Section 7.5. The execve() System Call
7.5. The execve() System CallThe execve() system call is the only kernel-level mechanism available to user programs to execute another program. Other user-level program-launching functions are all built atop execve() [bsd/kern/kern_exec.c]. Figure 757 shows an overview of execve()'s operation. execve() initializes and partially populates an image parameter block (struct image_params [bsd/sys/imgact.h]), which acts as a container for passing around program parameters between functions called by execve(), while the latter is preparing to execute the given program. Other fields of this structure are set gradually. Figure 756 shows the contents of the image_params structure. Figure 756. Structure for holding executable image parameters during the execve() system call
Figure 757. The operation of the execve() system call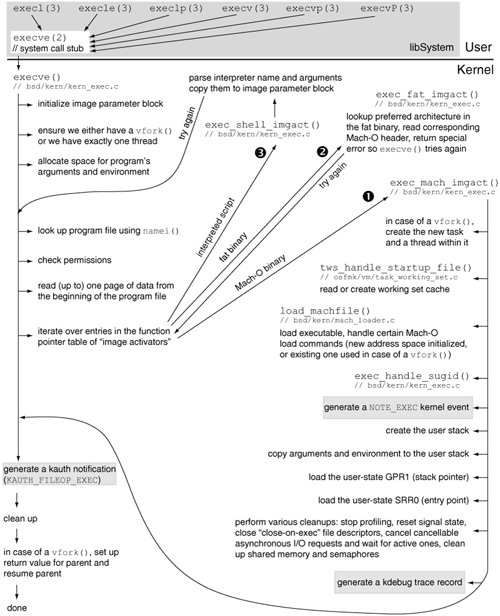 execve() ensures that there is exactly one thread within the current task, unless it is an execve() preceded by a vfork(). Next, it allocates a block of pageable memory for holding its arguments and for reading the first page of the program executable. The size of this allocation is (NCARGS + PAGE_SIZE), where NCARGS is the maximum number of bytes allowed for execve()'s arguments.[19]
// bsd/sys/param.h #define NCARGS ARG_MAX // bsd/sys/syslimits.h #define ARG_MAX (256 * 1024) execve() saves a copy of its first argumentthe program's path, which may be relative or absoluteat a specifically computed offset in this block. The argv[0] pointer points to this location. It then sets the ip_tws_cache_name field of the image parameter block to point to the filename component of the executable's path. This is used by the kernel's task working set (TWS) detection/caching mechanism, which we will discuss in Chapter 8. However, execve() does not perform this step if TWS is disabled (as determined by the app_profile global variable) or if the calling process is running chroot()'ed. execve() now calls namei() [bsd/vfs/vfs_lookup.c] to convert the executable's path into a vnode. It then uses the vnode to perform a variety of permission checks on the executable file. To do so, it retrieves the following attributes of the vnode: the user and group IDs, the mode, the file system ID, the file ID (unique within the file system), and the data fork's size. The following are examples of the checks performed.
execve() then reads the first page of data from the executable into a buffer within the image parameter block, after which it iterates over the entries in the image activator table to allow a type-specific activator, or handler, to load the executable. The table contains activators for Mach-O binaries, fat binaries, and interpreter scripts. // bsd/kern/kern_exec.c struct execsw { int (* ex_imgact)(struct image_params *); const char *ex_name; } execsw[] = { { exec_mach_imgact, "Mach-o Binary" }, { exec_fat_imgact, "Fat Binary" }, { exec_shell_imgact, "Interpreter Script" }, { NULL, NULL } };Note that the activators are attempted in the order that they appear in the tabletherefore, an executable is attempted as a Mach-O binary first and as an interpreter script last. 7.5.1. Mach-O BinariesThe exec_mach_imgact() [bsd/kern/kern_exec.c] activator handles Mach-O binaries. It is the most preferred activator, being the first entry in the activator table. Moreover, since the Mac OS X kernel supports only the Mach-O native executable format, activators for fat binaries and interpreter scripts eventually lead to exec_mach_imgact(). 7.5.1.1. Preparations for the Execution of a Mach-O Fileexec_mach_imgact() begins by performing the following actions.
In the case of vfork(), the child process is using the parent's resources at this pointthe parent is suspended. In particular, although vfork() would have created a BSD process structure for the child process, there is neither a corresponding Mach task nor a thread. exec_mach_imgact() now creates a task and a thread for a vfork()'ed child. Next, exec_mach_imgact() calls task_set_64bit() [osfmk/kern/task.c] with a Boolean argument specifying whether the task is 64-bit or not. task_set_64bit() makes architecture-specific adjustments, some of which depend on the kernel version, to the task. For example, in the case of a 32-bit process, task_set_64bit() deallocates all memory that may have been allocated beyond the 32-bit address space (such as the 64-bit comm area). Since Mac OS X 10.4 does not support TWS for 64-bit programs, task_set_64bit() disables this optimization for a 64-bit task. In the case of executables for which TWS is supported and the ip_tws_cache_name field in the image parameter block is not NULL, exec_mach_imgact() calls tws_handle_startup_file() [osfmk/vm/task_working_set.c]. The latter will attempt to read a per-user, per-application saved working set. If none exists, it will create one. 7.5.1.2. Loading the Mach-O Fileexec_mach_imgact() calls load_machfile() [bsd/kern/mach_loader.c] to load the Mach-O file. It passes a pointer to a load_result_t structure to load_machfile()the structure's fields will be populated on a successful return from load_machfile(). // bsd/kern/mach_loader.h typedef struct _load_result { user_addr_t mach_header; // mapped user virtual address of Mach-O header user_addr_t entry_point; // thread's entry point (from SRR0 in thread state) user_addr_t user_stack; // thread's stack (the default, or from GPR1 in // thread state) int thread_count; // number of thread states successfully loaded unsigned int /* boolean_t */ unixproc : 1, // TRUE if there was an LC_UNIXTHREAD dynlinker : 1, // TRUE if dynamic linker was loaded customstack : 1, // TRUE if thread state had custom stack : 0; } load_result_t; load_machfile() first checks whether it needs to create a new virtual memory map[20] for the task. In the case of vfork(), a new map is not created at this point, since the map belonging to the task created by execve() is valid and appropriate. Otherwise, vm_map_create() [osfmk/vm/vm_map.c] is called to create a new map with the same lower and upper address bounds as in the parent's map. load_machfile() then calls parse_machfile() [bsd/kern/mach_loader.c] to process the load commands in the executable's Mach-O header. parse_machfile() allocates a kernel buffer and maps the load commands into it. Thereafter, it iterates over each load command, processing it if necessary. Note that two passes are made over the commands: The first pass processes commands the result of whose actions may be required by commands processed in the second pass. The kernel handles only the following load commands.
Standard Mac OS X Mach-O executables contain several LC_SEGMENT (or LC_SEGMENT_64, in the case of 64-bit executables) commands, one LC_UNIXTHREAD command, one LC_LOAD_DYLINKER command, and others that are processed only in user space. For example, a dynamically linked executable contains one or more LC_LOAD_DYLIB commandsone for each dynamically linked shared library it uses. The dynamic linker, which is a Mach-O executable of type MH_DYLINKER, contains an LC_THREAD command instead of an LC_UNIXTHREAD command. parse_machfile() calls load_dylinker() [bsd/kern/mach_loader.c] to process the LC_LOAD_DYLINKER command. Since the dynamic linker is a Mach-O file, load_dylinker() also calls parse_machfile()recursively. This results in the dynamic linker's entry point being determined as its LC_THREAD command is processed.
In the case of a dynamically linked executable, it is the dynamic linkerand not the executablethat starts user-space execution. The dynamic linker loads the shared libraries that the program requires. It then retrieves the "main" function of the program executablethe SRR0 value from the LC_UNIXTHREAD commandand sets the main thread up for execution. For regular executables (but not for the dynamic linker), parse_machfile() also maps system-wide shared regions, including the comm area, into the task's address space. After parse_machfile() returns, load_machfile() performs the following steps if it earlier created a new map for the task (i.e., if this is not a vfork()'ed child).
At this point, the child task has exactly one thread, even in the vfork() case, where a single-threaded task was explicitly created by execve(). load_machfile() now returns successfully to exec_mach_imgact(). 7.5.1.3. Handling Setuid and Setgidexec_mach_imgact() calls exec_handle_sugid() [bsd/kern/kern_exec.c] to perform special handling for setuid and setgid executables. exec_handle_sugid()'s operation includes the following.
7.5.1.4. Execution Notificationexec_mach_imgact() then posts a kernel event of type NOTE_EXEC on the kernel event queue of the process to notify that the process has transformed itself into a new process by calling execve(). Unless this is an execve() after a vfork(), a SIGTRAP (TRace trap signal) is sent to the process if it is being traced. 7.5.1.5. Configuring the User Stackexec_mach_imgact() now proceeds to create and populate the user stack for an executablespecifically one whose LC_UNIXTHREAD command was successfully processed (as indicated by the unixproc field of the load_result structure). This step is not performed for the dynamic linker, since it runs within the same thread and uses the same stack as the executable. In fact, as we noted earlier, the dynamic linker will gain control before the "main" function of the executable. exec_mach_imgact() calls create_unix_stack() [bsd/kern/kern_exec.c], which allocates a stack unless the executable uses a custom stack (as indicated by the customstack field of the load_result structure). Figure 758 shows the user stack's creation during execve()'s operation. Figure 758. Creation of the user stack during the execve() system call
Now, user_stack represents one end of the stack: the end with the higher memory address, since the stack grows toward lower memory addresses. The other end of the stack is computed by taking the difference between user_stack and the stack's size. In the absence of a custom stack, user_stack is set to a default value (0xC0000000 for 32-bit and 0x7FFFF00000000 for 64-bit) when the LC_UNIXTHREAD command is processed. create_unix_stack() retrieves the stack size as determined by the RLIMIT_STACK resource limit, rounds up the size in terms of pages, rounds down the stack's address range in terms of pages, and allocates the stack in the task's address map. Note that the VM_FLAGS_FIXED flag is passed to mach_vm_allocate(), indicating that allocation must be at the specified address. In contrast, a custom stack is specified in a Mach-O executable through a segment named __UNIXSTACK and is therefore initialized when the corresponding LC_SEGMENT command is processed. The -stack_addr and -stack_size arguments to ldthe static link editorcan be used to specify a custom stack at compile time. Note in Figure 759 that for a stack whose size and starting point are 16KB and 0x70000, respectively, the __UNIXSTACK segment's starting address is 0x6c000that is, 16KB less than 0x70000. Figure 759. A Mach-O executable with a custom stack
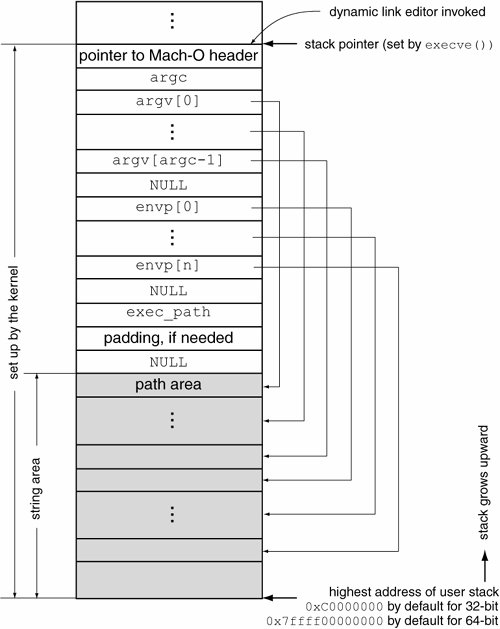
Now that the user stack is initialized in both the custom and default cases, exec_mach_imgact() calls exec_copyout_strings() [bsd/kern/kern_exec.c] to arrange arguments and environment variables on the stack. Again, this step is performed only for a Mach-O executable with an LC_UNIXTHREAD load command. Moreover, the stack pointer is copied to the saved user-space GPR1 for the thread. Figure 760 shows the stack arrangement. Figure 760. User stack arranged by the execve() system call Note in Figure 760 that there is an additional element on the stacka pointer to the Mach-O header of the executableabove the argument count (argc). In the case of dynamically linked executables, that is, those executables for which the dynlinker field of the load_result structure is TRue, exec_mach_act() copies this pointer out to the user stack and decrements the stack pointer by either 4 bytes (32-bit) or 8 bytes (64-bit). dyld uses this pointer. Moreover, before dyld jumps to the program's entry point, it adjusts the stack pointer and removes the argument so that the program never sees it. We can also deduce from Figure 760 that a program executable's path can be retrieved within the program by using a suitable prototype, for example: int main(int argc, char **argv, char **envp, char **exec_path) { // Our program executable's "true" path is contained in *exec_path // Depending on $PATH, *exec_path can be absolute or relative // Circumstances that alter argv[0] do not normally affect *exec_path ... }7.5.1.6. Finishing Upexec_mach_imgact()'s final steps include the following.
On a successful return from exec_mach_imgact(), or any other image activator, execve() generates a kauth notification of type KAUTH_FILEOP_EXEC. Finally, execve() frees the pathname buffer it used with namei(), releases the executable's vnode, frees the memory allocated for execve() arguments, and returns. In the case of an execve() after a vfork(), execve() sets up a return value for the calling thread and then resumes the thread. 7.5.2. Fat (Universal) BinariesA fat binary contains Mach-O executables for multiple architectures. For example, a fat binary may encapsulate 32-bit PowerPC and 64-bit PowerPC executables. The exec_fat_imgact() [bsd/kern/kern_exec.c] activator handles fat binaries. Note that this activator is byte-order neutral. It performs the following actions.
7.5.3. Interpreter ScriptsThe exec_shell_imgact() [bsd/kern/kern_exec.c] activator handles interpreter scripts, which are often called shell scripts since the interpreter is typically a shell. An interpreter script is a text file whose content has # and ! as the first two characters, followed by a pathname to an interpreter, optionally followed by whitespace-separated arguments to the interpreter. There may be leading whitespace before the pathname. The #! sequence specifies to the kernel that the file is an interpreter script, whereas the interpreter name and the arguments are used as if they had been passed in an execve() invocation. However, the following points must be noted.
However, note that it is possible to execute plaintext shell scriptsthat is, those that contain shell commands but do not begin with #!. Even in this case, the execution fails in the kernel and execve() returns an ENOEXEC error. The execvp(3) and execvP(3) library functions, which invoke the execve() system call, actually reattempt execution of the specified file if execve() returns ENOEXEC. In the second attempt, these functions use the standard shell (/bin/sh) as the executable, with the original file as the shell's first argument. We can see this behavior by attempting to execute a shell script containing no #! charactersfirst using execl(3), which should fail, and then using execvp(3), which should succeed in its second attempt. $ cat /tmp/script.txt echo "Hello" $ chmod 755 /tmp/script.txt # ensure that it has execute permissions $ cat execl.c #include <stdio.h> #include <unistd.h> int main(int argc, char **argv) { int ret = execl(argv[1], argv[1], NULL); perror("execl"); return ret; } $ gcc -Wall -o execl execl.c $ ./execl /tmp/script.txt execl: Exec format error $ cat execvp.c #include <stdio.h> #include <unistd.h> int main(int argc, char **argv) { int ret = execvp(argv[1], &(argv[1])); perror("execvp"); return ret; } $ gcc -Wall -o execvp execvp.c $ ./execvp /tmp/script.txt Hello exec_shell_imgact() parses the first line of the script to determine the interpreter name and arguments if any, copying the latter to the image parameter block. It returns a special error that causes execve() to retry execution: execve() looks up the interpreter's path using namei(), reads a page of data from the resultant vnode, and goes through the image activator table again. This time, however, the executable must be claimed by an activator other than exec_shell_imgact(). Note that setuid or setgid interpreter scripts are not permitted by default. They can be enabled by setting the kern.sugid_scripts sysctl variable to 1. When this variable is set to 0 (the default), exec_shell_imgact() clears the setuid and setgid bits in the ip_origvattr (invocation file attributes) field of the image parameter block. Consequently, from execve()'s standpoint, the script is not setuid/setgid. $ cat testsuid.sh #! /bin/sh /usr/bin/id -p $ sudo chown root:wheel testsuid.sh $ sudo chmod 4755 testsuid.sh -rwsr-xr-x 1 root wheel 23 Jul 30 20:52 testsuid.sh $ sysctl kern.sugid_scripts kern.sugid_scripts: 0 $ ./testsuid.sh uid amit groups amit appserveradm appserverusr admin $ sudo sysctl -w kern.sugid_scripts=1 kern.sugid_scripts: 0 -> 1 $ ./testsuid.sh uid amit euid root groups amit appserveradm appserverusr admin $ sudo sysctl -w kern.sugid_scripts=0 kern.sugid_scripts: 1 -> 0 |
EAN: 2147483647
Pages: 161