| Because this is a practical book, it contains numerous examples. Rather than fabricating different sets of tables and columns for every chapter or section in the book, we have decided to draw from a single, simple schema for most examples. The subject area that we chose to model is a parts distributor, such as an auto-parts wholesaler or medical device distributor, in which the business fills customer orders for one or more parts that are supplied by external suppliers. Figure 1-1 shows the entity-relationship model for this business. Figure 1-1. The parts distributor model 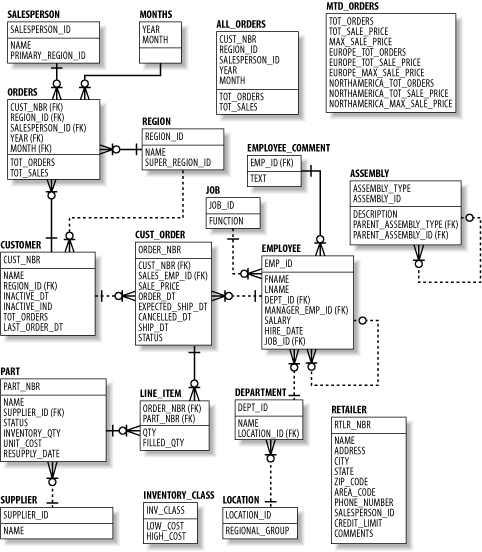
If you are unfamiliar with entity-relationship models, here is a brief description of how they work. Each box in the model represents an entity, which correlates to a database table.[1] The lines between the entities represent the relationships between tables, which correlate to foreign keys. For example, the cust_order table holds a foreign key to the employee table, which signifies the salesperson responsible for a particular order. Physically, this means that the cust_order table contains a column holding employee ID numbers, and that, for any given order, the employee ID number indicates the employee who sold that order. If you find this confusing, simply use the diagram as an illustration of the tables and columns found within our database. As you work your way through the SQL examples in this book, return occasionally to the diagram, and you should find that the relationships start making sense. [1] Depending on the purpose of the model, entities may or may not correlate to database tables. For example, a logical model depicts business entities and their relationships, whereas a physical model illustrates tables and their primary/foreign keys. The model in Figure 1-1 is a physical model.
|