The Nature of XML
One often hears that XML is exactly what we've all been waiting for—a better HTML. This characterization of XML is not true! XML and HTML both are children of the same parent, which is SGML. The same, by the way, could be said about most word processing applications.
XML Is an Established Web Standard
First and foremost, XML is an established Web standard, managed by the World Wide Web Consortium (W3C). In contrast with a language such as Java, XML doesn't belong to a single vendor; it's in the public domain, owned by an independent organization. Therefore, you can count on extremely broad-based support for XML. For example, even if we're not there quite yet, almost any browser will understand and support XML documents. Given the fast-growing importance of the Web, and given the current difficulties in creating "intelligent" Web applications, we probably don't have to tell you how much such support for XML would mean.
Our vision, undoubtedly shared with millions, is a world in which you can send your data as XML to anybody and have it presented in the realm of HTML, just as you want it to be presented. In this context, "anybody" really means anybody, no matter which computing platform they're using. This isn't the present situation, and it's not a promise, but it's a nice vision, isn't it?
XML Is a Tagged Language
Derived from SGML, both XML and HTML are tagged languages, but they don't share the same purpose and they can't replace one another. HTML is a language for the presentation of data and information; XML is a metalanguage for describing data. HTML is rather loosely defined and is forgiving rather than rigid; XML is as rigid as can be and is never forgiving. HTML as a language consists of a number of predefined tags; XML as a metalanguage relies on your defining the tags for your purpose.
- Here are a few examples of HTML tags, shown in pairs with one start tag and one end tag: <BODY> </BODY>, <P> </P>, <TABLE> </TABLE>, <DIV> </DIV>. Each of these tags is defined as a part of the HTML language.
- The following are examples of XML tags, also shown in pairs with one start tag and one end tag: <Customers> </Customers>, <Customer> </Customer>, <Customer Name> </Customer Name>. None of these tags are predefined as part of XML. With XML, you define your own tags, and you give them names that help people understand what they represent, just as in the preceding examples.
Anatomy of an XML Document
Let us give you an example of a complete XML document, ready to open in a browser that supports XML. Microsoft Internet Explorer 5.0 and later is such a browser. Here's the XML document, as presented in a text processor such as Microsoft Notepad:
<?xml version="1.0" encoding="windows-1252" ?> <Horserace> <Track>Täby Galopp</Track> <Date>1999-10-15</Date> <Raceno>3</Raceno> <Distance>1600</Distance> </Horserace> |
The preceding document, which as we said is a complete XML document, consists of three separate parts.
The first part is the prolog. The prolog identifies this document as an XML version 1.0 document, which might be useful when the next version of XML arrives. You don't have to include the version number in your prolog, but XML experts warmly recommend that you do it. The second part defines this document as being encoded in accordance with the windows-1252 character set. Remove the encoding clause from this document, and no well-behaved XML processor accepts the document. Reading stops at the typical Swedish ä character in the track name: Täby Galopp. If the language in your document is English, you might do well without an encoding clause in the prolog; if it's anything else but English, you'd better check to see what you might need. XML books and documentation should give you all the information you need to select the encoding clause that works in your case.
The second part of the document is the root element. Every well-formed XML document (see an explanation of the term well-formed in the "Well-Formed Documents" section of this chapter) needs exactly one root element, which contains all the other elements. In the preceding document, the root element is the Horserace element. You can see that the document's first tag is the <Horserace> tag and that the corresponding end tag is the last tag of the document.
The third part of the document consists of all the elements that are contained in the root element. You can see that each contained element has a start tag and an end tag that identifies the information between them. You can also see that the tags, being named in an informative way, make the document easy to understand. It doesn't take a genius to see that according to this document, the third race at Täby Galopp on October 15, 1999, was run over the distance of 1600 meters.
XML Is Rigid, HTML Is Not
In principle, you should always use the end tag that corresponds to a start tag also in HTML, but in many cases HTML forgives you if you're a bit sloppy with that. Most browsers would accept HTML code such as the following:
<P>This is my first paragraph. <P>Here comes the second paragraph—even though no end tag has yet finished off the preceding paragraph. |
HTML sometimes also accepts bad nesting of tags; that is, a browser will display the content even though the tags aren't arranged properly, with one tag group completely contained in another. This is lucky because many tools that create HTML code from a WYSIWYG user interface tend to produce bad nesting of tags. Microsoft Internet Explorer is known to be more forgiving than Netscape Navigator, but they are both much more forgiving than the most permissive XML processor you could imagine. For that processor won't forgive any kind of bad nesting or any unbalanced tags. The tags of the following XML document aren't well balanced, and no decent XML processor is likely to accept the document:
<Customers> <Customer>Peterson's Grocery Store <Customer>Johanson's Delicatessen </Customers> |
If you want the preceding document accepted, you must reformat it as shown below. The text printed in boldface type helps you identify what's new: the end tags of the two Customer elements.
<Customers> <Customer>Peterson's Grocery Store</Customer> <Customer>Johanson's Delicatessen</Customer> </Customers> |
Well-Formed Documents
Well-formed and valid are two terms used to describe usable XML documents. A well-formed XML document follows a number of basic and necessary rules (which we'll describe shortly). An attempted XML document that's not well formed simply isn't an XML document; it's something else. And what is a valid document? Well, the first prerequisite for a valid document is that it be well formed. Second, it must conform to a schema, the document must identify that schema, and the schema must be written in a schema language. Such a schema, roughly described in the sections "Using Document Type Definition for Schema Definitions" and "Using XML-Data for Schema Definitions" later in this chapter, defines which elements are acceptable in the XML document and how they must relate to one another.
The XML specification, found at www.w3.org/Tr/REC-xml, is the basic source of the rules that define an XML document as well formed. Happily, though, it's mainly special applications called XML processors and developers of such applications that need to go into all the details of these rules. You need to know the basics only; if you break any rule, sooner or later an XML processor will tell you about it. The basics are simple enough, and here they are:
- A well-formed XML document must contain one or more elements. You would probably break this rule only if you use badly designed or badly written software to create your XML document. Just make sure that you always include the root element, even if empty. If you do, you're always OK.
- Your XML document must contain exactly one root element. The absence of a root element is one too few—see the preceding bullet—and two root elements are one too many. What's more, all other elements must be correctly nested in relation to one another and in relation to the root element, as in the example shortly to follow.
The following document is well formed. It contains exactly one root element, which is the Customers element. The root element contains two other elements, Customer elements, and they are correctly nested in relation to one another as well as in relation to the root element.
<Customers> <Customer>Peterson's Grocery Store</Customer> <Customer>Johanson's Delicatessen</Customer> </Customers> |
You can easily open this document in Internet Explorer 5.0, as you see in Figure 20-1. The document must be saved in a file, but what you see in the preceding code is all you need. Looking at Figure 20-1, you see a minus sign in front of the Customers element. When the user clicks on it, the element collapses, showing only the Customers element and with the minus sign replaced by a plus sign for expanding the element again.
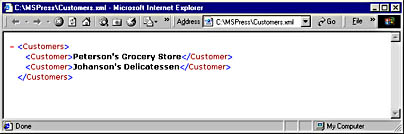
Figure 20-1. A very small and simple but well-formed XML document, shown in Internet Explorer 5.0.
You might recall that one of the prerequisites for an XML document to be considered well-formed was that it should have exactly one root element. Removing the Customers element from the preceding XML document leaves the two Customer elements alone, as follows:
<Customer>Peterson's Grocery Store</Customer> <Customer>Johanson's Delicatessen</Customer> |
The XML document is no longer well formed. Depending on how you look at it, the document now has either two root elements or none. Internet Explorer considers it to be two, which is shown by the message in Figure 20-2, as Internet Explorer refuses to display the document.
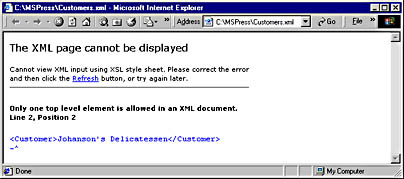
Figure 20-2. Internet Explorer refuses to accept an XML document that isn't well formed.
XML Is Case Sensitive
One thing that you absolutely must know about XML is that it's case sensitive. For example, the <Horserace> tag isn't the same as the <HorseRace> tag and very different from <HORSERACE>. An element such as <Horsename>Songline</HorseName> isn't balanced because the uppercase N in the end tag isn't present in the main tag. Such a difference prevents the entire document from being well formed; no XML processor accepts it.
So you should be careful when you set your standard for tag names. You should avoid mixtures of uppercase and lowercase characters. Use only lowercase characters for tag names, as in <horsename>, or only uppercase characters, as in <HORSERACE>. You can also use uppercase for the first character and lowercase for the rest, as in <Horserace>, but you should avoid mixing them as in <HorseRace>. The more you mix uppercase characters with lowercase characters, the more difficult it is to balance the tags of your elements.
XML Is Verbose
You can also see that XML is rather verbose. The Horserace document needs 175 characters to represent information that could be structured as follows, Täby Galopp 1999-10-15 3 1600, using only 29 characters. (Don't bother to count the characters of the XML document; you'll probably arrive at another number. We copied the string into a Visual Basic variable and used the Len function to get the contestable number 175.) So the XML document we're talking about contains 29 characters of data and 146 characters of descriptions, which makes the ratio roughly 1 to 5. We have five pieces of description for each piece of data.
This is no problem if you want to transport small amounts of data over a local network, or even over the Internet. But if you want to transport really large data sets, you should be careful. The absolute size of a data set isn't really the issue; a Visual Basic String variable can hold about 2 billion characters. It's the general idea of transporting thousands of records with millions of child records over the Internet that seems a bit exaggerated. But, what's new about that? Internet or no Internet, you should always, for dozens of reasons, try to keep the data sets you move from one point to another as small as you can.
EAN: 2147483647
Pages: 133