Event Categories
| I l @ ve RuBoard |
| To effectively manage events related to a UNIX server, you first need to understand the types of events that may occur. This chapter gives examples of a wide variety of events that may occur, and provides one possible grouping of those event categories. By understanding the set of possible events that may occur, you will understand what to look for when troubleshooting a problem. One way to categorize events is by the affected software or hardware component. These categories include: system, disk, network, application, and database events. In fact, we used this approach when determining the structure of this book. Each category of events is discussed exclusively in its respective chapter later in the book. For example, system events are described in Chapter 4. Chapters 4 through 8 group events into the following additional categories:
The following sections describe each category, in turn , in more detail. Environmental changes, such as power outages, are also important, but are only briefly touched upon in this book and thus are described in overview at the end of this chapter. Configuration EventsYou should know about the hardware and software configuration changes taking place on your servers. A software package installed just days before a failure may be a prime suspect. Configuration changes can be complex, and administrative tools often do not provide adequate assistance. Operator error is a common source of unplanned downtime, so it is important to keep a record of the configuration changes, as well as the time each change is made. This log can be examined later, in the event of a problem, to provide an audit trail for backing out of the changes. This can be especially important when multiple operators make changes on the same systems. Configuration changes encompass a broad spectrum, and they may involve the application or database, operating system, or system hardware or peripherals. Application ChangesApplication changes include changing software parameters, such as the maximum number of users allowed to use a product. Restructuring a database is another example. Keeping a history of the changes made to application parameters can be difficult, and probably is done most commonly through revision comments in the configuration files themselves . Patches or bug fixes to applications are easier to track because the software includes a version number, which should be updated by the software vendor whenever new versions are released. Numerous tools are now available to track the software versions installed on your system. You should run one of these tools periodically and store the results, to maintain an appropriate change history. Installing a new application on the server is a key event that should be recorded. You should use this application in a test environment before moving it to production. However, the application still might not behave well. You may want to use this time as a data point when looking at performance data, to see the effect of the new application. Operating System ChangesOperating system changes are usually easier to track because they often require a system reboot before they take effect. Enterprise management products, such as HP OpenView, automatically record system reboots as events in an event log. Operating system configuration changes include changes to kernel parameters, patches, and operating system upgrades. All of these changes should be recorded. Hardware ChangesHardware configuration changes include the addition of a new processor or a new disk device. You may also want to remove or replace a component that is not behaving properly. Other hardware configuration changes include changing the firmware versions or patching the driver software. Because these configuration changes often involve a system reboot, you should plan for downtime and schedule changes during a period when the systems are not being used. Planned downtime includes downtime required for scheduled maintenance, such as a software upgrade, and for configuration changes, such as adding disks, restructuring a database, or moving clients to different systems for load-balancing purposes. The best way to update system hardware or software is to do it online. High availability cluster products, such as Hewlett-Packard's MC/ServiceGuard, support rolling hardware and OS upgrades and enable you to move applications to another system until the upgrade is complete. Although cluster products can help you automate the upgrade process, it is still beneficial to have additional online replacement capabilities, to avoid the service interruptions associated with a rolling upgrade. System vendors are now making it easier to modify hardware components without requiring a system reboot. Both Sun and Hewlett-Packard have released these capabilities for their UNIX servers, and both will be adding more capabilities in this area. Before the introduction of online replacement, you could track hardware configuration changes by monitoring system reboots and then just track the current configuration. Now you need to check for configuration changes more frequently. The configuration change history should be stored at a central management station and should be backed up regularly. Storing it at a central site enables you to access the information even when the server has failed or is unavailable, which can be important when trying to recover from a system failure. FaultsA fault broadly refers to any unexpected behavior occurring in the computing environment. A fault may report the failure of a hardware or software component, such as a database failure, or it may be a warning of a condition that could lead to a failure, such as a series of disk errors. Faults are the most common events sent to an event management product, partly by process of elimination . Configuration changes, security intrusions, and environmental alerts are difficult to capture as events. Performance monitoring is often done in reaction to a user complaint, because it is difficult to configure the correct performance threshold conditions that should lead to events. Faults can occur on the server itself, on a peripheral attached to the server, or on some component external to the system. Failure of a System Hardware or Software ComponentSystem hardware components include the CPU, memory, and I/O cards. As business servers have become more critical, hardware vendors have improved their designs to make these components more reliable. High availability solutions provide additional protection and can prevent some problems from causing a system failure. Despite these improvements, you still need to be prepared for hardware faults. Although the reliability of each component is improving, many more components exist to manage. A company could have 100 or more servers, each with multiple processors, many disk arrays, tape libraries, and so forth. High availability systems typically include redundant components, such as mirrored disks, extra power supplies , or extra cooling fans. Failures need to be reported in a high availability environment so that a component can be fixed before a double failure occurs. Hardware failure indications should report specific information about the failed component, such as the serial number or hardware path . This can help network support personnel locate the failed component in the server. A lower severity may be used when redundant components fail, to indicate that the problem is important but not necessarily urgent to fix. Hardware monitoring is discussed in Chapters 4 and 5. Hardware failures used to cause the system to fail, but servers are more resilient today. Servers can now continue to run, often in a crippled state, after a hardware failure. For example, a server can detect bad memory pages and deallocate them, but this leaves less memory available for the applications. The fact that a component failure may not be obvious again points out the importance of continual monitoring of the system. Repairs can then be made during a planned downtime period. You also need to monitor the status of the server software. The software can be divided into the following categories:
If the operating system fails, you will see a failure (panic) message on the server console. The server status will be shown as "DOWN" to an enterprise management product, such as HP OpenView. You need to reboot the system and look at system log files or core files to diagnose the problem. The failure of a key software application may also be a critical event to a system operator. Typically, only one key application is configured per UNIX server, so the failure of the application is essentially equivalent to a failure of the server. If you know the processes making up the application, you can periodically check the status of the processes by using UNIX commands. Some monitoring tools can automatically notify you of the failure of an important process. Some vendors provide high availability software to help protect your server. This software also needs to be monitored to ensure that it is working properly. Other important applications include database applications and enterprise resource planning applications. Later chapters describe some of the sophisticated monitoring products that are available for these applications. Management applications, such as a backup software application, also need to be monitored . Errors encountered during a backup should be reported, because such errors indicate that critical data is not being adequately protected. The easiest application failure to detect is the failure of an application process. An application can also get into a process loop or deadlock situation. Although the effect is the same to the end-user, the application is unusable; this is a much more difficult situation to detect. You are unlikely to see these situations reported as external events, although you may receive some external indications, such as timeout errors, when trying to use a service. In general, to detect these types of problems, you need to measure the performance and resource usage, and compare it to baselines. Failure of a PeripheralIn addition to the internal computer components, other important components are attached to the system. These peripheral devices include tape drives, disk devices, printers, and CD-ROM drives . A variety of errors can affect tape drives. Tape devices should be monitored proactively, because backups normally have a small window of time to complete. Detecting failures and recovering before the backup window starts can help to ensure that the backup will succeed. You should also watch for mount requests during the backup process, to keep the backup application from being blocked for too long. Disk errors and failures are an increasing problem, because the amount of stored information continues to grow. Many high availability environments now use RAID devices, which provide data redundancy by spreading data across an array of disks. Data can thus be reconstructed from surviving disks in the event of a disk failure. The arrays can even be repaired online. In addition to monitoring for disk failures, you may want to monitor the logical volume status, physical volume status, I/O errors, and the loss of a mirrored copy of data. Each of these types of failure conditions can be detected with monitoring software. Various printer events can be interesting to monitor. For example, the printer can jam, fail, or be set offline. Also, the print spooler can fail and the queue can be full. Printers require vigilant monitoring because they can often get into a state in which they are not performing properly. It is important to detect problems and fix them quickly to avoid receiving user complaints. CD-ROM drives are perhaps the least interesting of the peripheral devices to monitor. You may be interested in knowing when a drive is mounted or unmounted, but receiving only drive failure notifications is usually sufficient. Failure or Loss of an External ServiceHardware or software failures are not the only critical events that can occur on your system. Monitoring your corporate networks is critical as well. With the movement away from mainframes to distributed client/server environments, the dependency on local area networks (LANs) and wide area networks (WANs) is increasing. If the proper precautions are not taken in designing the company data center, the loss of a single network could cause denial of service to all clients trying to access critical server machines. You also need to understand the purpose of each of your networks so that you know the consequences of a failure. For example, in a high availability environment, you have networks that are used for sending data between systems, networks dedicated for high availability status checking, and backup networks. You can check a variety of networking faults and statistics to further analyze the status of your networks. You should watch for connectivity problems and "Node Unreachable" errors. You can also check Ethernet collision rates and use performance tools to check network bandwidth utilization. A UNIX server is dependent on external services, such as network services. For example, a server may be active, but the Domain Name System (DNS) server for its domain may be down, preventing clients from connecting successfully. An e-mail server is another example of a machine in this category. Similarly, hardware external to the managed system may also be important. The failure of a network router can prevent any data from getting to the managed system. Here is a sampling of some of the important external services that you need to monitor in your environment:
You can set up monitoring of these services if you know the processes that make up the application. Process failures can be detected, as mentioned earlier. More proactive approaches involve actually trying to use the service to see whether it is working properly. Many other conditions are equally important, but are much more difficult to detect, such as an expired software license, which could cause you unexpectedly to be denied access to a key application. Redundancy of these network services is a key to maintaining the availability of your server. However, this alone is not sufficient. Configuration problems and issues such as software licenses can still prevent the use of an important service. Resource and Performance EventsIn addition to looking for failure events, monitoring resource usage and performance are important. If users are unable to access critical system resources, you might as well consider the system down. The system operator needs to be notified when resource utilization reaches certain thresholds, so that measures can be taken to avert a crisis. The network, CPU, process table, filesystem, and memory are examples of critical system resources that should be monitored. High utilization alone is not sufficient to indicate a problem. It could just indicate that you are getting optimal use of your server. You also need to determine whether system bottlenecks exist and, if so, which applications are being delayed. This book distinguishes between resource usage and performance. Particular types of system resources have limitations. For example, you can run out of filesystem space, swap space, processes in the process table, files in the file table, system semaphores, or shared memory. You monitor resource usage so that you know when the system usage is approaching these configured limits. Performance describes the balance between CPU, memory, and I/O usage, and the relative usage of different applications. You want to avoid CPU, memory, and I/O bottlenecks and also ensure that high-priority applications are not blocked behind low-priority workloads. Application response time and throughput are also important to track, because those are the performance measures most visible to the users of an application. To monitor resource usage or performance, you generally watch for threshold conditions rather than failure events. For example, to watch for CPU bottlenecks, you may enable an event to be sent whenever the CPU utilization exceeds 85 percent and the run queue has more than three processes. You may need to study a system for some time to know the appropriate threshold to monitor. As previously shown, not all the important components are on the server. Printer queues can fill up, tapes can be full, and networks can become overloaded. An overloaded network can prevent access to the server. Each of these events can be monitored by setting up the appropriate thresholds. Tools are available that can provide this information in real time, or give you historical information for identifying trends. Security IntrusionsYou also need to monitor suspicious activity. Threats to a data center may come internally or externally and may be the result of intentional or unintentional misuse. As an administrator, you want to ensure that system resources are available for their intended purposes. The following events can be useful for an administrator to audit on a business system to prevent misuse of the server:
By monitoring failed login attempts, especially attempts to log in as superuser, you can potentially identify when someone is trying to guess a password to gain unauthorized access to the system. An intruder may modify existing configuration files to give himself or herself special privileges, so it is important to have a detailed change history for these files. After successfully logging in to the system, an intruder can reconfigure or damage system components, so you need to keep a history of system changes to be able to recover successfully later. You can never be completely sure that your system is adequately protected, so you must monitor your system constantly and keep system backup tapes stored safely offline. Environmental ChangesEnvironmental changes can also affect the availability of your servers. The following are a few examples of environmental events or changes:
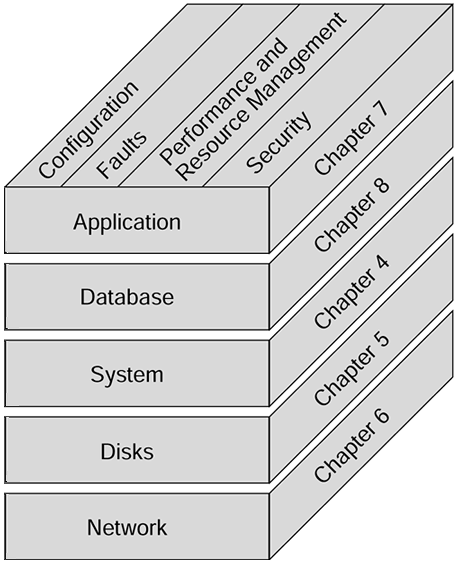
Power outages are a major source of failure among companies who do not have emergency backup power. Data from a 1995 study by the National Power Lab indicates that at least once a day, every computer room in the U.S. experiences some problem with the building's power source, typically spikes, surges, or outages. One solution to power problems is to use uninterruptible power supplies (UPSs). A UPS allows for graceful shutdown of the system after a loss of power. Batteries can keep systems up for a short amount of time, until diesel generators are activated. Systems can also recover transparently from failures of power supplies and fans if redundant components are used. Many large corporations are starting to include a disaster recovery plan as part of their computer maintenance strategy. Most at least have a policy on how to recover from backup tapes after a disaster. Companies for whom downtime equates to huge sums of lost revenue are now looking at standby data centers that are ready to take over in the event of a catastrophic failure. Hewlett-Packard's MetroCluster product is one disaster recovery product available to those customers. As shown in Figure 2-1, this book covers monitoring for events in the system, particularly those concerning the disks, network, databases, and applications. A fault or critical event in any of these areas could render mission-critical applications unusable. Figure 2-1. Components of the application stack. |
| I l @ ve RuBoard |
EAN: 2147483647
Pages: 90