Casing
| Latin script languages have a concept of upper and lower case, which all developers are familiar with. However, not all languages have this concept or implement it in the same way. Some languages (e.g., Japanese) are case-less. Others exist only as upper case (e.g., Khutsuri) or lower case (e.g., Nushkuri). For these languages, no case conversions should occur. If you intend to support Azeri or Turkish, you should be aware of the special case of the letter I. Most Latin script languages have two I characters: a Capital Letter I (without a dot on top) and a Small Letter i (with a dot on top). Azeri and Turkish have two more I characters: a Capital Letter i (with a dot on top) and a Small Letter
From these two tables, it can be seen that the Turkish lowercase equivalent of Latin Capital I is not the same as the English lowercase equivalent, and the Turkish uppercase equivalent of Latin Small I is not the same as the English uppercase equivalent. The problem is illustrated in the following code fragment: CultureInfo cultureInfo = new CultureInfo("en"); string test = "Delphi is in italics"; string testUpper = "DELPHI IS IN ITALICS"; if (test.ToUpper(cultureInfo).CompareTo(testUpper) == 0) Text = "Equal"; else Text = "Not equal"; The two strings are equal if the culture is "en", but they are not equal if the culture is "tr". How you handle this difference in code is dependent upon the nature of the strings being compared. If you were comparing a company name typed by a user, a case-less conversion using String.Compare and passing the CurrentCulture would be the safest comparison. If, however, you were comparing a string that could be considered a programmatic element against a known stringsay, an XML tag nameyou should use the invariant culture to perform the comparison, to ensure that culture-specific casing rules do not change the success of the comparison. |
 (without a dot on top). You need to be aware of this because the rules for conversion between upper and lower case among these four letters are different for Azeri and Turkish cultures than they are for other cultures. (These special rules are known as Turkic Casing Rules.) Tables 6.4 and 6.5 show the effects of converting each of the four letters between upper and lower case using the "en" and "TR", cultures respectively.
(without a dot on top). You need to be aware of this because the rules for conversion between upper and lower case among these four letters are different for Azeri and Turkish cultures than they are for other cultures. (These special rules are known as Turkic Casing Rules.) Tables 6.4 and 6.5 show the effects of converting each of the four letters between upper and lower case using the "en" and "TR", cultures respectively.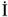

EAN: 2147483647
Pages: 213
- Chapter IV How Consumers Think About Interactive Aspects of Web Advertising
- Chapter VI Web Site Quality and Usability in E-Commerce
- Chapter IX Extrinsic Plus Intrinsic Human Factors Influencing the Web Usage
- Chapter XII Web Design and E-Commerce
- Chapter XVIII Web Systems Design, Litigation, and Online Consumer Behavior