Relational Databases
RDBMSRDBMS is an abbreviation of relational database management system . The history of databases is fascinating, and the reader is encouraged to spend some time researching . For our purposes here, know that the major hallmarks of an RDBMS are the following:
RelationshipsThe next concept we have to be clear about is the RDBMS idea of relationships . The idea is actually very simple because we all naturally make relationships between bits of data every day of our lives. As a concrete example, think about summarizing all the courses you and your friends have taken over the years. Some were at workshops, some online, some from books, some in formal classes. You would naturally want to just jot your name down, and then list the courses one after the other, then the next name and all of that person's courses. However, this approach would be pretty messy in a couple of years after all of you had taken several more courses, wouldn't it? You would run out of room and have to start writing in the columns and margins. So almost intuitively you would create two tables ”one for names and other personal info , and the other for courses that were taken. The information would now look like this (italic typeface identifies the primary keys, which we will discuss shortly, in the section on constraints):
Again, what you've done is to make a natural connection, or relationship , between the two sets of data. This is very important for your understanding of how we will later create and link all the tables in your demonstration database. To summarize, there are only a couple of types of relationships commonly used in the RDBMS world:
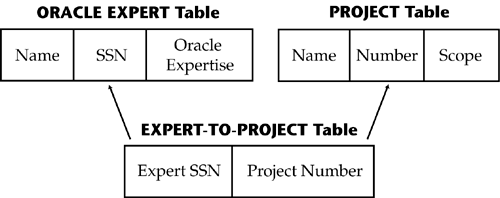
In this example of a many-to-many relationship, we have three tables: (1) the ORACLE EXPERT table, (2) the PROJECT table, and (3) the EXPERT-TO-PROJECT table. Think about this. We want to know which projects each of our experts has, and we want to know who all the experts working on a particular project are. So we can try to list all the projects for an expert in the ORACLE EXPERT table, and we can try to list all the experts on a project in the PROJECT table. This approach quickly becomes a nightmare when project staffing changes or projects are added or dropped. If we did it this way, we would be constantly changing the two tables just trying to keep up. Instead, we create another table, the EXPERT-TO-PROJECT intersect table. Using this table, we can quickly get a list of all projects and who is working on them, and using just that little bit of information, we can go to the bigger tables and get detailed information on each expert and each employee. This idea may be somewhat new to you, but try to work at grasping the general concept. You will see it again in later chapters, where we actually use it. For example, we will have a link table that is used to get information from both a question table and a test table. So stay tuned ; Chapter 5, where this theory is put into practice, is just around the corner. This is how tables link to each other, through relationships. To summarize, basic storage in an RDBMS is in tables . Tables have columns (Name, Address, Phone Number, and so on) and rows , where the data is stored. All the columns of a row represent an instance of that row. A column can have additional qualifications. For example, it can be a key, and constraints can be added. Tables and relationships are the heart of an RDBMS. ConstraintsConstraints are another important piece of the RDBMS picture, one that you will be using as you develop your guerrilla database. In brief, a constraint is a rule or set of rules that apply to a column or combination of columns. Before we terrorize you with the various kinds of constraints, let's take an English-language look at one that you've already done automatically. In the preceding PERSON table, notice the Person ID column. Without thinking, you knew that this had to be a unique column, or the table would not make any sense, right? Making this data element unique is a constraint. What you actually did was create a primary key for the table, and one of the characteristics of a primary key is that it is unique. A Quick Word about Primary Keys All the other pieces of data in a row must depend on the primary key column. In the PERSON table example, not much besides the person ID is unique. For example, several people can share the same phone number and address. Hence the person ID is the logical key, and because it is really unique for each person, it can be the primary key. Here are some other constraints:
A Word on NULL NULL is a unique concept. It is the absence of any value; it is not zero or spaces. Adding the constraint NOT NULL to a column means that data must be entered when the row is created that uses that column. The NOT NULL constraint is a good way to make sure your users do not skip important columns when adding information to a table. Jumping ahead a bit, you can get a look at the constraints on a table by checking the data dictionary. Appropriate commands are:
The data dictionary is introduced on the following page and will be covered in more detail in Chapter 10. |

EAN: 2147483647
Pages: 84