13.3 Simple Two-Class Model
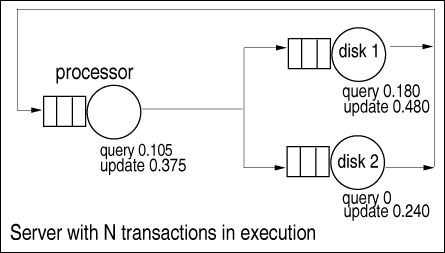
| Consider a transaction processing server with a single processor and two disks. The load on the system consists of two types of transactions: queries and updates. During the peak hours, the system is under heavy load, such that four transactions are in execution almost all the time. The analyst knows that if more than four transactions are allowed to be in execution concurrently, the system is susceptible to thrashing due to limited memory, disk, and processing capacity. After monitoring the system for a given period of time, the system administrator observes that the most common execution mix during the peak hours is a combination of three query transactions and one update transaction. The performance analyst wants to improve system performance by investigating different system scenarios. Because of the workload type (i.e., transaction oriented), it is natural to represent the system as an open model with a maximum number of four concurrent transactions. To avoid thrashing, if a transaction arrives at the system and finds four other transactions already in execution, it is required to wait in the system entry queue. Thus, it is necessary to represent the effects of blocking, which makes the model non product-form (i.e., much more difficult to solve analytically). An alternative view is that of a closed model with a constant number of four transactions in execution. This view is both a good representation for the system during peak hours and does not violate product-form assumptions, allowing the model to be solved more easily. The drawback is that the model represents only the time a transaction spends in execution. Blocking effects are not captured by this model. Chapter 15 presents techniques for modeling blocking effects. The choice between the open and closed representations for modeling a system is influenced by several factors, including the difficulty in solving the model and the difficulty in obtaining the parameters required by each type of model. In this example, an open model includes the parameterization of blocking queues to represent more realistic behavior. Solving the model is more complex and may require the use of approximation techniques. In contrast, a closed model is more approximate, but easier to solve since it requires only one additional parameter, the average number of transactions in execution. The two types of transactions differ in both function and resource usage. Update transactions impose significant write traffic to the disks, while query transactions can often be satisfied by the cache and impose less load on the disks. Consistent with observed ACID [11] transaction properties, the model assumes that update transactions demand more resources than query transactions. Thus, the analyst represents the system as a two-class model, as illustrated in Figure 13.1. Resource demands by each class (i.e., query transactions and update transactions) at each device are shown. Figure 13.1. Two-class queuing model. Suppose the transaction processing server is monitored for 30 minutes (i.e., 1800 sec) and the measurement data shown in Table 13.1 is collected. From Table 13.1, the two classes are characterized by different service demands. For example, while update transactions divide their I/O load across the two disks, query transactions do not make use of disk 2 (i.e., the service demand at disk 2 is equal to 0). Since the transactions of both classes share the same devices, it is reasonable to assume that the service time per disk visit is roughly the same across the two classes. However, updates require more disk accesses than do queries. Thus, the differences in service demands at a given device stem from the number of visits that a transaction makes to the device. In this example, the service demands show that an update transaction performs many more I/O operations than does a query transaction (i.e., updates require more visits to the disks). By viewing the measurement data in Table 13.1, update transactions visit disk 1 twice as much as disk 2. Query transactions do not visit disk 2 and visit disk 1 3/8 (i.e., 0.180/0.480) as often as update transactions.
In a single-class model, customers are assumed to be statistically identical in terms of their resource requirements. As a result, customers are undistinguishable in single-class models and the order in which transactions are serviced at a device is irrelevant. This observation, however, is not valid for multiclass models, because customers of different classes are often treated differently (i.e., writers may be given priority over readers at the disk to ensure the most up-to-date information available). Therefore, the issue of scheduling is relevant in models of multiple classes. Suppose that at a given instant of time, the four example transactions are contending for processor time (i.e., all transactions are contending for CPU service). Which transaction (query or update) should be serviced next? The goal of a scheduling policy is to assign customers to be executed by a server to optimize some system objective, such as minimizing average response time, maximizing throughput, meeting a real-time deadline, or satisfying an SLA commitment. For instance, by specifying a priority scheduling policy, a processor spends most of its time on classes of customers that are considered most critical. In the same way, a scheduling discipline can give priority to lightweight transactions over heavyweight transactions, in an attempt to minimizing the average response time of short (i.e., lightweight) requests. Modern operating systems implement various versions of well-known scheduling disciplines such as first come first served (FCFS), round robin (RR), shortest job next (SJN), shortest remaining time (SRT), earliest deadline (ED), and least laxity (LL). For example, SJN scheduling policy could be used to model disk scheduling, where the "job size" is based on the number of tracks that the disk head must move [12]. This is analogous to the shortest seek time first (SSTF) disk scheduling policy. In short, the performance of a multiclass model depends on both the service demands per class and on the scheduling policies of each device. Once an appropriate multiclass model is selected and parameterized, an appropriate solution technique is needed. That is, a solution technique is required that calculates performance measures for each workload class in the model. Making use of methods learned so far, a first approach to solving a multiclass model is to construct an equivalent single-class model. To do this, it is necessary to aggregate the performance parameters of the multiple classes into a single class. The service demand of the aggregate class at any server is the average of the individual class demands weighted by the relative class throughputs. The number of transactions of the aggregate class corresponds to the sum of the number of transactions in the system due to each individual class. If the measured throughputs of the two classes are 7,368/1800 = 4.093 tps and 736/1,800 = 0.409 tps, respectively, then the processor service demand of the aggregate class is calculated as The aggregate class demands at the two disks can be similarly calculated. Table 13.2 summarizes the parameters obtained for the aggregate class. The single-class model defined by the parameters of Table 13.2 can then be solved by using single class MVA (see Chapter 12). The calculated throughput for this single-class model equals 4.49 tps, which, in this example, is an excellent approximation to its multiclass counterpart, 4.50 tps.
Dowdy et al. [9] have shown that a single-class model of an actual multi-class system pessimistically bounds the performance of the multiclass system. These bounds help the analyst to identify the magnitude of possible errors that come from an incorrect workload characterization of a multiclass system. Using operational relationships (Ui = X0 x Di and R = n/X0), the following results for the single-class model are calculated: Ucpu = 4.49x0.130 = 58%, Udisk 1 = 4.49 x 0.207 = 93%, Udisk 2 = 4.49 x 0.02310%, and R = 4/4.49 = 0.89 sec. Once the equivalent single-class model has been constructed and solved, the analyst often wants to investigate the effects of possible future modifications to the system. Examples include:
The aggregate single-class model is not able to answer these questions, because it does not provide performance results on an individual class basis. Therefore, techniques to calculate the performance of models with multiple classes are needed. | ||||||||||||||||||||||||||||||||||
EAN: 2147483647
Pages: 166