| A data center has M machines and a staff of N people that maintain and service failed machines. The machines are functionally identical and share common networked file systems. A data center diagnostic system is used to: 1) automatically detect failures of the M machines, 2) maintain a queue of machines waiting to be repaired, 3) log the time a machine failed, and 4) record the times at which a repair person started and completed service on a machine. The diagnostic system uses a "heartbeat" mechanism to periodically ping the machines to determine if they are operational. As soon as a machine failure is detected, a trouble ticket is automatically generated and posted to the tracking database within the center's diagnostic system. Idle members of the repair staff continually monitor the tracking database and select the first machine in the queue of failed machines to be serviced next. Each of the M machines in the data center is in one of two states: operational or failed. A failed machine may be waiting to be repaired by one of the N repair people or it may be in the process of being repaired. As indicated in Fig. 7.1, once a failed machine is repaired, it goes back to the pool of operational machines. Figure 7.1. Failure-recovery model for the data center 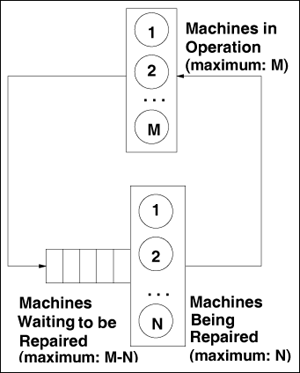 Management is interested in answering the following questions: Given the rate at which machines fail, the number of machines, the number of repair people, and the average time it takes to repair a machine, what is the probability that exactly j (j = 1, ···, M) machines are operational at any given time? Given the rate at which machines fail, the number of machines, the number of repair people, and the average repair time, what is the probability that at least j (j = 1, ···, M) machines are operational at any given time? Given the failure rate of the machines, the number of machines, and the average repair time, how many repair people are necessary to guarantee that at least j (j = 1, ···, M) machines are operational with a given probability? What is the effect of the size of the repair team on the mean time to repair (MTTR) a machine? The MTTR is the time from which a machine fails until it becomes operational again. This includes the time spent waiting to repair a machine and the time needed to diagnose and fix the problem. Also, what is the effect of the size of the repair team on the percentage of machines that can be expected to be operational at any given time? What is the effect of the average time it takes a member of the repair team to fix a machine (i.e., their skill level) on the overall MTTR (i.e., which includes the time waiting to repair)? Also, how does a repair person's skill level affect the percentage of operational machines? The average time required by a repair person to fix a machine can be reduced by either deploying better tools to the repair staff or providing better training to the repair staff.
|