Section 6.7. System Call Categories
6.7. System Call CategoriesLet us now look at details and examples of the various system call categories, beginning with the most staple variety from a developer's standpoint: the BSD system calls. 6.7.1. BSD System Callsshandler() calls unix_syscall() [bsd/dev/ppc/systemcalls.c] to handle BSD system calls. unix_syscall() receives as its argument a pointer to a save areathe process control block. Before we discuss unix_syscall()'s operation, let us look at some relevant data structures and mechanisms. 6.7.1.1. Data StructuresBSD system calls on Mac OS X have numbers that start from zero and go as high as the highest numbered BSD system call. These numbers are defined in <sys/syscall.h>. // <sys/syscall.h> #ifdef __APPLE_API_PRIVATE #define SYS_syscall 0 #define SYS_exit 1 #define SYS_fork 2 #define SYS_read 3 #define SYS_write 4 #define SYS_open 5 #define SYS_close 6 ... #define SYS_MAXSYSCALL 370 #endif
Several system call numbers are reserved or simply unused. In some cases, they may represent calls that have been obsoleted and removed, creating holes in the sequence of implemented system calls. Note that the zeroth system callsyscall()is the indirect system call: It allows another system call to be invoked given the latter's number, which is provided as the first argument to syscall(), followed by the actual arguments required by the target system call. The indirect system call has traditionally been used to allow testingsay, from a high-level language like Cof new system calls that do not have stubs in the C library. // Normal invocation of system call number SYS_foo ret = foo(arg1, arg2, ..., argN); // Indirect invocation of foo using the indirect system call ret = syscall(SYS_foo, arg1, arg2, ..., argN); The syscall.h file is generated during kernel compilation by the bsd/kern/makesyscalls.sh shell script,[6] which processes the system call master file bsd/kern/syscalls.master. The master file contains a line for each system call number, with the following entities in each column within the line (in this order):
; bsd/kern/syscalls.master ; ; Call# Cancel Funnel Files { Name and Args } { Comments } ; ... 0 NONE NONE ALL { int nosys(void); } { indirect syscall } 1 NONE KERN ALL { void exit(int rval); } 2 NONE KERN ALL { int fork(void); } ... 368 NONE NONE ALL { int nosys(void); } 369 NONE NONE ALL { int nosys(void); } The file bsd/kern/syscalls.c contains an array of stringssyscallnames[]that contains each system call's textual name. // bsd/kern/syscalls.c const char *syscallnames[] = { "syscall", /* 0 = syscall indirect syscall */ "exit", /* 1 = exit */ "fork", /* 2 = fork */ ... "#368", /* 368 = */ "#369", /* 369 = */ }; We can examine the contents of the syscallnames[] arrayand for that matter, other kernel data structuresfrom user space by reading from the kernel memory device /dev/kmem.[8]
Running nm on the kernel binary gives us the address of the symbol syscallnames, which we can dereference to access the array. $ nm /mach_kernel | grep syscallnames 0037f3ac D _syscallnames $ sudo dd if=/dev/kmem of=/dev/stdout bs=1 count=4 iseek=0x37f3ac | od -x ... 0000000 0032 a8b4 0000004 $ sudo dd if=/dev/kmem of=/dev/stdout bs=1 count=1024 iseek=0x32a8b4 | strings syscall exit fork ... The file bsd/kern/init_sysent.c contains the system call switch table, sysent[], which is an array of sysent structures, containing one structure for each system call number. This file is generated from the master file during kernel compilation. // bsd/kern/init_sysent.c #ifdef __ppc__ #define AC(name) (sizeof(struct name) / sizeof(uint64_t)) #else #define AC(name) (sizeof(struct name) / sizeof(register_t)) #endif __private_extern__ struct sysent sysent[] = { { 0, _SYSCALL_CANCEL_NONE, NO_FUNNEL, (sy_call_t *)nosys, NULL, NULL, _SYSCALL_RET_INT_T }, /* 0 = nosys indirect syscall */ { AC(exit_args), _SYSCALL_CANCEL_NONE, KERNEL_FUNNEL, (sy_call_t *)exit, munge_w, munge_d, _SYSCALL_RET_NONE }, /* 1 = exit */ ... { 0, _SYSCALL_CANCEL_NONE, NO_FUNNEL, (sy_call_t *)nosys, NULL, NULL, _SYSCALL_RET_INT_T }, /* 369 = nosys */ }; int nsysent = sizeof(sysent) / sizeof(sysent[0]); The sysent structure is declared in bsd/sys/sysent.h. // bsd/sys/sysent.h typedef int32_t sy_call_t(struct proc *, void *, int *); typedef void sy_munge_t(const void *, void *); extern struct sysent { int16_t sy_narg; // number of arguments int8_t sy_cancel; // how to cancel, if at all int8_t sy_funnel; // funnel type, if any, to take upon entry sy_call_t *sy_call; // implementing function sy_munge_t *sy_arg_munge32; // arguments munger for 32-bit process sy_munge_t *sy_arg_munge64; // arguments munger for 64-bit process int32_t sy_return_type; // return type } sysent[]; The sysent structure's fields have the following meanings.
Recall that unix_syscall() receives a pointer to the process control block, which is a savearea structure. The system call's arguments are received as saved registers GPR3 through GPR10 in the save area. In the case of an indirect system call, the actual system call arguments start with GPR4, since GPR3 is used for the system call number. unix_syscall() copies these arguments to the uu_arg field within the uthread structure before passing them to the call handler. // bsd/sys/user.h struct uthread { int *uu_ar0; // address of user's saved GPR0 u_int64_t uu_arg[8]; // arguments to current system call int *uu_ap; // pointer to argument list int uu_rval[2]; // system call return values ... };
As we will see in Chapter 7, an xnu thread structure contains a pointer to the thread's user structure, roughly analogous to the user area in BSD. Execution within the xnu kernel refers to several structures, such as the Mach task structure, the Mach thread structure, the BSD process structure, and the BSD uthread structure. The latter contains several fields used during system call processing.
6.7.1.2. Argument MungingNote that uu_arg is an array of 64-bit unsigned integerseach element represents a 64-bit register. This is problematic since a parameter passed in a register from 32-bit user space will not map as is to the uu_arg array. For example, a long long parameter will be passed in a single GPR in a 64-bit program, but in two GPRs in a 32-bit program. unix_syscall() addresses the issue arising from the difference depicted in Figure 614 by calling the system call's specified argument munger, which copies arguments from the save area to the uu_arg array while adjusting for the differences. Figure 614. Passing a long long parameter in 32-bit and 64-bit ABIs
The munger functions are implemented in bsd/dev/ppc/munge.s. Each function takes two arguments: a pointer to the beginning of the system call parameters within the save area and a pointer to the uu_arg array. A munger function is named munge_<encoding>, where <encoding> is a string that encodes the number and types of system call parameters. <encoding> is a combination of one or more of the d, l, s, and w characters. The characters mean the following:
Moreover, multiple munger functions are aliased to a common implementation if each function, except one, is a prefix of another. For example, munger_w, munger_ww, munger_www, and munger_wwww are aliased to the same implementationconsequently, four arguments are munged in each case, regardless of the actual number of arguments. Similarly, munger_wwwww, munger_wwwwww, munger_wwwwwww, and munger_wwwwwwww are aliased to the same implementation, whose operation is shown in Figure 615. Figure 615. An example of system call argument munging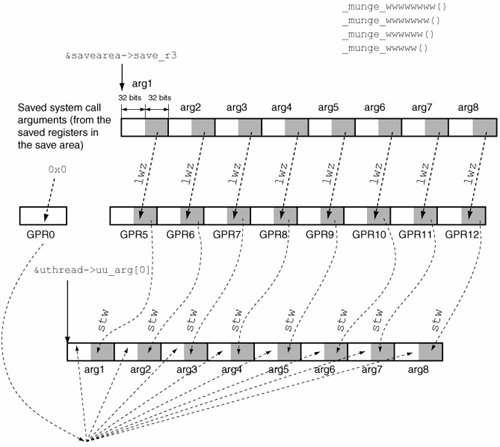 Consider the example of the read() system call. It takes three arguments: a file descriptor, a pointer to a buffer, and the number of bytes to read. ssize_t read(int d, void *buf, size_t nbytes);The 32-bit and 64-bit mungers for the read() system call are munge_www() and munge_ddd(), respectively. 6.7.1.3. Kernel Processing of BSD System CallsFigure 616 shows pseudocode depicting the working of unix_syscall(), which, as we saw earlier, is called by shandler() to process BSD system calls. Figure 616. Details of the final dispatching of BSD system calls
unix_syscall() potentially performs several types of tracing or logging: kdebug tracing, ktrace(2) tracing, and audit logging. We will discuss kdebug and kTRace(2) later in this chapter. Arguments are passed packaged into a structure to the call-specific handler. Let us consider the example of the socketpair(2) system call, which takes four arguments: three integers and a pointer to a buffer for holding two integers. int socketpair(int domain, int type, int protocol, int *rsv); The bsd/sys/sysproto.h file, which, as noted earlier, is generated by bsd/kern/makesyscalls.sh, contains argument structure declarations for all BSD system calls. Note also the use of left and right padding in the declaration of the socketpair_args structure. // bsd/sys/sysproto.h #ifdef __ppc__ #define PAD_(t) (sizeof(uint64_t) <= sizeof(t) \ ? 0 : sizeof(uint64_t) - sizeof(t)) #else ... #endif #if BYTE_ORDER == LITTLE_ENDIAN ... #else #define PADL_(t) PAD_(t) #define PADR_(t) 0 #endif ... struct socketpair_args { char domain_l_[PADL_(int)]; int domain; char domain_r_[PADR_(int)]; char type_l_[PADL_(int)]; int type; char type_r_[PADR_(int)]; char protocol_l_[PADL_(int)]; int protocol; char protocol_r_[PADR_(int)]; char rsv_l_[PADL_(user_addr_t)]; user_addr_t rsv; \ char rsv_r_[PADR_(user_addr_t)]; }; ... The system call handler function for socketpair(2) retrieves its arguments as fields of the incoming socket_args structure. // bsd/kern/uipc_syscalls.c // Create a pair of connected sockets int socketpair(struct proc *p, struct socketpair_args *uap, __unused register_t *retval) { struct fileproc *fp1, *fp2; struct socket *so1, *so2; int fd, error, sv[2]; ... error = socreate(uap->domain, &so1, uap->type, &uap->protocol); ... error = socreate(uap->domain, &so2, uap->type, &uap->protocol); ... error = falloc(p, &fp1, &fd); ... sv[0] = fd; error = falloc(p, &fp2, &fd); ... sv[1] = fd; ... error = copyout((caddr_t)sv, uap->rsv, 2 * sizeof(int)); ... return (error); } Note that before calling the system call handler, unix_syscall() sets the error status to zero, assuming that there will be no error. Recall that the saved SRR0 register contains the address of the instruction immediately following the system call instruction. This is where execution would resume after returning to user space from the system call. As we will shortly see, a standard user-space library stub for a BSD system call invokes the cerror() library function to set the errno variablethis should be done only if there is an error. unix_syscall() increments the saved SRR0 by one instruction, so that the call to cerror() will be skipped if there is no error. If the system call handler indeed does return an error, the SRR0 value is decremented by one instruction. After returning from the handler, unix_syscall() examines the error variable to take the appropriate action.
Finally, to return to user mode, unix_syscall() calls thread_exception_return() [osfmk/ppc/hw_exception.s], which checks for outstanding ASTs. If any ASTs are found, ast_taken() is called. After ast_taken() returns, thread_exception_return() checks for outstanding ASTs one more time (and so on). It then jumps to .L_thread_syscall_return() [osfmk/ppc/hw_exception.s], which branches to chkfac() [osfmk/ppc/hw_exception.s], which branches to exception_exit() [osfmk/ppc/lowmem_vectors.s]. Some of the context is restored during these calls. exception_exit() eventually branches to EatRupt [ofsmk/ppc/lowmem_vectors.s], which releases the save area, performs the remaining context restoration and state cleanup, and finally executes the rfid (rfi for 32-bit) instruction to return from the interrupt.
Figure 617. System call data structures in Third Edition UNIX
6.7.1.4. User Processing of BSD System CallsA typical BSD system call stub in the C library is constructed using a set of macros, some of which are shown in Figure 618. The figure also shows an assembly-language fragment for the the exit() system call. Note that the assembly code is shown with a static call to cerror() for simplicity, as the invocation is somewhat more complicated in the case of dynamic linking. Figure 618. Creating a user-space system call stub
The f in the unconditional branch instruction to 1f in Figure 618 specifies the directionforward, in this case. If you have another label named 1 before the branch instruction, you can jump to it using 1b as the operand. Figure 618 also shows the placement of the call to cerror() in the case of an error. When the sc instruction is executed, the processor places the effective address of the instruction following the sc instruction in SRR0. Therefore, the stub is set to call the cerror() function by default after the system call returns. cerror() copies the system call's return value (contained in GPR3) to the errno variable, calls cthread_set_errno_self() to set the per-thread errno value for the current thread, and sets both GPR3 and GPR4 to -1, thereby causing the calling program to receive return values of -1 whether the expected return value is one word (in GPR3) or two words (in GPR3 and GPR4). Let us now look at an example of directly invoking a system call using the sc instruction. Although doing so is useful for demonstration, a nonexperimental user program should not use the sc instruction directly. The only API-compliant and future-proof way to invoke system calls under Mac OS X is through user libraries. Almost all supported system calls have stubs in the system library (libSystem), of which the standard C library is a subset.
As we noted in Chapter 2, the primary reason system calls must not be invoked directly in user programsespecially shipping productsis that the interfaces between system shared libraries and the kernel are private to Apple and are subject to change. Moreover, user programs are allowed to link with system libraries (including libSystem) only dynamically. This allows Apple flexibility in modifying and extending its private interfaces without affecting user programs. With that caveat, let us use the sc instruction to invoke a simple BSD system callsay, getpid(). Figure 619 shows a program that uses both the library stub and our custom stub to call getpid(). We need an extra instructionsay, a no-opimmediately following the sc instruction, otherwise the program will behave incorrectly. Figure 619. Directly invoking a BSD system call
Note that since user programs on Mac OS X can only be dynamically linked with Apple-provided libraries, one would expect a user program not to have any sc instructions at allit should only have dynamically resolved symbols to system call stubs. However, dynamically linked 32-bit C and C++ programs do have a couple of embedded sc instructions that come from the language runtime startup codespecifically, the __dyld_init_check() function. ; dyld.s in the source for the C startup code /* * At this point the dynamic linker initialization was not run so print a * message on stderr and exit non-zero. Since we can't use any libraries the * raw system call interfaces must be used. * * write(stderr, error_message, sizeof(error_message)); */ li r5,78 lis r4,hi16(error_message) ori r4,r4,lo16(error_message) li r3,2 li r0,4 ; write() is system call number 4 sc nop ; return here on error /* * _exit(59); */ li r3,59 li r0,1 ; exit() is system call number 1 sc trap ; this call to _exit() should not fall through trap 6.7.2. Mach TrapsAlthough Mach traps are similar to traditional system calls in that they are entry points into the kernel, they are different in that Mach kernel services are typically not offered directly through these traps. Instead, certain Mach traps are IPC entry points through which user-space clientssuch as the system libraryaccess kernel services by exchanging IPC messages with the server that implements those services, just as if the server were in user space.
There are almost ten times as many BSD system calls as there are Mach traps. Consider an example of a simple Mach trapsay, task_self_trap(), which returns send rights to the task's kernel port. The documented mach_task_self() library function is redefined in <mach/mach_init.h> to be the value of the environment variable mach_task_self_, which is populated by the system library during the initialization of a user process. Specifically, the library stub for the fork() system call[10] sets up the child process by calling several initialization routines, including one that initializes Mach in the process. This latter step caches the return value of task_self_trap() in the mach_task_self_ variable.
// <mach/mach_init.h> extern mach_port_t mach_task_self_; #define mach_task_self() mach_task_self_ ...The program shown in Figure 620 uses several apparently different ways of retrieving the same informationthe current task's self port. Figure 620. Multiple ways of retrieving a Mach task's self port
The value returned by task_self_trap() is not a unique identifier like a Unix process ID. In fact, its value will be the same for all tasks, even on different machines, provided the machines are running identical kernels. An example of a complex Mach trap is mach_msg_overwrite_trap() [osfmk/ipc/mach_msg.c], which is used for sending and receiving IPC messages. Its implementation contains over a thousand lines of C code. mach_msg_trap() is a simplified wrapper around mach_msg_overwrite_trap(). The C library provides the mach_msg() and mach_msg_overwrite() documented functions that use these traps but also can restart message sending or receiving in the case of interruptions. User programs access kernel services by performing IPC with the kernel using these "msg" traps. The paradigm used is essentially client server, wherein the clients (programs) request information from the server (the kernel) by sending messages, and usuallybut not alwaysreceiving replies. Consider the example of Mach's virtual memory services. As we will see in Chapter 8, a user program can allocate a region of virtual memory using the Mach vm_allocate() function. Now, although vm_allocate() is implemented in the kernel, it is not exported by the kernel as a regular system call. It is available as a remote procedure in the "Kernel Server" and is callable by user clients. The vm_allocate() function that user programs call lives in the C library, representing the client end of the remote procedure call. Various other Mach services, such as those that allow the manipulation of tasks, threads, processors, and ports, are provided similarly.
Mach traps are maintained in an array of structures called mach_trap_table, which is similar to BSD's sysent table. Each element of this array is a structure of type mach_trap_t, which is declared in osfmk/kern/syscall_sw.h. Figure 621 shows the MACH_TRAP() macro. Figure 621. Mach trap table data structures and definitions
The MACH_ASSERT compile-time configuration option controls the ASSERT() and assert() macros and is used while compiling debug versions of the kernel. The MACH_TRAP() macro shown in Figure 621 is used to populate the Mach trap table in osfmk/kern/syscall_sw.cFigure 622 shows how this is done. Mach traps on Mac OS X have numbers that start from -10, decrease monotonically, and go as high in absolute value as the highest numbered Mach trap. Numbers 0 tHRough -9 are reserved for Unix system calls and are unused. Note also that the argument munger functions are the same as those used in BSD system call processing. Figure 622. Mach trap table initialization
The assembly stubs for Mach traps are defined in osfmk/mach/syscall_sw.h using the machine-dependent kernel_trap() macro defined in osfmk/mach/ppc/syscall_sw.h. Table 611 enumerates the key files used in the implementation of these traps.
The kernel_trap() macro takes three arguments for a trap: its name, its index in the trap table, and its argument count. // osfmk/mach/syscall_sw.h kernel_trap(mach_reply_port, -26, 0); kernel_trap(thread_self_trap, -27, 0); ... kernel_trap(task_for_pid, -45, 3); kernel_trap(pid_for_task, -46, 2); ...Let us look at a specific example, say, pid_for_task(), and see how its stub is instantiated. pid_for_task() attempts to find the BSD process ID for the given Mach task. It takes two arguments: the port for a task and a pointer to an integer for holding the returned process ID. Figure 623 shows the implementation of this trap. Figure 623. Setting up the pid_for_task() Mach trap
Using the information shown in Figure 623, the trap definition for pid_for_task() will have the following assembly stub: .text .align 4 .globl _pid_for_task _pid_for_task: li r0,-46 sc blr Let us test the assembly stub by changing the stub's function name from _pid_for_task to _my_pid_for_task, placing it in a file called my_pid_for_task.S, and using it in a C program. Moreover, we can call the regular pid_for_task() to verify the operation of our stub, as shown in Figure 624. Figure 624. Testing the pid_for_task() Mach trap
In general, handling of Mach traps follows a similar path in the kernel as BSD system calls. shandler() identifies Mach traps by virtue of their call numbers being negative. It looks up the trap handler in mach_trap_table and performs the call.
Mach traps in Mac OS X support up to eight parameters that are passed in GPRs 3 through 10. Nevertheless, mach_msg_overwrite_TRap() takes nine parameters, but the ninth parameter is not used in practice. In the trap's processing, a zero is passed as the ninth parameter. 6.7.3. I/O Kit TrapsTrap numbers 100 through 107 in the Mach trap table are reserved for I/O Kit traps. In Mac OS X 10.4, only one I/O Kit trap is implemented (but not used): iokit_user_client_trap() [iokit/Kernel/IOUserClient.cpp]. The I/O Kit framework (IOKit.framework) implements the user-space stub for this trap. 6.7.4. PowerPC-Only System CallsThe Mac OS X kernel maintains yet another system call table called PPCcalls, which contains a few special PowerPC-only system calls. PPCcalls is defined in osfmk/ppc/PPCcalls.h. Each of its entries is a pointer to a function that takes one argument (a pointer to a save area) and returns an integer. // osfmk/ppc/PPCcalls.h typedef int (*PPCcallEnt)(struct savearea *save); #define PPCcall(rout) rout #define dis (PPCcallEnt)0 PPCcallEnt PPCcalls[] = { PPCcall(diagCall), // 0x6000 PPCcall(vmm_get_version), // 0x6001 PPCcall(vmm_get_features), // 0x6002 ... // ... PPCcall(dis), ... }; ... Call numbers for the PowerPC system calls begin at 0x6000 and can go up to 0x6FFFthat is, there can be at most 4096 such calls. The assembly stubs for these calls are instantiated in osfmk/mach/ppc/syscall_sw.h. // osfmk/mach/ppc/syscall_sw.h #define ppc_trap(trap_name,trap_number) \ ENTRY(trap_name, TAG_NO_FRAME_USED) @\ li r0, trap_number @\ sc @\ blr ... ppc_trap(diagCall, 0x6000); ppc_trap(vmm_get_version, 0x6001); ppc_trap(vmm_get_features, 0x6002); ...Note that the ppc_trap() macro is similar to the kernel_trap() macro used for defining assembly stubs for Mach traps. shandler() passes most of these calls to ppscall() [osfmk/hw_exception.s], which looks up the appropriate handler in the PPCcalls table. Depending on their purpose, these calls can be categorized as follows:
6.7.5. Ultra-Fast TrapsCertain traps are handled entirely by the low-level exception handlers in osfmk/ppc/lowmem_vectors.s, without saving or restoring much (or any) state. Such traps also return from the system call interrupt very rapidly. These are the ultra-fast traps (UFTs). As shown in Figure 613, these calls have dedicated handlers in the scTable, from where the exception vector at 0xC00 loads them. Table 615 lists the ultra-fast traps.
A comm area (see Section 6.7.6) routine uses the Thread Info UFT for retrieving the thread-specific (self) pointer, which is also called the per-thread cookie. The pthread_self(3) library function retrieves this value. The following assembly stub, which directly uses the UFT, retrieves the same value as the pthread_self() function in a user program. ; my_pthread_self.S .text .globl _my_pthread_self _my_pthread_self: li r0,0x7FF2 sc blrNote that on certain PowerPC processorsfor example, the 970 and the 970FXthe special-purpose register SPRG3, which Mac OS X uses to hold the per-thread cookie, can be read from user space. ; my_pthread_self_970.S .text .globl _my_pthread_self_970 _my_pthread_self_970: mfspr r3,259 ; 259 is user SPRG3 blrLet us test our versions of pthread_self() by using them in a 32-bit program on both a G4 and a G5, as shown in Figure 625. Figure 625. Testing the Thread Info UFT
The Facility Status UFT can be used to determine which processor facilitiessuch as floating-point and AltiVecare being used by the current thread. The following function, which directly uses the UFT, will return with a word whose bits specify the processor facilities in use. ; my_facstat.S .text .globl _my_facstat _my_facstat: li r0,0x7FF3 sc blrThe program in Figure 626 initializes a vector variable only if you run it with one or more arguments on the command line. Therefore, it should report that AltiVec is being used only if you run it with an argument. Figure 626. Testing the Facility Status UFT
6.7.5.1. Fast TrapsA few other traps that need somewhat more processing than ultra-fast traps, or are not as beneficial to handle so urgently, are handled by shandler() in osfmk/ppc/hw_exception.s. These are called fast traps, or fastpath calls. Table 616 lists the fastpath calls. Figure 612 shows the handling of both ultra-fast and fast traps.
6.7.5.2. Blue Box CallsThe Mac OS X kernel includes support code for the Blue Box virtualizer that provides the Classic runtime environment. The support is implemented as a small layer of software called the PseudoKernel, whose functionality is exported via a set of fast/ultra-fast system calls. We came across these calls in Tables 614, 615, and 616.
The truBlueEnvironment program, which resides within the Resources subdirectory of the Classic application package (Classic Startup.app), directly uses the 0x6005 (bb_enable_bluebox), 0x6006 (bb_disable_bluebox), 0x6007 (bb_settaskenv), and 0x7FFA (interrupt notification) system calls. A specially designated threadthe Blue threadruns Mac OS while handling Blue Box interrupts, traps, and system calls. Other threads can only issue system calls. The bb_enable_bluebox() [osfmk/ppc/PseudoKernel.c] PowerPC-only system call is used to enable the support code in the kernel. It receives three arguments from the user-space caller: a task identifier, a pointer to the trap table (TWI_TableStart), and a pointer to a descriptor table (Desc_TableStart). bb_enable_bluebox() passes these arguments in a call to enable_bluebox() [osfmk/ppc/PseudoKernel.c], which aligns the passed-in descriptor address to a page, wires the page, and maps it into the kernel. The page holds a BlueThreadTrapDescriptor structure (BTTD_t), which is declared in osfmk/ppc/PseudoKernel.h. Thereafter, enable_bluebox() initializes several Blue Boxrelated fields of the thread's machine-specific state (the machine_thread structure). Figure 627 shows pseudocode depicting the operation of enable_bluebox(). Figure 627. Enabling the kernel's Blue Box support
Once the Blue Box trap and system call tables are established, the PseudoKernel can be invoked[11] while changing Blue Box interruption state atomically. Both thandler() and shandler() check for the Blue Box during trap and system call processing, respectively.
thandler() checks the specFlags field of the current activation's machine_thread structure to see if the bbThread bit is set. If the bit is set, thandler() calls checkassist() [osfmk/ppc/hw_exception.s], which checks whether all the following conditions hold true.
If all of these conditions are satisfied, checkassist() branches to atomic_switch_trap() [osfmk/ppc/atomic_switch.s], which loads the trap table (the bbTrap field of the machine_thread structure) in GPR5 and jumps to .L_CallPseudoKernel() [osfmk/ppc/atomic_switch.s]. shandler() checks whether system calls are being redirected to the Blue Box by examining the value of the bbNoMachSC bit of the specFlags field. If this bit is set, shandler() calls atomic_switch_syscall() [osfmk/ppc/atomic_switch.s], which loads the system call table (the bbSysCall field of the machine_thread structure) in GPR5 and falls through to .L_CallPseudoKernel(). In both cases, .L_CallPseudoKernel()among other thingsstores the vector contained in GPR5 in the saved SRR0 as the instruction at which execution will resume. Thereafter, it jumps to fastexit() [osfmk/ppc/hw_exception.s], which jumps to exception_exit() [osfmk/ppc/lowmem_vectors.s], thus causing a return to the caller.
A particular Blue Box trap value (bbMaxTrap) is used to simulate a return-from-interrupt from the PseudoKernel to user context. Returning Blue Box traps and system calls use this trap, which results in the invocation of .L_ExitPseudoKernel() [osfmk/ppc/atomic_switch.s]. 6.7.6. The CommpageThe kernel reserves the last eight pages of every address space for the kernel-user comm areaalso referred to as the commpage. Besides being wired in kernel memory, these pages are mapped (shared and read-only) into the address space of every process. Their contents include code and data that are frequently accessed systemwide. The following are examples of commpage contents:
There are separate comm areas for 32-bit and 64-bit address spaces, although they are conceptually similar. We will discuss only the 32-bit comm area in this section. Using the end of the address space for the comm area has an important benefit: It is possible to access both code and data in the comm area from anywhere in the address space, without involving the dynamic link editor or requiring complex address calculations. Absolute unconditional branch instructions, such as ba, bca, and bla, can branch to a location in the comm area from anywhere because they have enough bits in their target address encoding fields to allow them to reach the comm area pages using a sign-extended target address specification. Similarly, absolute loads and stores can comfortably access the comm area. Consequently, accessing the comm area is both efficient and convenient. The comm area is populated during kernel initialization in a processor-specific and platform-specific manner. commpage_populate() [osfmk/ppc/commpage/commpage.c] performs this initialization. In fact, functionality contained in the comm area can be considered as processor capabilitiesa software extension to the native instruction set. Various comm-area-related constants are defined in osfmk/ppc/cpu_capabilities.h. // osfmk/ppc/cpu_capabilities.h // Start at page -8, ie 0xFFFF8000 #define _COMM_PAGE_BASE_ADDRESS (-8*4096) // Reserved length of entire comm area #define _COMM_PAGE_AREA_LENGTH (7*4096) // Mac OS X uses two pages so far #define _COMM_PAGE_AREA_USED (2*4096) // The Objective-C runtime fixed address page to optimize message dispatch #define OBJC_PAGE_BASE_ADDRESS (-20*4096) // Data in the comm page ... // Code in the comm page (routines) ... // Used by gettimeofday() #define _COMM_PAGE_GETTIMEOFDAY \ (_COMM_PAGE_BASE_ADDRESS+0x2e0) ...
The comm area's actual maximum length is seven pages (not eight) since Mach's virtual memory subsystem does not map the last page of an address space. Each routine in the commpage is described by a commpage_descriptor structure, which is declared in osfmk/ppc/commpage/commpage.h. // osfmk/ppc/cpu_capabilities.h typedef struct commpage_descriptor { short code_offset; // offset to code from this descriptor short code_length; // length in bytes short commpage_address; // put at this address short special; // special handling bits for DCBA, SYNC, etc. long musthave; // _cpu_capability bits we must have long canthave; // _cpu_capability bits we cannot have } commpage_descriptor; Implementations of the comm area routines are in the osfmk/ppc/commpage/ directory. Let us look at the example of gettimeofday(), which is both a system call and a comm area routine. It is substantially more expensive to retrieve the current time using the system call. Besides a regular system call stub for gettimeofday(), the C library contains the following entry point for calling the comm area version of gettimeofday(). .globl __commpage_gettimeofday .text .align 2 __commpage_gettimeofday: ba __COMM_PAGE_GETTIMEOFDAY
Note that _COMM_PAGE_GETTIMEOFDAY is a leaf procedure that must be jumped to, instead of being called as a returning function. Note that comm area contents are not guaranteed to be available on all machines. Moreover, in the particular case of gettimeofday(), the time values are updated asynchronously by the kernel and read atomically from user space, leading to occasional failures in reading. The C library falls back to the system call version in the case of failure. // <darwin>/<Libc>/sys/gettimeofday.c int gettimeofday(struct timeval *tp, struct timezone *tzp) { ... #if defined(__ppc__) || defined(__ppc64__) { ... // first try commpage if (__commpage_gettimeofday(tp)) { // if it fails, try the system call if (__ppc_gettimeofday(tp,tzp)) { return (-1); } } } #else if (syscall(SYS_gettimeofday, tp, tzp) < 0) { return -1; } #endif ... } Since the comm area is readable from within every process, let us write a program to display the information contained in it. Since the comm area API is private, you must include the required headers from the kernel source tree rather than a standard header directory. The program shown in Figure 628 displays the data and routine descriptors contained in the 32-bit comm area. Figure 628. Displaying the contents of the comm area
|
EAN: 2147483647
Pages: 161