable content and these typically include the following:
These are not fixed in stone, and any decent content switch will allow you to delete or add to the list when deploying WCR. Vendor IssuesWhile it is not our intention to determine what each caching and content vendor can and cannot do when interoperating, we feel that we should point out a few areas where issues have existed and could potentially do so in the future. By being aware of these and understanding the symptoms, troubleshooting can become much simpler. MAC Address SubstitutionAn area where content switches and cache vendors can bump heads is on the use of MAC addresses in redirection. In some content switches, when redirection takes place only the destination MAC address is changed. This is acceptable and allows the device to see the SIP and DIP as well as the source MAC address, which hasn't been changed. Now, if this redirection was to another subnet, and the source MAC address was not changed to that of the content switch, there are some caches (and firewalls) that will make a note of the source MAC address. On response instead of routing it via the correct gateway, it merely substitutes this MAC address in the destination MAC address field and forwards the packet. No device will receive the packet, as the MAC address is not on that particular network. Therefore, the response will be dropped and the user will finally time out. To overcome this "feature," some content vendors allow for the source MAC address to be substituted with that of the content switch. This ensures that all return packets are sent to it where the session table can then be scanned and the correct process is run against the returning packet. Firewalls and SYN AttacksOne of the main functions of a cache is to retrieve data quickly and efficiently . This is what manufacturers strive to achieve and one goal we all feel is beneficial. Caches also try to "anticipate" your next request by downloading links from within the requested page to ensure that should you require the content, it is already available. When accessing content quickly and intelligently, caches will set up many TCP sessions simultaneously . This is of particular relevance when HTTP/1.0 is used. By being proactive, caches can often cause a firewall to deny it access, as it appears that a SYN attack is being processed . This typically will only happen in a proxy mode, as the SIP will be that of the cache and in some instances thousands of sessions can be set up in a single second causing the firewall threshold to be breached. It is important to understand this potential pitfall and ensure that the security and network administrators are aware of this in order to create the necessary rules and polices to allow this to occur. Without doubt, using WCR for Layer 7 functionality allows the ability to perform total control over your site. It must be noted, however, that using Layer 7 functionality does incur higher latency than blindly sending all port 80 (or 554) traffic to a cache farm. This is obvious, as the content switch will need to first perform delayed binding or TCP splicing as discussed in Chapter 6. This allows the cache to then scan the HTTP portion and determine what content is being requested. In addition to this, WCR relies on caching vendors to provide an appliance that is up to the task that the content switch is performing. While some content switch manufacturers also provide caching solutions, by its very nature a content switch is cache agnostic . Any caching product, be it software or appliance based, will work with any content switch today. |

EAN: 2147483647
Pages: 85