9.2. NFS Structure and Operation NFS operates as a typical client-server application. The server receives remote-procedure-call (RPC) requests from its various clients. An RPC operates much like a local procedure call: The client makes a procedure call and then waits for the result while the procedure executes. For a remote procedure call, the parameters must be marshalled together into a message. Marshalling includes replacing pointers by the data to which they point and converting binary data to the canonical network byte order. The message is then sent to the server, where it is unmarshalled (separated out into its original pieces) and processed as a local filesystem operation. The result must be similarly marshalled and sent back to the client. The client splits up the result and returns that result to the calling process as though the result were being returned from a local procedure call [Birrell & Nelson, 1984]. The NFS protocol uses Sun's RPC and external data-representation (XDR) protocols [Reid, 1987]. Although the kernel implementation is done by hand to get maximum performance, the user-level daemons described later in this section use Sun's public-domain RPC and XDR libraries. The NFS protocol can run over any available stream- or datagram-oriented protocol. Common choices are the TCP stream protocol and the UDP datagram protocol. Each NFS RPC message may need to be broken into multiple packets to be sent across the network. A big performance problem for NFS running under UDP on an Ethernet is that the message may be broken into up to six packets; if any of these packets are lost, the entire message is lost and must be resent. When running under TCP on an Ethernet, the message may also be broken into up to six packets; however, individual lost packets, rather than the entire message, can be retransmitted. Section 9.3 discusses performance issues in greater detail. The set of RPC requests that a client can send to a server is shown in Table 9.1 (on page 390). After the server handles each request, it responds with the appropriate data or with an error code explaining why the request could not be done. As noted in the table, many operations are idempotent. An idempotent operation is one that can be repeated several times without the final result being changed or an error being caused. For example, writing the same data to the same offset in a file is idempotent because it will yield the same result whether it is done once or many times. However, trying to remove the same file more than once is nonidempotent because the file will no longer exist after the first try. Idempotency is an issue when the server is slow or when an RPC acknowledgment is lost and the client retransmits the RPC request. The retransmitted RPC will cause the server to try to do the same operation twice. For a nonidempotent request, such as a request to remove a file, the retransmitted RPC, if undetected by the server recent-request cache [Juszczak, 1989], will cause a "no such file" error to be returned, because the file will have been removed already by the first RPC. The user may be confused by the error because they will have successfully found and removed the file. Table 9.1. NFS, Version 3, RPC requests.RPC request | Action | Idempotent |
|---|
GETATTR | get file attributes | yes | SETATTR | set file attributes | yes | LOOKUP | look up file name | yes | ACCESS[ ] ] | check access permission | yes | READLINK | read from symbolic link | yes | READ | read from file | yes | WRITE | write to file | yes | COMMIT[] | commit cached data on a server to stable storage | yes | CREATE | create file | no | REMOVE | remove file | no | RENAME | rename file | no | LINK | create link to file | no | SYMLINK | create symbolic link | no | MKNOD[] | create a special device | no | MKDIR | create directory | no | RMDIR | remove directory | no | READDIR | read from directory | yes | READDIRPLUS[] | extended read from directory | yes | FSSTAT | get dynamic filesystem attributes | yes | FSINFO[] | get static filesystem attributes | yes | PATHCONF[] | retrieve POSIX information | yes |
[ ] RPC requests added in version 3 ] RPC requests added in version 3
Each file on the server can be identified by a unique file handle. A file handle is the token by which clients refer to files on a server. Handles are globally unique and are passed in operations, such as read and write, that reference a file. A file handle is created by the server when a pathname-translation request (lookup) is sent from a client to the server. The server must find the requested file or directory and ensure that the requesting user has access permission. If permission is granted, the server returns a file handle for the requested file to the client. The file handle identifies the file in future access requests by the client. Servers are free to build file handles from whatever information they find convenient. In the FreeBSD NFS implementation, the file handle is built from a filesystem identifier, an inode number, and a generation number. The server creates a unique filesystem identifier for each of its locally mounted filesystems. A generation number is assigned to an inode each time that the latter is allocated to represent a new file. The generation number is selected by using the kernel's random-number generator. The kernel ensures that the same value is never used for two consecutive allocations of the inode. The purpose of the file handle is to provide the server with enough information to find the file in future requests. The filesystem identifier and inode provide a unique identifier for the inode to be accessed. The generation number verifies that the inode still references the same file that it referenced when the file was first accessed. The generation number detects when a file has been deleted, and a new file is later created using the same inode. Although the new file has the same filesystem identifier and inode number, it is a completely different file from the one that the previous file handle referenced. Since the generation number is included in the file handle, the generation number in a file handle for a previous use of the inode will not match the new generation number in the same inode. When an old-generation file handle is presented to the server by a client, the server refuses to accept it and instead returns the "stale file handle" error message. The use of the generation number ensures that the file handle is time stable. Distributed systems define a time-stable identifier as one that refers uniquely to some entity both while that entity exists and for a long time after it is deleted. A time-stable identifier allows a system to remember an identity across transient failures and allows the system to detect and report errors for attempts to access deleted entities. The NFS Protocol The NFS protocol is stateless. Being stateless means that the server does not need to maintain any information about which clients it is serving or about the files that they currently have open. Every RPC request that is received by the server is completely self-contained. The server does not need any additional information beyond that contained in the RPC to fulfill the request. For example, a read request will include the credential of the user doing the request, the file handle on which the read is to be done, the offset in the file to begin the read, and the number of bytes to be read. This information allows the server to open the file, verifying that the user has permission to read it; seek to the appropriate point; read the desired contents; and close the file. In practice, the server caches recently accessed file data. However, if there is enough activity to push the file out of the cache, the file handle provides the server with enough information to reopen the file. In addition to reducing the work needed to service incoming requests, the server cache also detects retries of previously serviced requests. Occasionally, a UDP client will send a request that is processed by the server, but the acknowledgment returned by the server to the client is lost. Receiving no answer, the client will timeout and resend the request. The server will use its cache to recognize that the retransmitted request has already been serviced. Thus, the server will not repeat the operation but will just resend the acknowledgment. To detect such retransmissions properly, the server cache needs to be large enough to keep track of at least the most recent few seconds of NFS requests. The benefit of the stateless protocol is that there is no need to do state recovery after a client or server has crashed and rebooted or after the network has been partitioned and reconnected. Because each RPC is self-contained, the server can simply begin servicing requests as soon as it begins running; it does not need to know which files its clients have open. Indeed, it does not even need to know which clients are currently using it as a server. There are drawbacks to the stateless protocol. First, the semantics of the local filesystem imply state. When files are unlinked, they continue to be accessible until the last reference to them is closed. Because NFS knows neither which files are open on clients nor when those files are closed, it cannot properly know when to free file space. As a result, it always frees the space at the time of the unlink of the last name to the file. Clients that want to preserve the freeing-on-last-close semantics convert unlinks of open files to renames to obscure names on the server. The names are in the form. .nfsAxxxx4.4, where the xxxx is replaced with the hexadecimal value of the process identifier, and the A is successively incremented until an unused name is found. When the last close is done on the client, the client sends an unlink of the obscure filename to the server. This heuristic works for file access on only a single client; if one client has the file open and another client removes the file, the file will still disappear from the first client at the time of the remove. Other stateful semantics include the advisory locking described in Section 7.5. The locking semantics cannot be handled by the NFS protocol. On most systems, they are handled by a separate lock manager; the FreeBSD version of NFS implements them using the user-level rpc.lockd daemon. The second drawback of the stateless protocol is related to performance. For version 2 of the NFS protocol, all operations that modify the filesystem must be committed to stable-storage before the RPC can be acknowledged. Most servers do not have battery-backed memory; the stable store requirement means that all written data must be on the disk before they can reply to the RPC. For a growing file, an update may require up to three synchronous disk writes: one for the inode to update its size, one for the indirect block to add a new data pointer, and one for the new data themselves. Each synchronous write takes several milliseconds; this delay severely restricts the write throughput for any given client file. Version 3 of the NFS protocol eliminates some of the synchronous writes by adding a new asynchronous write RPC request. When such a request is received by the server, it is permitted to acknowledge the RPC without writing the new data to stable storage. Typically, a client will do a series of asynchronous write requests followed by a commit RPC request when it reaches the end of the file or it runs out of buffer space to store the file. The commit RPC request causes the server to write any unwritten parts of the file to stable store before acknowledging the commit RPC. The server benefits by having to write the inode and indirect blocks for the file only once per batch of asynchronous writes, instead of on every write RPC request. The client benefits from having higher throughput for file writes. The client does have the added overhead of having to save copies of all asynchronously written buffers until a commit RPC is done because the server may crash before having written one or more of the asynchronous buffers to stable store. Each time the client does an asynchronous write RPC, the server returns a verification token. When the client sends the commit RPC, the acknowledgment to that RPC also includes a verification token. The verification token is a cookie that the client can use to determine whether the server has rebooted between a call to write data and a subsequent call to commit it. The cookie is guaranteed to be the same throughout a single boot session of the server and to be different each time the server reboots where uncommitted data may be lost. If the verification token changes, the client knows that they must retransmit all asynchronous write RPCs done since the last commit RPC that were verified with the old verification-token value. The NFS protocol does not specify the granularity of the buffering that should be used when files are written. Most implementations of NFS buffer files in 8-Kbyte blocks. Thus, if an application writes 10 bytes in the middle of a block, the client reads the entire block from the server, modifies the requested 10 bytes, and then writes the entire block back to the server. The FreeBSD implementation also uses 8-Kbyte buffers, but it keeps additional information that describes which bytes in the buffer are modified. If an application writes 10 bytes in the middle of a block, the client reads the entire block from the server, modifies the requested 10 bytes but then writes back only the 10 modified bytes to the server. The block read is necessary to ensure that, if the application later reads back other unmodified parts of the block, it will get valid data. Writing back only the modified data has two benefits: Fewer data are sent over the network, reducing contention for a scarce resource. Nonoverlapping modifications to a file are not lost. If two different clients simultaneously modify different parts of the same file block, both modifications will show up in the file, since only the modified parts are sent to the server. When clients send back entire blocks to the server, changes made by the first client will be overwritten by data read before the first modification was made and then will be written back by the second client.
The FreeBSD NFS Implementation The NFS implementation that appears in FreeBSD was written by Rick Macklem at the University of Guelph, using the specifications of the Version 2 protocol published by Sun Microsystems [Macklem, 1991; Sun Microsystems, 1989]. He later extended it to support the protocol extensions found in the version 3 protocol [Callaghan et al., 1995; Pawlowski et al., 1994]. Table 9.1 highlights the new functionality in the version 3 protocol. The version 3 protocol provides the following: Sixty-four-bit file offsets and sizes An access RPC that provides server permission checking on file open, rather than having the client guess whether the server will allow access An append option on the write RPC A defined way to make special device nodes and fifos Optimization of bulk directory access The ability to batch writes into several asynchronous RPCs followed by a commit RPC to ensure that the data are on stable storage Additional information about the capabilities of the underlying filesystem
In addition to the version 2 and version 3 support, Rick Macklem made several other extensions to the BSD NFS implementation; the extended version became known as the Not Quite NFS (NQNFS) protocol [Macklem, 1994a]. The NQNFS extensions add the following: Extended file attributes to support FreeBSD filesystem functionality more fully A variant of short-term leases with delayed-write client caching that give distributed cache consistency and improved performance [Gray & Cheriton, 1989]
Although the NQNFS extensions were never widely adopted in version 3 implementations, they were instrumental in proving the value of using leases in NFS. The leasing technology was adopted for use in the NFS version 4 protocol, not only for cache consistency and improved performance of the files and directories, but also as a mechanism to bound the recovery time for locks. The NFS implementation distributed in FreeBSD supports clients and servers running the NFS version 2, NFS version 3, or NQNFS protocol [Macklem, 1994b]. The NQNFS protocol is described in Section 9.3. The FreeBSD client and server implementations of NFS are kernel resident. NFS interfaces to the network with sockets using the kernel interface available through sosend() and soreceive() (see Chapter 11 for a discussion of the socket interface). There are connection-management routines for support of sockets using connection-oriented protocols; there are timeout and retransmit support for datagram sockets on the client side. The less time-critical operations, such as mounting and unmounting, as well as determination of which filesystems may be exported and to what set of clients they may be exported are managed by user-level system daemons. For the server side to function, the portmap, mountd, and nfsd daemons must be running. For full NFS functionality, the rpc.lockd and rpc.statd daemons must also be running. The portmap daemon acts as a registration service for programs that provide RPC-based services. When an RPC daemon is started, it tells the portmap daemon to what port number it is listening and what RPC services it is prepared to serve. When a client wishes to make an RPC call to a given service, it will first contact the portmap daemon on the server machine to determine the port number to which RPC messages should be sent. The interactions between the client and server daemons when a remote filesystem is mounted are shown in Figure 9.2. The mountd daemon handles two important functions: On startup and after a hangup signal, mountd reads the /etc/exports file and creates a list of hosts and networks to which each local filesystem may be exported. It passes this list into the kernel using the mount system call; the kernel links the list to the associated local filesystem mount structure so that the list is readily available for consultation when an NFS request is received. Client mount requests are directed to the mountd daemon. After verifying that the client has permission to mount the requested filesystem, mountd returns a file handle for the requested mount point. This file handle is used by the client for later traversal into the filesystem.
Figure 9.2. Daemon interaction when a remote filesystem is mounted. Step 1: The client's mount process sends a message to the well-known port of the server's portmap daemon, requesting the port address of the server's mountd daemon. Step 2: The server's portmap daemon returns the port address of its server's mountd daemon. Step 3: The client's mount process sends a request to the server's mountd daemon with the pathname of the filesystem that it wants to mount. Step 4: The server's mountd daemon requests a file handle for the desired mount point from its kernel. If the request is successful, the file handle is returned to the client's mount process. Otherwise, the error from the file-handle request is returned. If the request is successful, the client's mount process does a mount system call, passing in the file handle that it received from the server's mountd daemon. 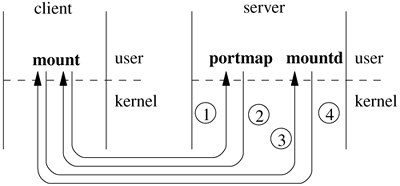
The nfsd master daemon forks off children that enter the kernel using the nfssvc system call. The children normally remain kernel resident, providing a process context for the NFS RPC daemons. Typical systems run four to six nfsd daemons. If nfsd is providing datagram service, it will create a datagram socket when it is started. If nfsd is providing stream service, connected stream sockets will be passed in by the master nfsd daemon in response to connection-oriented connection requests from clients. When a request arrives on a datagram or stream socket, there is a callback from the socket layer that invokes the nfsrv_rcv() routine. The nfsrv_rcv() call takes the message from the socket receive queue and dispatches that message to an available nfsd daemon. The nfsd daemon verifies the sender and then passes the request to the appropriate local filesystem for processing. When the result returns from the filesystem, it is returned to the requesting client. The nfsd daemon is then ready to loop back and to service another request. The maximum degree of concurrency on the server is determined by the number of nfsd daemons that are started. For connection-oriented transport protocols, such as TCP, there is one connection for each client-to-server mount point. For datagram-oriented protocols, such as UDP, the server creates a fixed number of incoming RPC sockets when it starts its nfsd daemons; clients create one socket for each imported mount point. The socket for a mount point is created by the mount command on the client, which then uses it to communicate with the mountd daemon on the server. Once the client-to-server connection is established, the daemon processes on a connection-oriented protocol may do additional verification, such as Kerberos authentication. Once the connection is created and verified, the socket is passed into the kernel. If the connection breaks while the mount point is still active, the client will attempt a reconnect with a new socket. The rpc.lockd daemon manages locking requests for remote files. Client locking requests are exported from the kernel through a fifo, /var/run/lock. The rpc.lockd daemon reads the locking request from the fifo and sends them across the network to the rpc.lockd daemon on the server that holds the file. The daemon running on the server opens the file to be locked and uses the locking primitives described in Section 8.5 to acquire the requested lock. Once the lock has been acquired, the server daemon sends a message back to the client daemon. The client daemon writes the lock status into the fifo, which is then read by the kernel and passed up to the user application. The release of the lock is handled similarly. If the rpc.lockd daemon is not run, then lock requests on NFS files will fail with an "operation not supported" error. The rpc.statd daemon cooperates with rpc.statd daemons on other hosts to provide a status monitoring service. The daemon accepts requests from programs running on the local host (typically rpc.lockd) to monitor the status of specified hosts. If a monitored host crashes and restarts, the daemon on the crashed host will notify the other daemons that it crashed when it is restarted. When notified of a crash, or when a daemon determines that a remote host has crashed because of its lack of response, it will notify the local program(s) that requested the monitoring service. If the rpc.statd daemon is not run, then locks held by clients on a host that crashed may be held indefinitely. By using the rpc.statd service, crashes will be discovered and the locks held by a crashed host will be released. The client side can operate without any daemons running, but the system administrator can improve performance by running several nfsiod daemons (these daemons provide the same service as the Sun biod daemons). As with the server, for full functionality the client must run the rpc.lockd and rpc.statd daemons. The purpose of the nfsiod daemons is to do asynchronous read-aheads and write-behinds. They are typically started when the kernel begins running multiuser. They enter the kernel using the nfssvc system call, and they remain kernel resident, providing a process context for the NFS RPC client side. In their absence, each read or write of an NFS file that cannot be serviced from the local client cache must be done in the context of the requesting process. The process sleeps while the RPC is sent to the server, the RPC is handled by the server, and a reply is sent back. No read-aheads are done, and write operations proceed at the disk-write speed of the server. When present, the nfsiod daemons provide a separate context in which to issue RPC requests to a server. When a file is written, the data are copied into the buffer cache on the client. The buffer is then passed to a waiting nfsiod that does the RPC to the server and awaits the reply. When the reply arrives, nfsiod updates the local buffer to mark that buffer as written. Meanwhile, the process that did the write can continue running. The Sun Microsystems reference implementation of the NFS protocol flushes all the blocks of a file to the server when that file is closed. If all the dirty blocks have been written to the server when a process closes a file that it has been writing, it will not have to wait for them to be flushed. The NQNFS protocol does not flush all the blocks of a file to the server when that file is closed. When reading a file, the client first hands a read-ahead request to the nfsiod that does the RPC to the server. It then looks up the buffer that it has been requested to read. If the sought-after buffer is already in the cache because of a previous read-ahead request, then it can proceed without waiting. Otherwise, it must do an RPC to the server and wait for the reply. The interactions between the client and server daemons when I/O is done are shown in Figure 9.3. Figure 9.3. Daemon interaction when I/O is done. Step 1: The client's process does a write system call. Step 2: The data to be written are copied into a kernel buffer on the client, and the write system call returns. Step 3: An nfsiod daemon awakens inside the client's kernel, picks up the dirty buffer, and sends the buffer to the server. Step 4: The incoming write request is delivered to the next available nfsd daemon running inside the kernel on the server. The server's nfsd daemon writes the data to the appropriate local disk and waits for the disk I/O to complete. Step 5: After the I/O has completed, the server's nfsd daemon sends back an acknowledgment of the I/O to the waiting nfsiod daemon on the client. On receipt of the acknowledgment, the client's nfsiod daemon marks the buffer as clean. 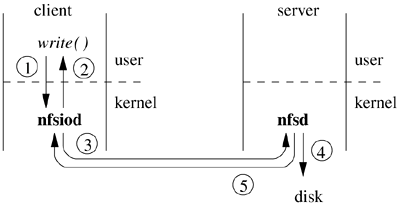
Client-Server Interactions A local filesystem is unaffected by network service disruptions. It is always available to the users on the machine unless there is a catastrophic event, such as a disk or power failure. Since the entire machine hangs or crashes, the kernel does not need to concern itself with how to handle the processes that were accessing the filesystem. By contrast, the client end of a network filesystem must have ways to handle processes that are accessing remote files when the client is still running but the server becomes unreachable or crashes. Each NFS mount point is provided with three alternatives for dealing with server unavailability: The default is a hard mount that will continue to try to contact the server indefinitely to complete the filesystem access. This type of mount is appropriate when processes on the client that access files in the filesystem do not tolerate I/O system calls that return transient errors. A hard mount is used for processes for which access to the filesystem is critical for normal system operation. It is also useful if the client has a long-running program that simply wants to wait for the server to resume operation (e.g., after the server is taken down for maintenance). The other extreme is a soft mount that retries an RPC a specified number of times, and then the corresponding system call returns with a transient error. For a connection-oriented protocol, the actual RPC request is not retransmitted; instead, NFS depends on the protocol retransmission to do the retries. If a response is not returned within the specified time, the corresponding system call returns with a transient error. The problem with this type of mount is that most applications do not expect a transient error return from I/O system calls (since they never occur on a local filesystem). Often, they will mistakenly interpret the transient error as a permanent error and will exit prematurely. An additional problem is deciding how long to set the timeout period. If it is set too low, error returns will start occurring whenever the NFS server is slow because of heavy load. Alternately, a large retry limit can result in a process hung for a long time because of a crashed server or network partitioning. Most system administrators take a middle ground by using an interruptible mount that will wait forever like a hard mount but checks to see whether a termination signal is pending for any process that is waiting for a server response. If a signal (such as an interrupt) is sent to a process waiting for an NFS server, the corresponding I/O system call returns with a transient error. Normally, the process is terminated by the signal. If the process chooses to catch the signal, then it can decide how to handle the transient failure. This mount option allows interactive programs to be aborted when a server fails, while allowing long-running processes to await the server's return.
The original NFS implementation had only the first two options. Since neither of these two options was ideal for interactive use of the filesystem, the third option was developed as a compromise solution. RPC Transport Issues The NFS version 2 protocol runs over UDP/IP transport by sending each request-reply message in a single UDP datagram. Since UDP does not guarantee datagram delivery, a timer is started, and if a timeout occurs before the corresponding RPC reply is received, the RPC request is retransmitted. At best, an extraneous RPC request retransmit increases the load on the server and can result in damaged files on the server or spurious errors being returned to the client when nonidempotent RPCs are redone. A recent-request cache normally is used on the server to minimize the negative effect of redoing a duplicate RPC request [Juszczak, 1989]. The recent-request cache keeps copies of all the nonidempotent RPC requests that the server has received over the past few minutes (usually up to 15 minutes) along with the response that it sent to that request. Each incoming request is checked against those in the cache. If a request matches one to which the server previously responded, the previously calculated result is returned instead of rerunning the request. Thus, the client gets the same result that it would have received earlier rather than an incorrect replay. The recent-request cache prevents most of the nonidempotent-related errors. However, a network partition that exceeds the timeout value for entries in the cache can still cause nonidempotent errors to be visible. The amount of time that the client waits before resending an RPC request is called the round-trip timeout (RTT). Figuring out an appropriate value for the RTT is difficult. The RTT value is for the entire RPC operation, including transmitting the RPC message to the server, queueing at the server for an nfsd, doing any required I/O operations, and sending the RPC reply message back to the client. It can be highly variable for even a moderately loaded NFS server. As a result, the RTT interval must be a conservative (large) estimate to avoid extraneous RPC request retransmits. Adjusting the RTT interval dynamically and applying a congestion window on outstanding requests has been shown to be of some help with the retransmission problem [Nowicki, 1989]. When sending an NFS default-sized 8-Kbyte read-write data request, the read-write reply-request will be an 8+-Kbyte UDP datagram. On an Ethernet with a maximum-transmission unit (MTU) of 1500 bytes, an 8+-Kbyte datagram must be broken into at least six fragments at the IP layer for transmission. For IP fragments to be reassembled successfully into the IP datagram at the receive end, all fragments must be received at the destination. If even one fragment is lost or damaged in transit, the entire RPC message must be retransmitted and the entire RPC redone. This problem can be exaggerated if the server is multiple hops away from the client through routers or slow links. It can also be nearly fatal if the network interface on the client or server cannot handle the reception of back-to-back network packets [Kent & Mogul, 1987]. An alternative to all this madness is to run NFS over TCP transport instead of over UDP. Since TCP provides reliable delivery with congestion control, it avoids the problems associated with UDP. Because the retransmissions are done at the TCP level, instead of at the RPC level, the only time that a duplicate RPC will be sent to the server is when the server crashes or there is an extended network partition that causes the TCP connection to break after an RPC has been received but not acknowledged to the client. Here, the client will resend the RPC after the server reboots, because it does not know that the RPC has been received. The use of TCP also permits the use of read and write data sizes greater than the 8-Kbyte limit for UDP transport. Using large data sizes allows TCP to use the full duplex bandwidth of the network effectively before being forced to stop and wait for RPC response from the server. NFS over TCP usually delivers comparable to significantly better performance than NFS over UDP, unless the client or server processor is CPU limited. Here the extra CPU overhead of using TCP transport becomes significant. The main problem with using TCP transport with version 2 of NFS is that it is supported between only BSD and a few other vendor's clients and servers. However, the clear superiority demonstrated by the version 2 BSD TCP implementation of NFS convinced the group at Sun Microsystems implementing NFS version 3 to make TCP the default transport. Thus, a version 3 Sun client will first try to connect using TCP; only if the server refuses will it fall back to using UDP. The version 4 protocol also is defined to use TCP. Security Issues NFS versions 2 and 3 are not secure because the protocol was not designed with security in mind. Despite several attempts to fix security problems in these versions, NFS security is still limited. In particular, the security work only addresses authentication; file data are sent around the net in clear text. Even if someone is unable to get your server to send them a sensitive file, they can just wait until a legitimate user accesses it, and then can pick it up as it goes by on the net. Much of the work that went into version 4 addressed both authentication and data security. Once version 4 moves into general use, NFS filesystems will be able to be run reasonably securely. NFS export control is at the granularity of local filesystems. Associated with each local filesystem mount point is a list of the hosts to which that filesystem may be exported. A local filesystem may be exported to a specific host, to all hosts that match a subnet mask, or to all other hosts (the world). For each host or group of hosts, the filesystem can be exported read-only or read-write. In addition, a server may specify a set of subdirectories within the filesystem that may be mounted. However, this list of mount points is enforced by only the mountd daemon. If a malicious client wishes to do so, it can access any part of a filesystem that is exported to it. The final determination of exportability is made by the list maintained in the kernel. So even if a rogue client manages to snoop the net and to steal a file handle for the mount point of a valid client, the kernel will refuse to accept the file handle unless the client presenting that handle is on the kernel's export list. When NFS is running with TCP, the check is done once when the connection is established. When NFS is running with UDP, the check must be done for every RPC request. The NFS server also permits limited remapping of user credentials. Typically, the credential for the superuser is not trusted and is remapped to the low-privilege user "nobody." The credentials of all other users can be accepted as given or also mapped to a default user (typically "nobody"). Use of the client UID and GID list unchanged on the server implies that the UID and GID space are common between the client and server (i.e., UID N on the client must refer to the same user on the server). The system administrator can support more complex UID and GID mappings by using the umapfs filesystem described in Section 6.7. The system administrator can increase security by using Kerberos credentials instead of accepting arbitrary user credentials sent without encryption by clients of unknown trustworthiness [Steiner et al., 1988]. When a new user on a client wants to begin accessing files in an NFS filesystem that is exported using Kerberos, the client must provide a Kerberos ticket to authenticate the user on the server. If successful, the system looks up the Kerberos principal in the server's password and group databases to get a set of credentials and passes in to the server nfsd a local translation of the client UID to these credentials. The nfsd daemons run entirely within the kernel except when a Kerberos ticket is received. To avoid putting all the Kerberos authentication into the kernel, the nfsd returns from the kernel temporarily to verify the ticket using the Kerberos libraries and then returns to the kernel with the results. The NFS implementation with Kerberos uses encrypted timestamps to avert replay attempts. Each RPC request includes a timestamp that is encrypted by the client and decrypted by the server using a session key that has been exchanged as part of the initial Kerberos authentication. Each timestamp can be used only once, and it must be within a few minutes of the current time recorded by the server. This implementation requires that the client and server clocks be kept within a few minutes of synchronization (this requirement is already imposed to run Kerberos). It also requires that the server keep copies of all timestamps that it has received that are within the time range that it will accept so that it can verify that a time-stamp is not being reused. Alternatively, the server can require that timestamps from each of its clients be monotonically increasing. However, this algorithm will cause RPC requests that arrive out of order to be rejected. The mechanism of using Kerberos for authentication of NFS requests is not well defined, and the FreeBSD implementation has not been tested for interoperability with other vendors. Thus, Kerberos can be used only between FreeBSD clients and servers. |