Lesson 1:Index Architecture
3 4
Indexes are structured to facilitate the rapid return of result sets. The two types of indexes that SQL Server supports are clustered and nonclustered indexes. Indexes are applied to one or more columns in tables or views. Indexed tables are supported on all editions of SQL Server 2000, and indexed views are supported on SQL Server Enterprise Edition and SQL Server Developer Edition. The characteristics of an index affect its use of system resources and its lookup performance. The Query Optimizer uses an index if it will increase query performance. In this lesson, you will learn about the structure, types, and characteristics of indexes.
After this lesson, you will be able to:
- Describe the purpose and structure of indexes.
- Explain the difference between clustered and nonclustered indexes.
- Describe important index characteristics.
- Use stored procedures, Query Analyzer, and Enterprise Manager to view index properties.
Estimated Lesson time: 40 minutes
Purpose and Structure
An index in SQL Server assists the database engine with locating records, just like an index in a book helps you locate information quickly. Without indexes, a query causes SQL Server to search all records in a table (table scan) in order to find matches. A database index contains one more column value from a table (called the index key) and pointers to the corresponding table records. When you perform a query using the index key, the Query Optimizer will likely use an index to locate the records that match the query.
An index is structured by the SQL Server Index Manager as a Balanced tree (or B-tree). A B-tree is analogous to an upside-down tree with the root of the tree at the top, the leaf levels at the bottom, and intermediate levels in-between. Each object in the tree structure is a group of sorted index keys called an index page. A B-tree facilitates fast and consistent query performance by carefully balancing the width and depth of the tree as the index grows. Sorting the index on the index key also improves query performance. All search requests begin at the root of a B-tree and then move through the tree to the appropriate leaf level. The number of table records and the size of the index key affect the width and depth of the tree. Index key size is called the key width. A table that has many records and a large index key width creates a deep and wide B-tree. The smaller the tree, the more quickly a search result is returned.
For optimal query performance, create indexes on columns in a table that are commonly used in queries. For example, users can query a Customers table based on last name or customer ID. Therefore, you should create two indexes for the table: a last-name index and a customer ID index. To efficiently locate records, the Query Optimizer uses an index that matches the query. The Query Optimizer will likely use the customer ID index when the following query is executed:
SELECT * FROM Customers WHERE customerid = 798
Do not create indexes for every column in a table, because too many indexes will negatively impact performance. The majority of databases are dynamic; that is, records are added, deleted, and changed regularly. When a table containing an index is modified, the index must be updated to reflect the modification. If index updates do not occur, the index will quickly become ineffective. Therefore, INSERT, UPDATE, and DELETE events trigger the Index Manager to update the table indexes. Like tables, indexes are data structures that occupy space in the database. The larger the table, the larger the index that is created to contain the table. Before creating an index, you must be sure that the increased query performance afforded by the index outweighs the additional computer resources necessary to maintain the index.
Index Types
There are two types of indexes: clustered and nonclustered. Both types of indexes are structured as B-trees. A clustered index contains table records in the leaf level of the B-tree. A nonclustered index contains a bookmark to the table records in the leaf level. If a clustered index exists on a table, a nonclustered index uses it to facilitate data lookup. In most cases, you will create a clustered index on a table before you create nonclustered indexes.
Clustered Indexes
There can be only one clustered index on a table or view, because the clustered index key physically sorts the table or view. This type of index is particularly efficient for queries, because data records—also known as data pages—are stored in the leaf level of the B-tree. The sort order and storage location of a clustered index is analogous to a dictionary in that the words in a dictionary are sorted alphabetically and definitions appear next to the words.
When you create a primary key constraint in a table that does not contain a clustered index, SQL Server will use the primary key column for the clustered index key. If a clustered index already exists in a table, a nonclustered index is created on the column defined with a primary key constraint. A column defined as the PRIMARY key is a useful index because the column values are guaranteed to be unique. Unique values create smaller B-trees than redundant values and thus make more efficient lookup structures.
NOTE
A column defined with a unique constraint creates a nonclustered index automatically.
To force the type of index to be created for a column (or columns), you can specify the CLUSTERED or NONCLUSTERED clause in the CREATE TABLE, ALTER TABLE, or CREATE INDEX statements. Suppose that you create a Persons table containing the following columns: PersonID, FirstName, LastName, and SocialSecurityNumber. The PersonID column is defined as a primary key constraint, and the SocialSecurityNumber column is defined as a unique constraint. To make the SocialSecurityNumber column a clustered index and the PersonID column a nonclustered index, create the table by using the following syntax:
CREATE TABLE dbo.Persons ( personid smallint PRIMARY KEY NONCLUSTERED, firstname varchar(30), lastname varchar(40), socialsecuritynumber char(11) UNIQUE CLUSTERED )
Indexes are not limited to constraints. You create indexes on any column or combination of columns in a table or view. Clustered indexes enforce uniqueness internally. Therefore, if you create a nonunique, clustered index on a column that contains redundant values, SQL Server creates a unique value on the redundant columns to serve as a secondary sort key. To avoid the additional work required to maintain unique values on redundant rows, favor clustered indexes for columns defined with primary key constraints.
Nonclustered Indexes
You can create up to 250 nonclustered indexes (or 249 nonclustered indexes and one clustered index) on a table or view. You must first create a unique clustered index on a view before you can create nonclustered indexes. This restriction does not apply to tables, however. A nonclustered index is analogous to an index in the back of a book. You can use a book's index to locate pages that match an index entry. The database uses a nonclustered index to locate matching records in the database.
If a clustered index does not exist on a table, the table is unsorted and is called a heap. A nonclustered index created on a heap contains pointers to table rows. Each entry in an index page contains a row ID (RID). The RID is a pointer to a table row in a heap, and it consists of a page number, a file number, and a slot number. If a clustered index exists on a table, the index pages of a nonclustered index contain clustered index keys rather than RIDs. An index pointer, whether it is a RID or an index key, is called a bookmark.
Index Characteristics
A number of characteristics (aside from the index type, which is clustered or nonclustered) can be applied to an index. An index can be defined as follows:
- Unique (so that duplicate records are not allowed)
- A composite of columns (so that an index key is made of multiple columns)
- With a fill factor (so that index pages can grow when necessary)
- With a pad index to change the space allocated to intermediate levels of the B-tree
- With a sort order to specify ascending or descending index keys
NOTE
Additional characteristics, such as file groups for index storage, can be applied to an index. Refer to CREATE INDEX in SQL Server Books Online and to Lesson 2 for more information.
Indexes are applied to one or more columns in a table or view. With some limitations, you can specify indexes on computed columns.
Unique
When an index is defined as unique, the index keys and the corresponding column values must be unique. A unique index can be applied to any column if all column values are unique. A unique index can also be applied to a group of columns (a composite of columns). The composite column unique index must maintain distinctiveness. For example, a unique index defined on a lastname column and a social security number column must not contain NULL values in both columns. Furthermore, if there are values in both columns, the combination of lastname and social security number must be unique.
SQL Server automatically creates a unique index for a column (or columns) defined with a primary key or unique constraint. Therefore, use constraints to enforce data distinctiveness, rather than directly applying the unique index characteristic. SQL Server will not allow you to create an index with the uniqueness property on a column containing duplicate values.
Composite
A composite index is any index that uses more than one column in a table for its index key. Composite indexes can improve query performance by reducing input/output (I/O) operations, because a query on a combination of columns contained in the index will be located entirely in the index. When the result of a query is
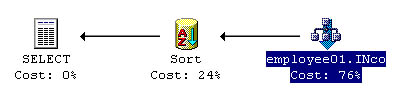
Figure 11.1 The Execution Plan tab of the Results pane showing that the Query Optimizer uses the INco covering index.
obtained from the index without having to rely on the underlying table, the query is considered covered—and the index is considered covering. A single column query, such as a query on a column with a primary key constraint, is covered by the index that is automatically created on that column. A covered query on multiple columns uses a composite index as the covering index. Suppose that you run the following query:
SELECT emp_id, lname, job_lvl FROM employee01 WHERE hire_date < (GETDATE() - 30) AND job_lvl >= 100 ORDER BY job_lvl
If a clustered index exists on the Emp_ID column and a nonclustered index named INco exists on the LName, Job_Lvl, and Hire_Date columns, then INco is a covering index. Remember that the bookmark of a nonclustered index created on a table containing a clustered index is the clustered index key. Therefore, the INco index contains all columns specified in the query (the index is covering, and the query is covered). Figure 11.1 shows that the Query Optimizer uses INco in the query execution plan.
Fill Factor and Pad Index
When a row is inserted into a table, SQL Server must locate some space for it. An insert operation occurs when the INSERT statement is used or when the UPDATE statement is used to update a clustered index key. If the table doesn't contain a clustered index, the record and the index page are placed in any available space within the heap. If the table contains a clustered index, SQL Server locates the appropriate index page in the B-tree and then inserts the record in sorted order. If the index page is full, it is split (half of the pages remain in the original index page, and half of the pages move to the new index page). If the inserted row is large, additional page splits might be necessary. Page splits are complex and are resource intensive. The most common page split occurs in the leaf level index pages. To reduce the occurrence of page splits, specify how full the index page should be when it is created. This value is called the fill factor. By default, the fill factor is zero, meaning that the index page is full when it is created on existing data. A fill factor of zero is synonymous with a fill factor of 100. You can specify a global default fill factor for the server by using the sp_configure stored procedure or for a specific index with the FILLFACTOR clause. In high-capacity transaction systems, you might also want to allocate additional space to the intermediate level index pages. The additional space assigned to the intermediate levels is called the pad index. In Lesson 2, you will learn when and how to use a fill factor.
Sort Order
When you create an index, it is sorted in ascending order. Both clustered and nonclustered indexes are sorted; the clustered index represents the sort order of the table. Consider the following SELECT statement:
SELECT emp_id, lname, job_lvl FROM employee01 WHERE hire_date < (GETDATE() - 30) AND job_lvl >= 100
Notice that there is no sort order specified. In the previous section of this lesson, you learned that the Query Optimizer uses a composite index to return a result from this statement. The composite index is nonclustered, and the first column in the index is lname. No sort order was specified when the index was created; therefore, the result is sorted in ascending order starting with the lname column. The ORDER BY clause is not specified, thus saving computing resources. But the result appears sorted first by lname. The sort order is dependent on the index used to return the result (unless you specify the ORDER BY clause or you tell the SELECT statement which index to use). If the Query Optimizer uses a clustered index to return a result, the result appears in the sort order of the clustered index, which is equivalent to the data pages in the table. The following Transact-SQL statement uses the clustered index on the Emp_ID column to return a result in ascending order:
SELECT emp_id, lname, fname FROM employee01
NOTE
Lesson 2 describes how to determine when to use an index, how to choose the appropriate index characteristics, and how to create an index.
Index Information
You can use system stored procedures, the Object Browser in Query Analyzer, and Enterprise Manager to view indexes and index properties. Knowing the indexes applied to a table or view helps you optimize your queries. You can analyze indexes to design SELECT statements that return results efficiently, or you can create new indexes to accommodate your queries. Use the sp_help or sp_helpindex system stored procedures to view the indexes applied to a table or view. The following Transact-SQL command shows all indexes created for the Employee01 table:
sp_helpindex employee01
The result that is returned from sp_helpindex includes the index name, the index type, the database file location, and the column(s) contained in the index.
Query Analyzer's Object Browser provides similar information. In the Object Browser, expand a table node and then expand the Indexes node. Next, right-click an index and choose Edit to display the Edit Existing Index dialog box. Figure 11.2 shows the properties of an index as it appears in the Edit Existing Index dialog box.
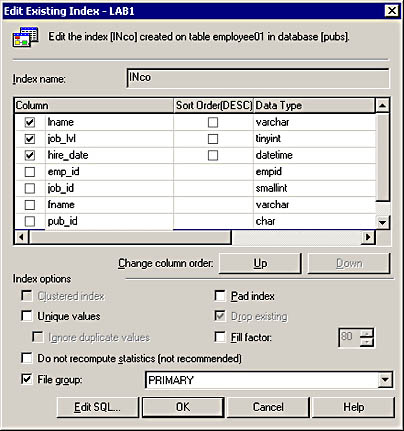
Figure 11.2 The properties of the INco nonclustered index created on the Employee01 table in the Pubs database.
You can also view the properties of an index and access the Edit Existing Index dialog box from an Execution plan. Right-click an index that appears in the Execution Plan tab and choose Manage Indexes. Doing so displays the Manage Indexes dialog box. From there, you can click the Edit button to display the Edit Existing Index dialog box. The Manage Indexes dialog box is also available in Enterprise Manager. First, locate the Tables node of a database in the console tree. In the Details pane, right-click a table, point to All Tasks, then click Manage Indexes. You can modify, create, and delete existing indexes from the Manage Indexes dialog box. You will learn about index administration tasks such as modifying, creating, and deleting indexes in Lesson 2.
To view all indexes assigned to a database, you can query the sysindexes system table in a database. For example, to query selected index information in the Pubs database, execute the following Transact-SQL code:
USE PUBS GO SELECT name, rows, rowcnt, keycnt from sysindexes WHERE name NOT LIKE '%sys%' ORDER BY keycnt
Full-Text Indexing
Full-text indexing is not part of the indexing function described in this chapter, but you should understand how it differs from the built-in SQL Server indexing system. A full-text index enables you to perform full-text queries to search for character string data in the database. A full-text index is contained in a full-text catalog. The Microsoft Search engine, not SQL Server, maintains the full-text index and catalog. For more information about this feature, search for "Full-Text Query Architecture" in SQL Server Books Online.
Exercise 1: Viewing Index Properties and Using an Index

In this exercise, you will use the sp_helpindex system stored procedure and Query Analyzer to view the properties of an index. You will then create SELECT statements to make use of various indexes. After each SELECT statement runs, you will view the execution plan to determine which index was used by the Query Optimizer. In the last practice, you will create a composite index and run a query that uses this index.
To view index properties in the Northwind database
- Open Query Analyzer and connect to your local server.
- In the Editor pane of the Query window, enter and execute the following code:
USE Northwind GO sp_helpindex customers
Five indexes appear in the Grids tab of the Results pane.
- Which index represents the sort order of the Customers table?
- Does the Customers table contain a composite index?
To run queries and examine the execution plan
- In Query Analyzer, click Query and then click Show Execution Plan.
- In the Editor pane of the Query window, enter and execute the following code:
USE Northwind GO SELECT * FROM customers
A result set appears in the Grids tab of the Results pane. Notice that the result set is sorted by CustomerID.
- Click the Execution Plan tab.
The execution plan appears in the Execution Plan tab of the Results pane. Notice that the Query Optimizer used the PK_Customers clustered index. The PK_Customers index name is truncated to PK_Cu... in the Execution Plan tab.
- In the Editor pane of the Query window, enter and execute the following code:
SELECT city, customerid from customers
A result set appears in the Grids tab of the Results pane. Notice that the result set is sorted by City.
- Click the Execution Plan tab.
The execution plan indicates that the Query Optimizer used the City nonclustered index.
- Why did the Query Optimizer choose the City index rather than the PK_Customers index in this case?
- In the Editor pane of the Query window, enter and execute the following code:
SELECT companyname, contactname, city, country, phone FROM customers
A result set appears in the Grids tab of the Results pane. Notice that the result set appears to be sorted by the CompanyName column. This sort order is actually that of the CustomerID column, which contains at least the first three characters of the CompanyName column.
- Click the Execution Plan tab.
The execution plan indicates that the Query Optimizer used the PK_Customers index. The PK_Customers index was used because no other index was covering for this query. In the next practice, you will create a covering index for this query.
Leave the Execution Plan tab active for the next practice.
To create a composite index and a query that uses the index
This practice is designed to show you how to use a composite index. Therefore, do not focus on index creation here. In Lesson 2, you will learn more about creating indexes.
- In the Execution Plan pane, right-click Customers.PK_Cu... and then click Manage Indexes.
The list of indexes created for the Customers table appears in the Manage Indexes dialog box.
- Click New.
The Create New Index dialog box appears.
- In the Index name text box, type Contact.
- In the column appearing below the Index name text box, select the CompanyName, ContactName, City, Country, and Phone check boxes.
- Select the City row and click the UP button until the City row is the first selected row.
- Click OK.
The Contact index appears in the index list of the Manage Indexes dialog box.
- Click Close.
- In the Editor pane of the Query window, enter and execute the following code:
SELECT companyname, contactname, city, country, phone FROM customers ORDER BY city
A result set appears in the Grids tab of the Results pane. Notice that the result set is sorted by City.
- Click the Execution Plan tab.
The execution plan indicates that the Query Optimizer used the Contact nonclustered index. Notice that sorting the list requires no processing because the Contact composite index is sorted first on the City column.
- In the Editor pane of the Query window, enter and execute the following code:
SELECT companyname, contactname, city, country, phone FROM customers ORDER BY country
A result set appears in the Grids tab of the Results pane. Notice that the result set is sorted by Country.
- Click the Execution Plan tab.
The execution plan indicates that the Query Optimizer used the Contact nonclustered index. Notice that there is processing required to sort the list because the Contact composite index is not sorted first by Country.
Lesson Summary
Indexes improve query performance by facilitating the location of records. An index contains index keys organized in index page groupings. The pages are further structured into a B-tree. The B-tree structure maintains high-performance lookup capabilities even if the index grows large. Before creating an index, consider the ways in which a table or view is queried. The Query Optimizer chooses an index if it will facilitate the return of matching records. Indexes should be created sparingly in dynamic databases, because the system must update each index as records are inserted into tables.
One clustered index is allowed per table or view. An index is created automatically when a primary key or unique constraint is defined for a table. Multiple nonclustered indexes are allowed on a table or view. The leaf level index pages of a nonclustered index contain either RIDs for an unsorted heap or clustered index keys for a sorted table. Indexes are defined as unique or nonunique. An index is made up of one or more columns. A multi-column index is called a composite index. A fill factor and pad index value are specified for an index to reduce the frequency of page splits. Indexes are automatically sorted in ascending order unless a sort order is specified. An index that returns a result without consulting the underlying table or heap is a covering index. A query whose result set is returned entirely from the covering index is called a covered query.
EAN: 2147483647
Pages: 97
- Chapter III Two Models of Online Patronage: Why Do Consumers Shop on the Internet?
- Chapter XI User Satisfaction with Web Portals: An Empirical Study
- Chapter XIII Shopping Agent Web Sites: A Comparative Shopping Environment
- Chapter XV Customer Trust in Online Commerce
- Chapter XVIII Web Systems Design, Litigation, and Online Consumer Behavior