Section 4.4. Building on DNS
4.4. Building on DNSAs early as the 1980s, AppleTalk had an effective service discovery mechanism. Many attempts have been made to replicate that on IP, but none have been a resounding success. Zeroconf took an unconventional approach to solving this problem. Rather than inventing an entirely new protocol from scratch, it built on an existing ubiquitous standard, DNS. A scalable service discovery mechanism needs to work both on small networks, operating peer-to-peer with no infrastructure, and on large networks, where peer-to-peer multicast would be too inefficient and, instead, service discovery data needs to be stored at some central aggregation point. As pointed out in the Internet Draft on DNS Service Discovery, DNS and its related protocols already provide the properties we need:
By building on an existing protocol, many of the deployment and adoption problems are already solved. Just about every large company already runs a DNS server, so the required hardware and software is already in place. DNS delegation means that if the network operators don't want to support service discovery functions on their current DNS server, they can choose to delegate that responsibility to some other machine. Whether running on the company's main DNS server or delegated to some other piece of hardware, the DNS technology is familiar and the software well understood. We don't have some entirely new, unfamiliar piece of software to be installed, learned, configured, and maintained. In the remainder of this chapter, you will see how DNS-SD builds on what exists in DNS. 4.4.1. Browsing for ServicesThe DNS protocol family already defines a record type called SRV for service discovery, specified in RFC 2782, "A DNS RR for specifying the location of services (DNS SRV)." (The letters "SRV" are not initials that stand for something; it's just a simple contraction of the word "service.") SRV records give us a new way of finding services for a given domain. Today, to find the web server for domain example.com, you would look up the address associated with the pseudo-hostname www.example.com. The reason we call www.example.com a pseudo-hostname is because www is not really the name of a host; it is really the name of a service. The user typing www doesn't know or care what host they're connecting to, what they care about is that the host has web pages on it. This puts us in the odd situation where some DNS names are hostnames, and others are really service names, but the distinction is blurred and vague; for any given name, it's not always clear whether it's intended to be the name of a logical service or the name of a particular piece of hardware. This is why, in 1996, a new DNS record type was defined, the SRV record. Using the new SRV mechanism, you would do a DNS query for the SRV record with the name _http._tcp.example.com. This is explicitly and unambiguously not the name of a piece of hardware. What you're asking for with this query is HTTP service (i.e., web pages) for the domain example.com. The _tcp part of the name is there for largely historical reasons. It suggests that the service usually runs by default over TCP, not UDP, though it is only a loose suggestion, and in retrospect perhaps it should have been omitted from the specification. However, the inclusion of the transport protocol label in the SRV record name does give us an accidental benefita DNS server operator can easily offload all the service-discovery workload from the main server by simply delegating the _tcp and _udp subdomains to some other machine. The result of our SRV query tells us the hostname of the machine and the port number of the process on that machine offering HTTP service for the example.com domain. Some sites might have multiple servers running for fault tolerance reasons, in which case, we would get multiple SRV records in the response. The client then picks one of the SRV records at random. It doesn't matter which one, since all the servers are offering the same pages. So far, we've described SRV records as specified in RFC 2782. As specified there, SRV records work for finding a company's main web page but are less useful for other kinds of service. If an employee wants to print, and there are 50 printers available at the company, then having the printing client simply pick one at random is not likely to be very useful. What DNS-SD adds to RFC 2782 is the ability to present a list to the user, so she can choose which printer she wants to use. There's an old joke that the answer to every problem in computer science is to add one more level of indirection. In this case, that joke offers us the answer to our problem. Instead of having 50 DNS SRV records with the name _ipp._tcp.example.com., we have 50 DNS pointer (PTR) records, each pointing to a differently named SRV record describing that printing service. By performing a PTR lookup for a name of the form ServiceType.Domain, you get a list of individual named instances of that service from which the client can choose. This is the key refinement that DNS-SD adds to vanilla SRV records.
4.4.2. Service Instance NamesWhen you perform a PTR lookup for a service type in a domain, you will receive zero or more PTR records containing service instance names . A service instance name adds a third piece to the name contained in your PTR lookup. Your lookup sent the name ServiceType.Domain and returned PTR records that contain service instance names consisting of Instance.ServiceType.Domain. For example, a query for _ipp._tcp.example.com may return the service instance names Sales._ipp._tcp.example.com and Bullpen._ipp._tcp.example.com. The Instance portion of a service instance name is not restricted to US-ASCII characters. Any Unicode characters may be used, up to a total of 63 bytes of UTF-8 encoded text. Of course, you are free to name your services how you choose; you can use names containing only US-ASCII if you wish, but you shouldn't feel compelled to keep names short to make them easy to type. Users select Zeroconf services by picking from an onscreen list, not by memorizing names and typing them in, so there's really little benefit in making names terse and easy to type. You can use long names, including capital letters, spaces, punctuation, and other characters, to make them more descriptive. You can think of the ServiceType.Domain name structure as being analogous to a directory hierarchy containing instance names. So, the example _ipp._tcp.example.com would correspond to the directory /com/example/_tcp/_ipp, as shown in Figure 4-1. Figure 4-1. The directory metaphor for service instance names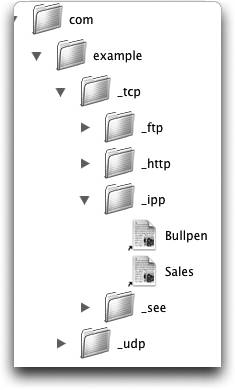 Inside of this directory, you can imagine aliases or soft links to actual instances of services of the specific type. If you wanted to select the Bullpen printer, you would double-click on its alias. In the actual case of a service instance name, when a user selects the service name in a service browser, a DNS query will be sent for the SRV record with the selected name. In response, the client receives an SRV record with the host and port information for the service. Notice that this means that a host is able to allocate its available port numbers dynamically to services that need them, instead of restricting each service to run on one predetermined, "well-known" port. In the directory analogy, you see that the most significant part of the Instance.ServiceType.Domain TRiple is the domain, with the service coming in second. The idea is that within a domain, there may or may not be services offered. For a given service type within a domain, there may or may not be instances of that type. The key in this structure is that the instances are the leaves in this tree you are navigating. In a graphical user interface, typically only the instance portion of the service instance name is displayed. In principle, the service type and domain of a discovered instance don't have to match the service type and domain of the PTR query that returned them, but in practice, they almost always do. Still, it's good programming practice to store the full name, type, and domain of each discovered service, rather than just storing the name and assuming the other two will necessarily be the expected values. 4.4.3. What You See Is What You GetOne design decision in DNS-SD was that the user-visible name of a service instance is also the primary identifier for that instance. They are one and the same. If you change the name, it is conceptually a different instance. If you replace defective hardware with new hardware but continue to advertise the service using the old name, then it is conceptually the same service being offered. There are other service discovery systems that don't work like this. In those systems, the primary identifier for a service is some hidden binary unique ID, like the MAC address of the Ethernet interface or some other globally unique ID (GUID). These identifiers are long and cryptic and practically impossible for humans to remember. Because the unique IDs are not intended to be user-friendly, a user-visible name is also associated with the service, a mere transient ephemeral attribute, changeable at any time. On paper, this flexibility might sound attractive: you can change the "name" of a service at any time without really changing its identity. Identity is defined solely by the unchangeable unique IDs, which are hidden and supposedly never seen by human users. In practice, once you use a system like that for a while, you find the flexibility is not always the benefit it seemed. If the name does not define the identity, then two things with different names might actually be the same service. Two things with apparently the same name might really be different. When problems occur, as they frequently do with networked devices, the veil is pierced. Users are forced to start being aware of the supposedly hidden unique IDs in order to diagnose what's really going on and solve the problem. With DNS-SD, in contrast, there is complete naming transparency. The true identifiers are not cryptic, secret, and hidden. What you see is what you get. 4.4.4. Flagship Service TypesNormally, the namespaces for different service types are separate. For example, you could have a file server called Home Office, a printer called Home Office, and an Ethernet-attached security camera called Home Office, and there's no confusion because they all offer clearly different services. The difficulty arises when there are several different protocols that offer conceptually similar services. For example, there are at least four different ways of printing over TCP/IP:
Suppose you have a printing client like Mac OS X's printing client that speaks all four protocols. It browses for all four DNS-SD service types. Suppose it finds, for each type, a service instance called Home Office. Should it assume that it has found four different printers that each speak one protocol or found a single printer that speaks all four and is offering four logical services on the network? The DNS-SD convention is that it should assume it has found one single printer that speaks all four protocols. To make this assumption safe, we want to ensure that, if there actually are four different printers on the network, they don't pick the same name. Normally, for entities offering the same service type, Multicast DNS's built-in name conflict detection will ensure that two services can't have the same name. However, how should DNS-SD know that you can have a file server and a network security camera with the same name, but you should not have a service of type _pdl-datastream._tcp along with another service of type _riousbprint._tcp advertising the same name on the network at the same time? The answer is flagship service types. For each group of protocols that offer conceptually similar services, one of the protocols, usually the oldest, is nominated as the flagship of the fleet of protocols. In the case of printing protocols, the flagship protocol is Unix LPR printing (_printer._tcp). Any device advertising any protocol of the fleet must also advertise the flagship protocol. If the device speaks the flagship protocol, then it advertises it as a normal service it offers, and the usual name conflict detection ensures that there aren't two instances of this protocol with the same name at the same time. If the device does not speak the flagship protocol, then it advertises a special empty SRV record, where the target hostname is the device's hostname, but the target port number is zero. This constitutes an assertion that "I claim ownership of this name, but I don't offer the actual service." This solves the problem of ensuring mutual name uniqueness among a set of related protocols. The existence of the flagship SRV record means that attempts by other devices to create other SRV records with the same service name will register a conflict, but the absence of a PTR record advertising that service means that clients browsing for that particular service type won't inadvertently discover our non-service and mistake it for a real offered service. In other words, the device has reserved the name in that particular namespace, preventing others from accidentally using it, without having to actually offer or advertise a real service of that type. Flagship protocols are used when there are two or more protocols that perform effectively the same or similar functions from the user's point of view. From our earlier example, DAAP and HTTP are not viewed as protocols in the same fleet because, even though they share a common design foundation, the functions they perform from the user's point of view are most definitely not interchangeable. The determination of what constitutes a fleet of protocols is not something that the software can do automatically. That determination is made by the human protocol designers. Typically the way things evolve is that initially, a first protocol is created (e.g., LPR). At this point there is no fleet, because there's only one. Later, an improved protocol is invented (e.g., IPP), and because it does roughly the same thing as the earlier protocol, when the new service is advertised by some new device, the device also advertises the older protocol as the flagship of the newly created fleet (of two). Devices advertising only the older protocol don't need to know thisthey just continue to advertise the older protocol as they always did. As subsequent new protocols are invented that perform roughly the same function, as long as each one is specified to advertise the same original flagship protocol, then that original flagship protocol becomes the conceptual rendezvous point of the whole family of protocols for name conflict detection purposes. Eventually, many years later, it's possible to arrive at the situation where the original protocol is obsolete and no longer used by anyone at all, but it retains its role as the non-service that every device registers, to ensure that different devices, advertising different protocols that perform roughly the same function, conceptually bump into one another if they try to advertise the same name. 4.4.5. Subtypes of Service TypesThe design of Zeroconf was intentionally kept simple, because in network design, simplicity is the best way to achieve reliability, with products from different vendors all interoperating and working correctly with one another. For this reason, DNS-SD intentionally does not include a complicated query language allowing arbitrarily elaborate queries. What it does include is a very simple filtering capability, which can be useful for some cases. Subtypes are a useful way to advertise a service when some clients will want to find all instances of that service type, but others will only be interested in finding some subset. Subtypes are best illustrated with an example. Suppose a game developer makes a network game. The commercial version of the game supports both open games that anyone can join and password-protected games. The game developer also makes a free version of the game client available, but the free version can only join open games without a password. In this case, the full version wants to find all available games on the network it might join, whereas the free version wants to find only open games without a password, since it can't join password-protected games. This selectivity can be achieved using subtypes . Suppose the DNS-SD service type for the game is _mynetgame._tcp. When starting a password-protected game, the service type _mynetgame._tcp is advertised. When starting an open game, the subtype open is used to convey that this game is open to all clients. In Apple's Bonjour APIs, subtypes are introduced by placing them after a comma following the main type, like this: _mynetgame._tcp, open. When a full client browses for games to join, it simply browses for the main type _mynetgame._tcp and finds all advertised instances on the network, both open and password-protected. When a restricted client browses for games and wants to find only open games, it browses for the subtype _mynetgame._tcp, open and finds only those games that were advertised with this subtype. When advertising a service, zero, one, or more subtypes may be added as a comma-separated list after the main type. When browsing for services, at most one subtype may be specified. If a client wishes to find more than one subtype, it needs to start a separate browsing operation for each one. In the on-the-wire packet format, subtypes are implemented by registering additional PTR records. In our example above, an open game is advertised with two PTR records, one with the name _mynetgame._tcp and another with the name open._sub._mynetgame._tcp. When the full client browses for _mynetgame._tcp, it finds all games, both open and password-protected. When a restricted client browses for open._sub._mynetgame._tcp, it finds only those instances that were advertised with this additional PTR record. Note that, in both cases, the type of the discovered service remains the same: _mynetgame._tcp. Subtypes perform a filtering operation so that only a subset of the instances is discovered, but they don't change the type being discovered. Whether to use subtypes is a design decision for each protocol. Sometimes, subtypes are appropriate. Other times, it may be more appropriate to define two entirely separate types, with clients browsing for one or other or both as appropriate, and servers advertising one or other or both as appropriate. To date, few DNS-SD protocols have specified any subtypes, and it remains to be seen how useful this mechanism will be. The most common use of subtypes so far has been for defining programmatic mappings from other communication schemes (e.g., Jini, UPnP, and web services) onto DNS-SD, to allow software written using those programming models to get the benefits of Zeroconf not offered by those other mechanisms, including pure peer-to-peer discovery that works even when no infrastructure is present and planet-wide discovery using wide-area DNS Service Discovery. |
EAN: 2147483647
Pages: 97