Loading Databases
| When you design an application program to load databases, there are planning considerations for the application program and the PSB used. The following sections describe these considerations and describe the process of loading databases. Overview of Loading DatabasesWhen the load program inserts segments into the database, it builds the segments and inserts them in the database in hierarchical order. Often the data to be stored in the database already exists in one or more files, but merge and sort operations might be required to present the data in the correct sequence. The process of loading a database is different than that of updating a database that is already populated with segments. Before the database can be used by most application programs, it must be initialized. A database can be initialized in several ways:
After the database is initialized it remains so until it has been deleted and redefined. Therefore, it is possible to have an empty initialized database. A database that is not empty cannot be used by a PSB with a PROCOPT=L specified, nor can it be recovered or loaded with a reload utility. If the database does not have secondary indexes or logical relationships, then the load process is very straightforward. Any program with PROCOPT=L specified can load the database. After that program completes and closes the database, the database can be used by any program for read or update purposes. The loading of databases with logical relationships and secondary indexes is discussed in "Loading a Database That Has Logical Relationships" on page 271 and "Loading a Database That Has Secondary Indexes" on page 271. Loading an HDAM DatabaseWhen you initially load an HDAM database, you should specify PROCOPT=L in the PCB. DL/I does not need to insert the database records in root key order, but you must still insert the segments in their hierarchical order. For performance reasons, it is advantageous to sort the database records into sequence. The physical sequence should be the ascending sequence of the block and root anchor point values as generated by the randomizing module. You can achieve this sequence by using the Physical Sequence Sort for Reload tool, which is part of the IBM IMS High Performance Load for z/OS, V2 tool. This tool provides a sort exit routine that gives each root key to the randomizing module for address conversion and then directs the z/OS SORT utility to sort the database records based on the value that was generated from the address plus the root key. Related Reading: For information about the IMS tools available from IBM, see Chapter 26, "IBM IMS Tools," on page 443. Status Codes for Loading DatabasesTable 15-5 shows the possible status codes returned when you load databases after issuing an insert call.
Status Codes for Error RoutinesErrors for status codes fall into two categories: those caused by application program errors, and those caused by system errors. Sometimes, however, a clear split cannot be made immediately. Table 15-5 contains all the status codes you should expect using the examples in this book. See the DL/I status codes in IMS Version 9: Messages and Codes, Volume 1 for a complete listing of all status codes. Loading a HIDAM DatabaseWhen initially loading a HIDAM database, you must specify PROCOPT=LS (load segments in ascending sequence) in the PCB. Also, database records must be inserted in ascending root sequence and segments must be inserted in their hierarchical sequence. Loading a Database That Has Logical RelationshipsIMS provides a set of utility programs to establish the logical relationships during an initial load of databases with logical relationships. You must use the utilities because the sequence in which the logical parent is loaded is normally not the same as the sequence in which the logical child is loaded. To sort this out, IMS automatically creates a work file (whenever you load a database) that contains the necessary information to update the pointers in the prefixes of the logically related segments. Logical relationship utilities do not apply to HALDBs. You cannot use a logical DBD when initially loading a database. Figure 15-16 on page 272 illustrates the process of loading a database with logical relationships. The steps are as follows: Figure 15-16. Loading a HIDAM Database That Has Logical Relationships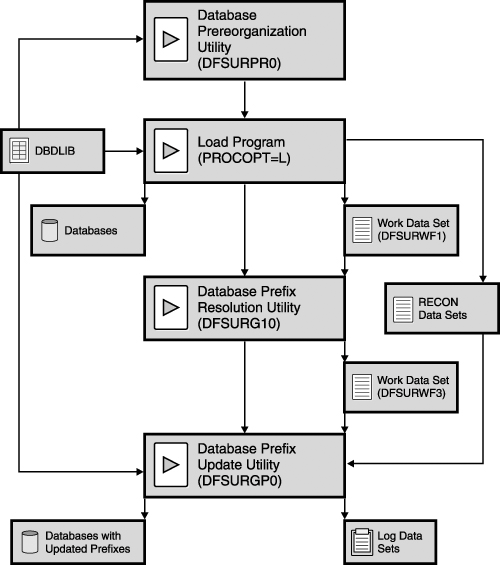
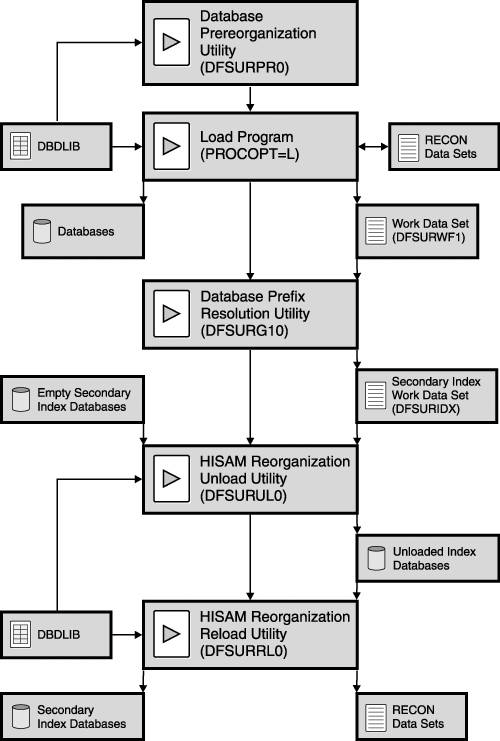
If any of the databases involved in the logical relationship also have secondary indexes, then the process for loading a database with secondary indexes must be used as well. See Figure 15-18 on page 274 for an illustration of the complete process. Loading a Database That Has Secondary IndexesTo load a database that has secondary indexes, the primary database must be uninitialized, as shown in Figure 15-17 on page 273. IMS extracts the required information into the work file to build the secondary index databases. Figure 15-17. Loading a Database That Has Secondary Indexes Figure 15-18 on page 274 illustrates the process of loading a database that has both logical relationships and secondary indexes. Figure 15-18. Loading a Database That Has Logical Relationships and Secondary Indexes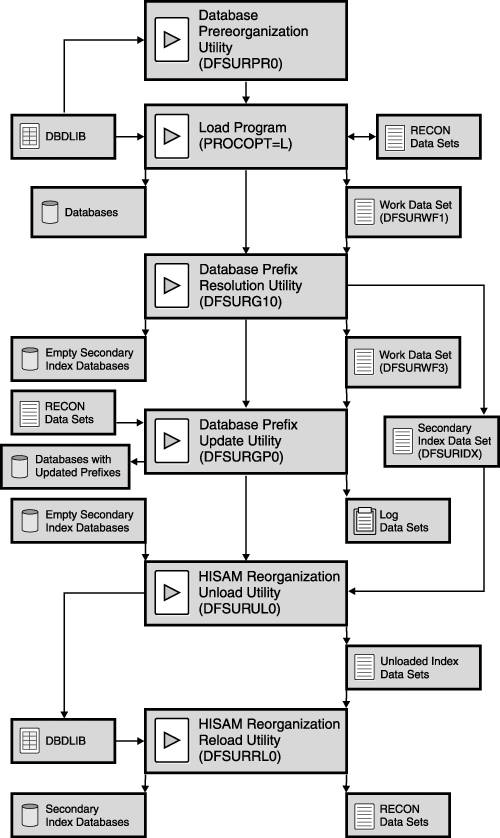 |
EAN: 2147483647
Pages: 226