2.3 XML
|
| < Day Day Up > |
|
XML makes it easy for a computer to describe, read, and generate data. It uses a structure of tags in a manner similar to HTML, but in this case the tags can be fully customized to suit a particular self-describing requirement. The concept of customizing tags enables a common definition of entities or documents to be created-such as invoices-that in turn allows organizations to transfer data relatively easily. Indeed, there is a Web site, (www.biztalk.org) designed to act as a community library for organizations to share these common document types.
An interesting point to note is that if you see a tag in XML such as <p>
it can refer to anything-but it will not indicate a new paragraph!
Here is an example of some simple XML code:
<?xml version="1.0"> <Library> <Book> <Title>Biography of Colonel Stephens</Title> <Author>John Scott Morgan</Author> </Book> <Picture> <Title>Fishermen</Title> <Artist>J R Hartley</Artist> </Picture> </Library>
How is the code structured? The first line declares the version of XML being used and acts as a processing instruction. This is an attribute, because it takes the form of name="value" . While not strictly needed, it is a good practice to include this statement.
The tag <Library> is called the enclosing element, which all XML documents must have irrespective of whether they contain the processing instruction. There are two subelements, indicated by the </Book> and </Picture> tags.
In fact, the tags act as data delimiters, and the application reading the XML will need to interpret the specific data. Interestingly, by simply reading the XML code the chances are you could work out what the XML file was referring to. This is the real beauty of XML-the fact that it is selfdescribing.
Now, an XML document needs to be well-formed and valid. By wellformed we are ensuring that the document can be read by a program and transmitted across a network. Specifically, a well-formed piece of XML has the following:
-
All of the document's begin and end tags matching
-
Quotes around attribute values
-
Entities such as macros declared
-
All empty tags defined as <empty/>
By valid we are ensuring that the piece of XML has a document type definition, or DTD. The DTD describes which tags can be used and which nesting levels are permitted within the XML document. In addition, the DTD declares entities, which are pieces of text that can be reused in the XML document, but only need to be sent across the network once. The document validity also ensures that tags are ordered properly, making them easier to reuse when needed.
Staying with our library theme, here is a simple DTD used to describe a book library:
<!ELEMENT Library (Book*)> <!ELEMENT Book ( Title, Author*, Copyright )> <!ELEMENT Title (#PCDATA)> <!ELEMENT Author (#PCDATA)> <!ELEMENT Copyright (#PCDATA)>
The simple elements are represented by the element name followed by the contents, in this case described as character data. In this case, the element Title will have character data:
<!ELEMENT Title (#PCDATA)>
Elements can also contain other elements, and if they can have zero or more elements, then the element is followed by an asterisk (*):
<!ELEMENT Book ( Title, Author*, Copyright )>
This would tell us that the book element can have one title, many authors (i.e., coauthors), and one copyright owner.
Using a DTD is quite straightforward, as the following code segment shows:
<?xml version="1.0" ?> <!DOCTYPE Library PUBLIC "." "Library.dtd" > <Library> <Book> <Title>The Road Ahead</Title> <Author>Bill Gates</Author> <Copyright>1998</Copyright> </Book> <Book> <Title>Trainspotters Ball</Title> <Author>Stanley</Author> <Copyright>2001</Copyright> </Book> </Library>
The XML parser, probably your browser in most instances, will load the DTD ' Library.dtd " and then use it to validate the rest of the document. As you may realize, DTDs are rather limited because they define the element structure and the nature of the data allowed in each of the elements. This limitation is another example of SGML's influence on XML, and something had to be done to improve this for better use across the Internet.
In place of a DTD, an XML author can use an XML schema. In fact, this is fast becoming the most appropriate technique, especially since Simple Object Access Protocol (SOAP) see Chapter 9 specifically says that a SOAP message must not contain a DTD.
2.3.1 XML Schemata
XML schemata are supersets of DTDs. Although they are both used to structure an XML document, only the XML schema is capable of providing type information.
Here is the same library example, but represented as an XML schema:
<schema xmlns:xsd= "http://www.w3.org/2001/XMLSchema" targetNamespace= "http://www.testnamespace.com/LibrarySchema.xml" xmlns:xsi= "http://www.w3.org/2001/XMLSchema-instance"> <complexType name="Book"> <element type="Title"></element> <element type="Author"></element> <element type="Copyright"></element> </complexType> <simpleType name="Title" xsi:type="string"> </simpleType> <simpleType name="Author" xsi:type="string"> </simpleType> <simpleType name="Copyright" xsi:type="integer"> </simpleType> </schema>
The schema is another XML file, and to use it, the appropriate namespace is referenced in the document as follows:
<myLibrary:Library xmlns:myLibrary= "http://www.testnamespace.com/LibrarySchema.xml"> <myLibrary:Book> <myLibrary:Title>GER Y4 at Stratford </myLibrary:Title> <myLibrary:Author>Doug Hewson </myLibrary:Author> <myLibrary:Copyright>1991 </myLibrary:Copyright> </myLibrary:Book> <myLibrary:Book> <myLibrary:Title>Growler Confessions </myLibrary:Title> <myLibrary:Author>Dan Jeavons </myLibrary:Author> <myLibrary:Copyright>2001 </myLibrary:Copyright> </myLibrary:Book> </myLibrary:Library>
Note the line of text that reads
<myLibrary:Library xmlns:myLibrary= "http://www.testnamespace.com/LibrarySchema.xml">
This is a unique value that can be used to tell the parser to use the set of names defined and identified in the following URI location. All of the elements contained within the xmlns tags are part of the specified namespace unless explicitly stated otherwise.
2.3.2 XML Namespaces
A namespace allows a given set of unique names to be used within a given context. This is used to prevent the names of elements clashing within a document. In the Mylibrary example, we have an element called title , which in this instance is a book title.
In another context this could be a person's title, such as Mr., Mrs., or Ms. All of this could be quite confusing, so by using the libraryschema.xml
namespace, we are saying: that in our example title means a book title.
This technique has been used for a while in C++, and, while sometimes seen as an unfortunate overhead, this is the way the World Wide Web Consortium (W3C) has determined it will work.
2.3.3 XML API
XML is only useful if you can do something with it. Programmatic access to XML or a piece of software that is capable of reading an XML document is called an XML API or, more often, an XML processor.
Currently there are two commonly used XML processors that are gaining acceptance: the document object model, or DOM, and the Simple API for XML, or SAX.
DOM
The DOM is an internal tree structure, which is built to represent an XML document. When the XML processor loads the XML document, it builds an in-memory tree, which can then be programmatically accessed or traversed using the names of the methods defined in the DOM.
SAX
Imagine loading a large XML document into memory. This overhead is one of the significant downsides of using the DOM approach, and it led to a group of developers joining together to define a new approach.
With SAX the XML processor, after reading each element in the XML document, calls a custom event handler to just-in-time process the element and data. While it does offer improved performance, it does limit a developer's flexibility and needs to be assessed alongside the DOM approach.
2.3.4 Transforming XML
Traversing the DOM tree to extract elements can be both tedious and time consuming, reading each element and then building, for example, an HTML document. This is probably the most frequently needed transformation-taking XML data and turning these data into HTML for users to view.
To improve the efficiency of transforming XML documents, the W3C introduced a specification for XML transformations called the Extensible Stylesheet Language, or XSL, and a simple query language called XSL Patterns.
Using XSL, developers now have the ability to perform complex transformations. A good example is receiving an XML document that does not support the vocabulary of your own XML document. By using an XSL transformation, you can turn the XML document into something that your document will understand (See Figure 2.1).
Here is an example of transforming an XML file. We take the base XML file:
<?xml version="1.0"?> <Books> <Book cheap="Afraid not"> <name>Picture Book</name> <description>Gold embossed with nice writing.</ description> <price>1000</price> </Book> </Books>
and we transform it into this HTML file for our users to view:
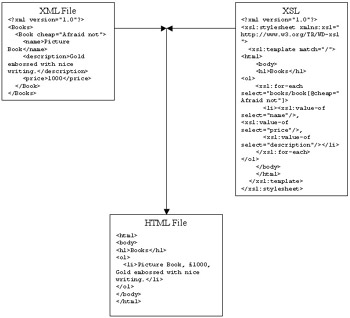
Figure 2.1: Creating an HTML file using XSL.
<html> <body> <h1>Books</h1> <ol> <li>Picture Book, £1000, Gold embossed with nice writing.</li> </ol> </body> </html>
So, we apply the following XSL file:
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl=" http://www.w3.org/TR/WD-xsl"> <xsl:template match="/"> <html> <body> <h1>Books</h1> <ol> <xsl:for-each select="books/book[@cheap="Afraid not"]> <li><xsl:value-of select="name"/>, <xsl:value-of select="price"/>, <xsl:value-of select="description"/></li> </xsl:for-each> </ol> </body> </html> </xsl:template> </xsl:stylesheet>
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 136