Sequence Fields and Access Paths
| IMS uses sequence fields to identify and to provide access to a particular database record and its segments. Each segment normally has one field that is denoted as the sequence field. The sequence fields should be unique in value for each occurrence of a segment type below its parent occurrence. However, not every segment type must have a sequence field defined. The sequence field for the root segment must have a sequence field because it serves as the identification for the database record. Normally, IMS provides a fast, direct access path to the root segment of the database record based on this sequence field. This direct access is extended to lower level segments if the sequence fields of the segments along the hierarchical path are specified too. Note The sequence field is often referred to as the key field, or simply the key. In Figure 7-4 on page 72, one access path is through the PART, ORDER, and DETAIL segments. The access path must always start with the root segment. This is the access path that is used by IMS. The application program, however, can directly request a particular Detail segment of a given Order of a given Part in one single DL/I call by specifying a sequence field value for each of the three segment levels. In addition to the basic hierarchical data structure described so far, IMS provides two additional methods for defining access paths to a database segment. Logical relationships
Secondary indexes
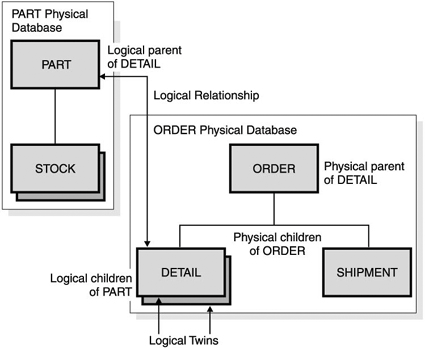
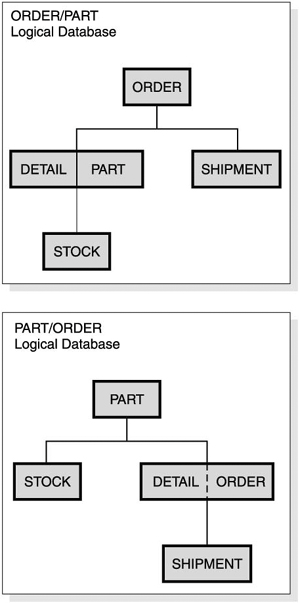
Both methods provide different access paths for an application to the physical databases. Logical relationships and secondary indexes are defined to IMS in addition to the definition for the basic hierarchical structure. The logical relationships and secondary indexes are automatically maintained by IMS, transparent to the application. Use these methods only if there are strong application or performance reasons for doing so, because both involve additional overheads. Logical RelationshipsThrough logical relationships, IMS provides a facility to interrelate segments from different hierarchies. In doing so, new hierarchical structures are defined that provide additional access capabilities to the segments involved. These segments can belong to the same database or to different databases. You can define a new database called a logical database. This logical database allows presentation of a new hierarchical structure to the application program. Although the connected physical databases could constitute a network data structure, the application data structure still consists of one or more hierarchical data structures. For example, given the entities and relationships in the two databases illustrated in Figure 7-5, you might decide that, based on the application's most common access paths, the data should be implemented as two physical hierarchical databases: the PART database and the ORDER database. However, there are some reasons why other applications might need to use a relationship between the PART segment and the DETAIL segment. So a logical relationship can be built between PART and DETAIL. Figure 7-5. Two Logically Related Physical Databases: Part and Order The basic mechanism used to build a logical relationship is to specify a dependent segment as a logical child by relating it to a second parent, the logical parent. In Figure 7-5 on page 74 the logical child segment DETAIL exists only once, yet participates in two hierarchical structures. It has a physical parent, ORDER, and logical parent, PART. The data in the logical child segment and in its dependents is called intersection data (the intersection of the two hierarchies). For example, intersection data in Figure 7-5 that might be needed by an application could be a value in the DETAIL segment for a part or order quantity. By defining two additional logical databases, two new logical data structures shown in Figure 7-6 on page 76 can be made available for application program processing, even within one single program. Figure 7-6. Two Logical Databases After Relating the Part and Order Databases The DETAIL/PART segment in Figure 7-6 is a concatenated segment. It consists of the logical child segment (DETAIL) plus the logical parent segment (PART). The DETAIL/ORDER segment in Figure 7-6 is also a concatenated segment, but it consists of the logical child segment (DETAIL) plus the physical parent segment (ORDER). Logical children with the same logical parent are called logical twins. For example, all DETAIL segments for a given PART segment are logical twins. As Figure 7-5 shows, the logical child has two access paths: one via its physical parent, the physical access path, and one via its logical parent, the logical access path. Both access paths are maintained by IMS and can be concurrently available to one program. You might want to use logical relationships for the following reasons:
Potential disadvantages in using logical relationships are:
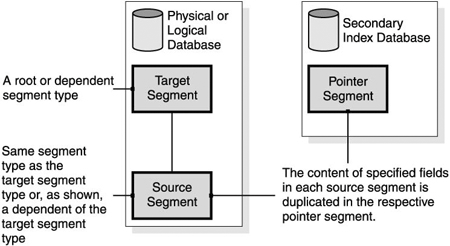
Before using logical relationships, carefully weigh the potential performance and administrative overhead against the advantages of using logical relationships. Adding logical relationships and performing the appropriate maintenance increases the overall cost of a database. Therefore, logical relationships are only worthwhile if that additional cost can be justified by other processing benefits. Related Reading: For more information about implementing logical relationships, see IMS Version 9: Administration Guide: Database Manager. Secondary Index DatabasesIMS provides additional access flexibility with secondary index databases. A secondary index represents a different access path (pointers) to any segment in the database other than the path defined by the key field in the root segment. The additional access paths can result in faster retrieval of data. A secondary index is in its own separate database and must use VSAM as its access method. Because a secondary index is in its own database, it can be processed as a separate database. There can be 32 secondary indexes for a segment type and a total of 1000 secondary indexes for a single database. To set up a secondary index, three types of segments must be defined to IMS: a pointer segment, a target segment, and a source segment. After an index is defined, IMS automatically maintains the index if the data on which the index relies changes, even if the program causing that change is not aware of the index. The segments used in a secondary index are illustrated in Figure 7-7 on page 78. Figure 7-7. Segments Used for Secondary Indexes As shown in Figure 7-7: Pointer segment
Target segment The index target segment is the segment that becomes initially accessible from the secondary index. The target segment:
The database being indexed can be a physical or logical database. Quite often, the target segment is the root segment. Source segment
The pointer segments are ordered and accessed based on the field contents of the index source segment. In general, there is one index pointer segment for each index source segment, but multiple index pointer segments can point to the same index target segment. The index source and index target segment might be the same, or the index source segment might be a dependent of the index target segment. The secondary index key (search field) is made up of one to five fields from the index source segment. The search field does not have to be a unique value, but IBM strongly recommends you make it a unique value to avoid the overhead in storing and searching duplicates. There are a number of fields that can be concatenated to the end of the secondary index search field to make it unique:
Some reasons for using secondary indexes are:
Potential disadvantages in using secondary indexes are:
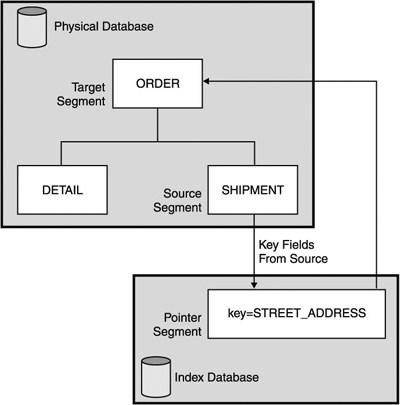
As with logical relationships, consider carefully whether the benefits of using a secondary index outweigh the performance and administrative overheads. Related Reading: For details on implementing secondary indexes, see IMS Version 9: Administration Guide: Database Manager. Sparse Indexing with Secondary IndexesAnother technique that can be used with secondary indexes is sparse indexing. Normally IMS maintains index entries for all occurrences of the secondary index source segment. However, it is possible to cause IMS to suppress index entries for some of the occurrences of the index source segment. You might want to suppress index entries if you were only interested in processing segments that had a non-null value in the field. As a general rule, only consider this technique if you expect 20% or less of the index source segments to be created. The suppression can be done either by specifying that all bytes in the field should be a specific character (NULLVAL parameter) or by selection with the Secondary Index Maintenance exit routine. Example of a Secondary IndexSuppose an application needs to retrieve the street address field from the SHIPMENT segment in the ORDER physical database, so that a delivery route can be established. As shown in Figure 7-8 on page 81, an index database can be created with a pointer segment defined for that field (STREET_ADDRESS). Figure 7-8. A Physical Database and Its Secondary Index Database The pointer segment contains a pointer to the ORDER root segment (of the ORDER physical database) and also contains key field information (STREET_ADDRESS) from the SHIPMENT (source) segment. In Figure 7-8, the secondary index key (the search field) is the STREET_ADDRESS field of the SHIPMENT source segment. As an example of suppressing index entries (in Figure 7-8), suppose that the ORDER segment had a field set in it to indicate the order could not be fulfilled immediately, but needed to be back ordered. You could define a secondary index including this field, but suppress all entries that did not have this field set, giving rapid access to all back orders. |
EAN: 2147483647
Pages: 226
- Chapter I e-Search: A Conceptual Framework of Online Consumer Behavior
- Chapter II Information Search on the Internet: A Causal Model
- Chapter X Converting Browsers to Buyers: Key Considerations in Designing Business-to-Consumer Web Sites
- Chapter XIV Product Catalog and Shopping Cart Effective Design
- Chapter XV Customer Trust in Online Commerce