Object-Oriented Concepts
| Object-oriented programming is centered around six basic concepts:
People seem to have attached a wide range of meanings to these concepts, most of which are quite serviceable. We define some of these concepts perhaps a little more tightly than most people do because precision facilitates a better understanding of testing the concepts and eliminates some potential confusion about what needs to be tested. For example, while a distinction between operations and methods (or member functions) is not significant for most programmers, the distinction is significant to testers because the approach to testing an operation, which is part of a class specification and a way to manipulate an object, is somewhat different from testing a method, which is a piece of code that implements an operation. The distinction helps to differentiate the concerns of specification-based testing from the concerns of implementation-based testing. We will review each of the basic object-oriented programming concepts and offer observations about them from a testing perspective. While we know that object-oriented programming languages support a variety of object-oriented programming models, we use the concepts as they are formulated for languages such as C++ and Java. Some of the variations between languages will affect the types of faults that are possible and the kinds of testing that are required. We try to note such differences throughout this book. ObjectAn object is an operational entity that encapsulates both specific data values and the code that manipulates those values. For example, the data about a specific bank account and the operations needed to manipulate that data form an object. Objects are the basic computational entities in an object-oriented program, which we characterize as a community of objects that collaborate to solve some problem. As a program executes, objects are created, modified, accessed, and/or destroyed as a result of collaborations. Within the context of a good object-oriented design, an object in a program is a representation of some specific entity in the problem or in its solution. The objects within the program have relationships that reflect the relationships of their counterparts in the problem domain. Within the context of Brickles, many objects can be identified, including a paddle, pucks, a brick pile containing bricks, the play field, the play field boundaries (walls, ceiling, and floor), and even a player. A puck object will encapsulate a variety of attributes, such as its size, shape, location on a play field (if it is in play), and current velocity. It also supports operations for movement and for the puck's disappearance after it hits the floor. In the program that implements Brickles, we would expect to find an object for each of the pucks for example, at the start of a Brickles match, we see the puck in play and any that are in reserve. When in play, a puck object will collaborate with other objects the play field, paddle, and brick pile to implement Brickles physics, which are described in the game description (see page 11). Objects are the direct target of the testing process during software development. Whether an object behaves according to its specification and whether it interacts appropriately with collaborating objects in an executing program are the two major focuses of testing object-oriented software. An object can be characterized by its life cycle. The life cycle for an object begins when it is created, proceeds through a series of states, and ends when the object is destroyed.
We make the following observations about objects from a testing perspective.
In Chapter 6 we will describe a variety of techniques for testing the interactions among objects. We will address other aspects of testing objects in Chapter 5 and Chapter 7. MessageA message[1] is a request that an operation be performed by some object. In addition to the name of an operation, a message can include values actual parameters that will be used to perform that operation. A receiver can return a value to the sender.
An object-oriented program is a community of objects that collaborate to solve a problem. This collaboration is achieved by sending messages to one another. We call the object originating a message the sender and the object receiving the message the receiver. Some messages result in some form of reply such as a return value or an exception being sent from the receiver to the sender. The execution of an object-oriented program typically begins with the instantiation of some objects, and then a message being sent to one of the objects. The receiver of that message will send messages to other objects or possibly even to itself to perform computations. In some event-driven environments, the environment will repeatedly send messages and wait for replies in response to external events such as mouse clicks and key presses. We make the following observations about messages from a testing perspective.
These issues are the primary focus of interaction testing in Chapter 6. InterfaceAn interface is an aggregation of behavioral declarations. Behaviors are grouped together because they define actions related by a single concept. For example, an interface might describe a set of behaviors related to being a moving object (see Figure 2.1). Figure 2.1. A Java declaration for a Movable interface
An interface is a building block for specifications. A specification defines the total set of public behaviors for a class (we will define this next). Java contains a syntactic construct interface that provides this capability and does not allow the declaration of any state variables. You can produce the same result in C++ by declaring an abstract base class with only public, pure virtual methods. We make the following observations about interfaces from a testing perspective.
We will use the term interface to describe a set of behavior declarations whether or not you use the interface syntax. ClassA class is a set of objects that share a common conceptual basis. Many people characterize a class as a template a "cookie cutter" for creating objects. While we understand that characterization makes apparent the role of classes in writing object-oriented programs, we prefer to think of a class as a set. The class definition then is actually a definition of what members of the set look like. This is also better than definitions that define a class as a type since some object-oriented languages don't use the concept of a type. Objects form the basic elements for executing object-oriented programs, while classes are the basic elements for defining object-oriented programs. Any concept to be represented in a program must be done by first defining a class and then creating objects defined by that class. The process of creating the objects is referred to as instantiation and the result is referred to as an instance. We will use instance and object interchangeably. The conceptual basis common to all the objects in a class is expressed in terms of two parts:
Consider a C++ definition for a class PuckSupply from Brickles. Figure 2.2 shows a C++ header file and Figure 2.3 shows a source file for such a class. The use of a header file and one or more source files is a typical way to structure a C++ class definition.[2] In the context of C++, a header file contains the class specification as a set of operations declared in the public area of a class declaration. Unfortunately, as part of the implementation, the private (and protected) data attributes, must also be defined in the header file.
Figure 2.2. A C++ header file for the class PuckSupply
Figure 2.3. A C++ source file for the class PuckSupply
To create or manipulate an object from another class, a segment of code only needs access to the specification for the class of that object. In C++, this is typically accomplished by using an include directive naming the header file for the object's class: #include "PuckSupply.h" This, of course, gives access to all the information needed to compile the code, but it provides more information than is necessary to design the interactions between classes. In Chapter 4 we will discuss problems that can arise from designers having a view into possible implementations of a class and how to detect these problems during reviews.
Class SpecificationA specification for a class describes what the class represents and what an instance of the class can do. A class specification includes a specification for each of the operations that can be performed by each of its instances. An operation is an action that can be applied to an object to obtain a certain effect. Operations fall into two categories:
We make this classification because testing accessors is different from testing modifiers. Within a class specification, some operations might both provide information and change it.[3] Some modifier operations might not make changes under all circumstances. In either case, we classify these operations as modifier operations.
There are two kinds of operations that deserve special attention:
Constructors and destructors are different from accessors and modifiers in that they are invoked implicitly as a result of the birth and death of objects. Some of these objects are visible in the program and some are not. The statement
in which a, b, c, and x are all objects from the same class, invokes the constructor of that class at least twice to create objects that hold intermediate results and die by the end of the statement, as follows:
A class represents a concept, either in the problem being solved by a software application or in the solution to that problem. We expect a description of what a class represents to be a part of a class specification. Consider, for example, that the class PuckSupply declared in Figure 2.2 probably does not have much meaning without an explanation that it represents the collection of pucks that a player has at the start of a Brickles match. As the player loses pucks to the floor during play, the program will replace it with another puck from a puck supply until that supply is exhausted, at which time the match ends with a loss for the player. We also expect some meaning and constraints to be associated with each of the operations defined in a class specification for example, do the operations size() and get() for the class PuckSupply have any inherent meaning to you? Consequently, each operation should have a specification that describes what it does. A specification for PuckSupply is given in Figure 2.4. Figure 2.4. A specification for the PuckSupply class based on contracts
Well-specified operation semantics are critical to both development and testing efforts and definitely worth the time and effort needed to express them well. You can use any form of notation to specify the semantics provided it is well-understood by all who must use it. We will specify semantics at several different points:
The aggregate of the specifications of all of the operations in a class provides part of the description of the behavior of its instances. Behavior can be difficult to infer from operation specifications alone, so behavior is typically designed and represented at a higher form of abstraction using states and transitions (See State Diagrams on page 49). Behavior is characterized by defining a set of states for an instance and then describing how various operations effect transitions from state to state. The states associated with a puck supply in Brickles define whether it is empty or not empty. Being empty is determined by the size attribute of a puck supply. If the size is zero, then it is empty, otherwise it is not empty. You can remove a puck from a supply only if that supply is not empty that is, if its size is not zero. When you write a specification for an operation, you can use one of two basic approaches to define the interface between the receiver and the sender. Each approach has a set of rules about how to define the constraints and responsibilities of the sender and the receiver when an operation is to be performed. A contract approach is embedded in the specification in Figure 2.4. A defensive programming approach underlies the specification in Figure 2.5. The contract approach emphasizes preconditions, but has simpler postconditions, while the defensive programming approach is just the reverse. Figure 2.5. A specification for the class PuckSupply based on defensive programming
Under the contract approach, which is a design technique developed by Bertrand Meyer [Meye94], an interface is defined in terms of the obligations of the sender and the receiver involved in an interaction. An operation is defined in terms of the obligations of each party. Typically, these are set forth in preconditions and postconditions for an operation and a set of invariant conditions that must hold across all operations, thereby acting as postconditions required of all operations. The preconditions prescribe the obligation of the sender that is, before the sender can make a request for a receiver to perform an operation, the sender must ensure that all preconditions are met. If preconditions have been met, then the receiver is obligated to meet the requirements set forth in the postconditions as well as those in any class invariant. Under the contract approach, care must be taken in the design of a class interface to ensure that preconditions are sufficient to allow a receiver to meet postconditions (if not, you should add additional preconditions) and to ensure that a sender can determine whether all preconditions are met before sending a message. Typically, a set of accessor methods allow for checking specified conditions. Furthermore, care must be taken to ensure that postconditions address all possible outcomes of an operation, assuming preconditions are met. Under the defensive programming approach, an interface is defined primarily in terms of the receiver, and any assumptions it makes on its own state and the values of any inputs (arguments or global data values) at the time of the request. Under this approach, an operation typically returns some indication concerning the status of the result of the request success or failure for a particular reason, such as a bad input value. This indication is traditionally in the form of a return code that associates a value with each possible outcome. However, a receiver can provide to a sender an object that encapsulates the status of the request. Furthermore, exceptions are being used more frequently because many object-oriented programming languages now support them. Some operations are defined so that no status is returned in case of failure, but instead, execution is terminated when a request cannot be met. Certainly this action cannot be tolerated in most software systems. The primary goal of defensive programming is to identify "garbage in" and hence eliminate "garbage out." A member function checks for improper values coming in and then reports the status of processing the request to a sender. The approach tends to increase the complexity of software because each sender must follow a request for an operation with code to check the processing status and then, for each possible outcome, provide code to take an appropriate recovery action. The approach tends to increase both the size of code and to increase execution time because inputs are checked on every call, even though the sender may have already checked them.[4]
The contract and defensive programming approaches represent two opposite views of software specification. As the name implies, defensive programming reflects a lack of trust of a sender on the part of a receiver. By contrast, a contract reflects a mutual responsibility shared by both a sender and a receiver. A receiver processes a request based on inputs believed to meet stated preconditions. A sender assumes that conditions have been met after the request has been processed. It is not uncommon for the approaches to be mixed in specifying the operations within a single class because they each have advantages and disadvantages. Interface design based on contracts eliminates the need for a receiver to verify preconditions on each call.[5] It makes for better software engineering and better program (and programmer) efficiency. However, it introduces one important question: "In the context of an executing program, how are contracts enforced?" Clearly, the contract places obligations on both sender and receiver. Nonetheless, can a receiver truly trust every sender to meet preconditions? The consequences of "garbage in" can be disastrous. A program's execution in the presence of a sender's failure to meet a precondition would most likely result in data corruption that would in turn have serious consequences! It is critical that all interactions under contracts be tested to ensure compliance with a contract.
From a testing perspective, the approach used in an interface determines the types of testing that need to be done. The contract approach simplifies class testing, but complicates interaction testing because we must ensure that any sender meets preconditions. The defensive programming approach complicates class testing (because test cases must address all possible outcomes) and interaction testing (because we must ensure all possible outcomes are produced and that they are properly handled by a sender). Tip Review pre- and postconditions and invariants for testability during design. Are the constraints clearly stated? Does the specification include means by which to check preconditions? Class ImplementationA class implementation describes how an object represents its attributes and carries out operations. It comprises several components:
Class testing is an important aspect of the total testing process because classes define the building blocks for object-oriented programs. Since a class is an abstraction of the commonalities among its instances, the class testing process must ensure that a representative sample of members of the class are selected for testing. By viewing classes from a testing perspective, we can identify the following potential causes of failures within their design and implementation.
The design approach used, contract or defensive, gives rise to different sets of potential problems. Under a contract approach, we only need to test situations in which the preconditions are satisfied. Under a defensive programming approach, we must test every possible input to determine that the outcome is handled properly. InheritanceInheritance is a relationship between classes that allows the definition of a new class based on the definition of an existing class.[7] This dependency of one class on another allows the reuse of both the specification and the implementation of the preexisting class. An important advantage of this approach is that the preexisting class does not have to be modified or made aware in any way of the new class. The new class is referred to as a subclass or (in C++) a derived class. If a class inherits from another, the other class is referred to as its superclass or (in C++) base class. The set of classes that inherit either directly or indirectly from a given class form an inheritance hierarchy. Within that hierarchy, we can refer to the root, which is the class from which all others inherit directly or indirectly. Each class in a hierarchy, except the root, has one or more ancestors, the class(es) from which it inherits directly or indirectly. Each class in a hierarchy has zero or more descendents, which are the classes that inherit from it directly or indirectly.
Good object-oriented design requires that inheritance be used only to implement an is a (or is a kind of) relationship. The best use of inheritance is with respect to specifications and not implementation. This requirement becomes evident in the context of inclusion polymorphism (see page 34). Viewed from the testing perspective, inheritance does the following:
PolymorphismPolymorphism is the ability to treat an object as belonging to more than one type. The typing system in a programming language can be defined to support a number of different type-conformance policies. An exact match policy may be the safest policy, but a polymorphic typing system supports designs that are flexible and easy to maintain.
Inclusion PolymorphismInclusion polymorphism is the occurrence of different forms in the same class. Object-oriented programming language support for inclusion polymorphism[8] gives programmers the ability to substitute an object whose specification matches another object's specification for the latter object in a request for an operation. In other words, a sender in an object-oriented program can use an object as a parameter based on its implementation of an interface rather than its full class.
In C++, inclusion polymorphism arises from the inheritance relationship. A derived class inherits the public interface of its base class[9] and thus instances of the derived class can respond to the same messages as the base class.[10] A sender can manipulate an instance of either class with a value that is either a reference or a pointer whose target type is the base class. A member function call can be made through that value.
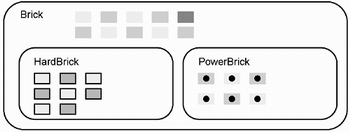
In Java, inclusion polymorphism is supported both through inheritance between classes and an implementation relationship between interfaces and classes. A sender can manipulate objects with a reference declared for either a class or an interface. If a reference is associated with a class, then the reference can be bound to an instance of that class or any of its descendents. If a reference is associated with an interface, then the reference can be bound to an instance of any class that is declared to implement that interface. Our definition of a class as a set of objects that share a common conceptual basis (see page 22) is influenced primarily by the association of inheritance and inclusion polymorphism. The class at the root of a hierarchy establishes a common conceptual basis for all objects in the set. A descendent of that root class refines the behavior established by that root class and any of its other ancestors. The objects in the descendent class are still contained in the set that is the root class. Thus, a descendent class defines a subset of each of the sets that are its ancestors. Suppose that the Brickles specification is extended to incorporate additional kinds of bricks say, some that are hard and have to be hit twice with a puck before they disappear, and some that break with a considerable force that increases the speed of any puck that hits it. The HardBrick and PowerBrick classes could each be defined as a subclass of Brick. The relationship between the sets are illustrated in Figure 2.6. Note how in a polymorphic sense, the class Brick contains 24 elements 10 "plain" bricks, 8 hard bricks, and 6 power bricks. Hard bricks and power bricks have special properties, but they also respond to the same messages as "plain" bricks, although probably in different ways. Figure 2.6. A set diagram for a Brick inheritance hierarchy
Sets representing classes can be considered from two perspectives:
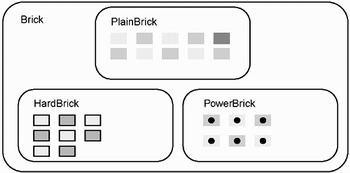
Both perspectives are useful during testing. When a class is to be tested outside the context of any application program (see Chapter 5 and Chapter 6), we will test it by selecting arbitrary instances using the first perspective. When the use of a class is to be tested in the context of an executing application program or in the context of object persistence, then we can utilize the second perspective to ensure that the size of the set is correct and that elements correspond to appropriate objects in the problem or in its solution. Inclusion polymorphism provides a powerful capability. You can perform all design and programming to interfaces, without regard to the exact class of the object that is sent a message to perform an operation. Inclusion polymorphism takes design and programming to a higher level of abstraction. In fact, it is useful to define classes for which no instances exist, but for which its subclasses do have instances. An abstract class is a class whose purpose is primarily to define an interface that is supported by all of its descendents.[11] In terms of the example extending the kinds of bricks in Brickles, an alternate formulation is to define an abstract class called Brick and define three subclasses for it: PlainBrick, HardBrick, and PowerBrick (see Figure 2.7).
Figure 2.7. A set diagram for a Brick class inheritance hierarchy
Among the abstract classes that we used in the design of Brickles are the following:
Puck and Paddle are concrete subclasses of MovableSprite, while Brick is a subclass of StationarySprite. The use of abstractions allows polymorphism to be exploited during design. For example, we can design at the level of a play field containing sprites without detailed knowledge of all the various kinds of sprites. We can design at the level of movable sprites moving in a play field and colliding with other sprites both movable and stationary. If the game specification were extended to incorporate hard bricks and power bricks, most parts of the program would not need to be changed because, after all, hard bricks and power bricks are just stationary sprites. The parts of the program that are affected should be limited to those that construct the actual instances of the classes.
A polymorphic reference hides the actual class of a referent. All referents are manipulated through their common interface. C++ and Java provide support for determining the actual class of a referent at runtime. Good object-oriented design requires that such runtime type inspections should be held to a minimum, primarily because they create a maintenance point since the extension of a class hierarchy introduces more types to be inspected. However, situations arise in which such inspections can be justified. The following are the functions of inclusion polymorphism viewed from a testing perspective:
This dynamic nature of object-oriented languages places more importance on testing a representative sample of runtime configurations. Static analyses can provide the potential interactions that might occur, but only the runtime configuration can illustrate what actually happens. In Chapter 6 we consider a statistical technique that assists in determining which configurations will expose the most faults for the least cost of resources. Parametric PolymorphismParametric polymorphism is the capability to define a type in terms of one or more parameters. Templates in C++ provide a compile-time ability to instantiate a "new" class. It is new in the sense that an actual parameter is provided for the formal parameter in the definition. Instances of the new class can then also be created. This capability has been used extensively in the C++ Standard Template Library. The interface of a simple list class template is shown in Figure 2.8. Figure 2.8. A C++ List class template
From a testing perspective, parametric polymorphism supports a different type of relationship from inheritance. If the template works for one instantiation, there is no guarantee it will work for another because the template code might assume the correct implementations of operations such as making (deep) copies and destructors. This should be checked during inspection. It is possible to write templated drivers for testing many parts of templates.
|






EAN: 2147483647
Pages: 126