Finding the Holes
| |
The most challenging aspect to managing storage networking availability is collecting, reporting, and analyzing the information, while the most important aspect of business application performance is accessing data. The data may be stored on disk, tape, optical, temporary cache, or other device. The location of the data becomes irrelevant; however, if the application cannot get to it, or the paths to the data are congested or critically impacted, the performance of the application will degrade, or worse , become unavailable.
The key to successfully monitoring and managing the performance of business applications is the consistent and proactive management of the critical paths to application data. Although software tools are becoming available, they provide a disparate, incompatible, and inconsistent view of storage information, not to mention storage networking configurations. No single tool provides consistent, proactive management functions that associate business applications with application data. IT management must choose from an assortment of tools that provide only discrete levels of empirical information, ranging from operating system metrics and database metrics, to I/O and disk metrics. IT users bear the burden of correlating these seemingly unrelated sets of information in an attempt to understand the effects of workloads on storage networking resources.
Where to Look
The deficiencies within storage software management tools are compounded by the requirements, costs, and expertise needed to support an increasing set of server platforms, operating systems, and major application subsystems such as relational database management, messaging, and transactional systems. The following points illustrate some of the challenges in managing storage network configurations, as well as the inefficiencies that contribute to business application availability.
-
Correlation Functions among Distributed Components Storage networks are distributedmeaning events happening on one node device or fabric switch can seriously degrade performance throughout the entire system. The ability to correlate important aspects of performance information as it effects the business application currently must be performed as a set of manual tasks .
-
Proactive Trending Todays IT managers are expected to effectively drive the bus while monitoring performance through the rearview mirror. Literally all reporting and trending is historical. The information which ultimately reaches the IT user is past tense and provides little value in determining real-time solutions to poorly performing business applications. Consequently, a response to an availability problem with a production configuration may require significantly more time to address.
-
Identification of the Root Cause of a Problem The effects of the conditions stated previously means it is unlikely that the information discovered and reported to the IT user will provide any sort of root cause analysis. This makes the problem management aspect of availability problematic . The information provided to identify and correct the problem would likely address only the symptoms, leading to reoccurring results.
Finding, collecting, and reporting performance information as indicated in the preceding section will be difficult. As such, this should enter into the availability formulae when considering the appropriate configuration and resources. There are multiple sources that IT storage administrators can access to find this information. Given that it remains a manual effort to coalesce the data into something of value, the sources can provide a key to building a historical database of performance and availability information. Particular to the storage networks, these sources are the management information base or MIB (provided within the switch fabric operating system or the NAS RTOS), the hardware activity logs within the specific devices (such as the SCSI enclosures services (SES)), and the OS-dependent activity logs and files that are part of the operating systems attached to the SAN or NAS configurations.
This appears as a loose confederation of information, and it is. However, if one sets up a logical organization of sources, the ability to find, select, and utilize existing tools, and develop internal expertise in utilizing these resources will help a great deal in monitoring availability. The following are some guidelines for both NAS and SAN:
-
NAS RTOS Essentially everything that is active within the NAS device is available through the NAS operating system. Although vendors have enhanced their offerings for manageability services for monitoring and reporting, they remain proprietary to the vendor and closed to user customization.
-
NAS Configuration Looking at NAS devices as a total storage configuration requires that external sources of information be identified and accessed. These are multiple and can be defined through network and remote server logs. Again, these require the necessary manual activity to coalesce the data into meaningful information for availability purposes.
-
Fabric Operating System Information Available within the switch MIBs. (Note that with multiple switches there will be multiple MIBs.) In addition, many switch vendors are enhancing their in-band management utilities and will provide more sophisticated services to access FC MIBs. The same can be said for storage management software vendors that are increasing their efforts to provide in- band software management services that communicate with external products running on the attached servers.
-
HBA Information Available within the attached node server. However, its important to note that HBA information coming from system log files must be integrated somehow into a single view. Although this may require additional IT activity, it can and should be accomplished with third-party storage management tools and system collection repositories such as the Common Information Model (CIM).
-
Storage Information Available within the attached node device through either MIBs, SES utilities, or activity log files generally operating within the RAID control units.
-
OS Information Available within the attached node server and dependent on the OS (for example, UNIX or Windows). There are multiple sources within UNIX environments to support, find, and select storage performance information. This also includes existing storage management products that support out-of-band management processing. Within Windows environments is a relatively new source: the Common Information Management database. This is an object database that provides activity information for all processes within the server and has become compatible with a large number of storage networking and system vendors.
-
Application Information Available within the attached servers are multiple sources of information depending on the type of application and its dependent software elements (for example, databases, log, and configuration files). Some of this information is being identified within the CIM database for Windows environments to augment third-party management software suites. For UNIX environments, there are third-party systems management software suites with CIM implementation just beginning. The inherent challenge of these approaches is the correlation of the application information to storage management activity and information.
Note The problem with any of these strategies, although well intentioned, is the increasing overhead these applications have on switch performance, cost, and flexibility. As pointed out in Chapters 11 and 15, the operating capacities within the NAS RTOS and SAN FC fabric operating systems are quite limited.
Data Recovery
An advantage of SAN architecture is the leverage of node communications within the fabric to increase availability within the data maintenance processes. Within the data center are multiple maintenance and support applications necessary to maintain platform environments. Of these, none are more basic than backing up files and data for later recovery. The historical problem with these activities is the time lost to copy the data from online media to offline media, using tape media in most cases.
This integral data center practice can be broken into two major activities, each with their own problematic characteristics. First is the process of copying data from disk volumes and writing out the data to a tape volume. Given the disparity of the devices (see Chapter 6 for more on disk and tape devices), a performance problem is inevitable. However, it goes beyond device disparity and is exacerbated by the software architecture of the copy process that has been integrated into most backup and recovery software products. The problem is simple. The traditional, though arcane operation, requires data to be copied from the disk and buffered in memory within the initiating server. The server then issues a write operation for the data in the buffer and the subsequent I/O operation copies the data to the tape media mounted on the tape drive. This double-write and staging process places a tremendous I/O load on the server executing the copy operation while reserving both the disk device and tape drive during the operation. Figure 22-4 shows how this impacts operations during a typical backup portion of the backup/recovery operation.
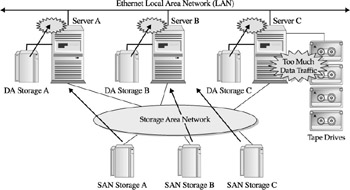
Figure 22-4: Traditional backup processes and their overhead
The second, and most important, part of this process is the recovery operation. As illustrated in Figure 22-4, the backup is the insurance premium to cover any disruptions and corruptions to the current online data, while the recovery operation is the claim payoff so to speak, when a problem has occurred and data needs to be recovered to both an uncorrupt condition and any previous state.
The recovery operation is different from the copy, even though it appears to be the reverse of the operation; it is far more selective regarding the data that needs to be written back to disks. This requires additional and specific parameters to recover data, such as the specific data to be recovered, from a specific time period, which should be restored to a specific state. The most complex of these operations begins when RDBMSs are involved. This is due to the state condition that needs to be restored during the recovery operation in order to bring the database table to a specific state through the processing of transactional log files.
Enter the Storage Area Network. Figure 22-5 demonstrates the capability of devices within the SAN configuration to communicate with each other, thereby allowing many of the server-based, data-centric maintenance/support applications to be optimized. The tremendous I/O load from typical backup operations can now be offloaded from the initiating server. This requires the data copy functions to be performed from storage network node device to storage network node device (in other words, disk-to-disk, disk-to-optical, disk-to-tape, and so on). Given that the bulk of elapsed time during the traditional backup operation is the double writing of data to the server and then to the backup device, such as tape, this time is optimized through a direct copy operation under the control of the FC fabric working in conjunction with the backup/recovery software that still controls the overall process.
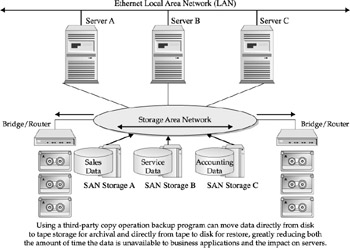
Figure 22-5: Storage network backup and recovery
For example, if a typical copy operation used 100 I/O operations from the disk drive/ controller to the server path and a subsequent 200 I/O operations to the tape unit, that requires a net 300 I/O operations that the server must perform, not to mention the elapsed time in reserving the disk and tape units. By employing the SAN operation of the direct node communications using the extended copy operation of FC fabric operations, the server I/O can be reduced to a minimum of two to initiate the operation of the fabric in order to directly copy data from the disk to the tape units. The copy operation can thus be performed one time at the speed of FC hardware: 100MB/s with latency for tape bandwidth operations and buffers. Performance depends largely on the specifics of the data, as well as the switch and tape configurations, but suffice to say, the savings will be significant.
Keep in mind that the preceding example was only for the backup portion of the operations. We must also factor in the recovery part. Nevertheless, the savings will be similar to the copy operationsthat is, copying the information from the tape to the disk. The operation executes the same way: by the backup/recovery software communicating with the SAN fabric, and the execution of the extended copy command through the fabric. The extenuating circumstances will be the destination of the recovery, the extent of the post processing of transaction logs, and the activity and location of the tape drives that must mount and process the log files.
The significant savings of copying data within a SAN should be taken into context regarding both backup and recovery, because the value in the backup and recovery operation to external service levels is the R part, or the recovery. In the end, the time it takes to restore data and application services is key.
Most business applications suffer during this maintenance process because data is unavailable during the time it is being copied. Although necessary for maintaining storage backup procedures and policies, this type of operation (that is, copying data directly from device-to-device) can greatly improve the availability of business applications by reducing the time in which data is unavailable.
Unfortunately, NAS differs in its server-based architecture (albeit a thin server) and its attachment to an Ethernet network. Backup and recovery operations are generally handled by a dedicated server within the subnetwork. NAS vendors have extended their solutions to include SCSI tape attachment. This allows for a self-contained NAS solution which includes its own backup/recovery system. Although its important for NAS devices in remote locations to have an automated backup process, the capability of NAS to participate within the data center tape library solutions is likely to be a preferred solution for storage administrators.
NAS integration into enterprise-level applications is driving vendors to include data mirroring, snapshot capability, and self-contained backup/recovery operations. These functions have been extended into the NAS hardware and software solutions as well as their integration with FC storage. As this evolves, the ability to participate in device-to-device communication through an extended SAN fabric will make the extended copy operation possible.
| |
EAN: 2147483647
Pages: 192