Cryptography: Theory and Practice:Shannon s Theory
 | Cryptography: Theory and Practice by Douglas Stinson CRC Press, CRC Press LLC ISBN: 0849385210 Pub Date: 03/17/95 |
| Previous | Table of Contents | Next |
Chapter 2
Shannon’s Theory
In 1949, Claude Shannon published a paper entitled “Communication Theory of Secrecy Systems” in the Bell Systems Technical Journal. This paper had a great influence on the scientific study of cryptography. In this chapter, we discuss several of Shannon’s ideas.
2.1 Perfect Secrecy
There are two basic approaches to discussing the security of a cryptosystem.
- computational security
- This measure concerns the computational effort required to break a cryptosystem. We might define a cryptosystem to be computationally secure if the best algorithm for breaking it requires at least N operations, where N is some specified, very large number. The problem is that no known practical cryptosystem can be proved to be secure under this definition. In practice, people will call a cryptosystem “computationally secure” if the best known method of breaking the system requires an unreasonably large amount of computer time (but this is of course very different from a proof of security). Another approach is to provide evidence of computational security by reducing the security of the cryptosystem to some well-studied problem that is thought to be difficult. For example, it may be able to prove a statement of the type “a given cryptosystem is secure if a given integer n cannot be factored.” Cryptosystems of this type are sometimes termed “provably secure,” but it must be understood that this approach only provides a proof of security relative to some other problem, not an absolute proof of security.1
1This is a similar situation to proving that a problem is NP-complete: it proves that the given problem is at least as difficult as any other NP-complete problem, but it does not provide an absolute proof of the computational difficulty of the problem.
- unconditional security
- This measure concerns the security of cryptosystems when there is no bound placed on the amount of computation that Oscar is allowed to do. A cryptosystem is defined to be unconditionally secure if it cannot be broken, even with infinite computational resources.
- This measure concerns the computational effort required to break a cryptosystem. We might define a cryptosystem to be computationally secure if the best algorithm for breaking it requires at least N operations, where N is some specified, very large number. The problem is that no known practical cryptosystem can be proved to be secure under this definition. In practice, people will call a cryptosystem “computationally secure” if the best known method of breaking the system requires an unreasonably large amount of computer time (but this is of course very different from a proof of security). Another approach is to provide evidence of computational security by reducing the security of the cryptosystem to some well-studied problem that is thought to be difficult. For example, it may be able to prove a statement of the type “a given cryptosystem is secure if a given integer n cannot be factored.” Cryptosystems of this type are sometimes termed “provably secure,” but it must be understood that this approach only provides a proof of security relative to some other problem, not an absolute proof of security.1
When we discuss the security of a cryptosystem, we should also specify the type of attack that is being considered. In Chapter 1, we saw that neither the Shift Cipher, the Substitution Cipher nor the Vigenere Cipher is computationally secure against a ciphertext-only attack (given a sufficient amount of ciphertext).
What we will do in this section is to develop the theory of cryptosystems that are unconditionally secure against a ciphertext-only attack. It turns out that all three of the above ciphers are unconditionally secure if only one element of plaintext is encrypted with a given key!
The unconditional security of a cryptosystem obviously cannot be studied from the point of view of computational complexity, since we allow computation time to be infinite. The appropriate framework in which to study unconditional security is probability theory. We need only elementary facts concerning probability; the main definitions are reviewed now.
DEFINITION 2.1 Suppose X and Y are random variables. We denote the probability that X takes on the value x by p(x), and the probability that Y takes on the value y by p(y). The joint probability p(x, y) is the probability that X takes on the value x and Y takes on the value y. The conditional probability p(x|y) denotes the probability that X takes on the value x given that Y takes on the value y. The random variables X and Y are said to be independent if p(x, y) = p(x)p(y) for all possible values x of X and y of Y.
Joint probability can be related to conditional probability by the formula
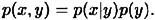
Interchanging x and y, we have that
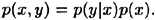
From these two expressions, we immediately obtain the following result, which is known as Bayes’ Theorem.
THEOREM 2.1 (Bayes’ Theorem)
If p(y) > 0, then
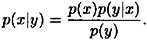
COROLLARY 2.2
X and Y are independent variables if and only if p(x|y) = p(x) for all x, y.
Throughout this section, we assume that a particular key is used for only one encrypion. Let us suppose that there is a probability distribution on the plaintext space,  . We denote the a priori probability that plaintext x occurs by
. We denote the a priori probability that plaintext x occurs by 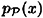 . We also assume that the key K is chosen (by Alice and Bob) using some fixed probability distribution (often a key is chosen at random, so all keys will be equiprobable, but this need not be the case). Denote the probability that key K is chosen by
. We also assume that the key K is chosen (by Alice and Bob) using some fixed probability distribution (often a key is chosen at random, so all keys will be equiprobable, but this need not be the case). Denote the probability that key K is chosen by 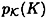 . Recall that the key is chosen before Alice knows what the plaintext will be. Hence, we make the reasonable assumption that the key K and the plaintext x are independent events.
. Recall that the key is chosen before Alice knows what the plaintext will be. Hence, we make the reasonable assumption that the key K and the plaintext x are independent events.
The two probability distributions on  and
and  induce a probability distribution on
induce a probability distribution on 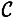 . Indeed, it is not hard to compute the probability
. Indeed, it is not hard to compute the probability 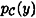 that y is the ciphertext that is transmitted. For a key
that y is the ciphertext that is transmitted. For a key 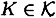 , define
, define
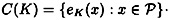
That is, C(K) represents the set of possible ciphertexts if K is the key. Then, for every 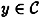 , we have that
, we have that
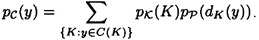
We also observe that, for any 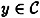 and
and 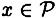 , we can compute the conditional probability,
, we can compute the conditional probability, 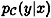 (i.e., the probability that y is the ciphertext, given that x is the plaintext) to be
(i.e., the probability that y is the ciphertext, given that x is the plaintext) to be
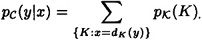
It is now possible to compute the conditional probability 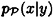 (i.e., the probability that x is the plaintext, given that y is the ciphertext) using Bayes’ Theorem. The following formula is obtained:
(i.e., the probability that x is the plaintext, given that y is the ciphertext) using Bayes’ Theorem. The following formula is obtained:
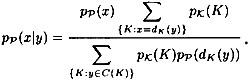
Observe that all these calculations can be performed by anyone who knows the probability distributions.
We present a toy example to illustrate the computation of these probability distributions.
Example 2.1
Let 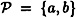 with
with 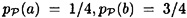 . Let
. Let 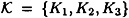 with
with 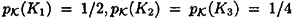 . Let
. Let 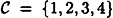 , and suppose the encryption functions are defined to be
, and suppose the encryption functions are defined to be 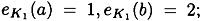 ;
; 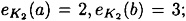 ; and
; and 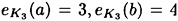 . This cryptosystem can be represented by the following encryption matrix:
. This cryptosystem can be represented by the following encryption matrix:
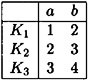
We now compute the probability distribution 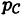 . We obtain
. We obtain
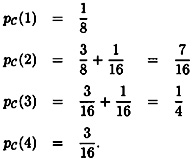
Now we can compute the conditional probability distributions on the plaintext, given that a certain ciphertext has been observed. We have:
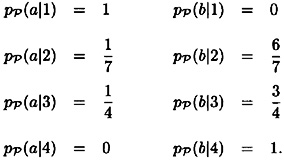
We are now ready to define the concept of perfect secrecy. Informally, perfect secrecy means that Oscar can obtain no information about plaintext by observing the ciphertext. This idea is made precise by formulating it in terms of the probability distributions we have defined, as follows.
| Previous | Table of Contents | Next |
Copyright © CRC Press LLC
EAN: 2147483647
Pages: 133