Section 11.3. The Vmem Allocator
11.3. The Vmem AllocatorThe kmem allocator relies on two lower-level system services to create slabs: a virtual address allocator to provide kernel virtual addresses, and VM routines to back those addresses with physical pages and establish virtual-to-physical translations. The scalability of large systems was limited by the old virtual address allocator (the resource map allocator). It tended to fragment the address space badly over time, its latency was linear in the number of fragments, and the whole thing was single-threaded. Virtual address allocation is, however, just one example of the more general problem of resource allocation. For our purposes, a resource is anything that can be described by a set of integers. For example: virtual addresses are subsets of the 64-bit integers; process IDs are subsets of the integers [0, 30000]; and minor device numbers are subsets of the 32-bit integers. In this section we describe the new general-purpose resource allocator, vmem, which provides guaranteed constant-time performance with low fragmentation. Vmem appears to be the first resource allocator that can do this. We begin by providing background on the current state of the art. We then lay out the objectives of vmem, describe the vmem interfaces, explain the implementation in detail, and discuss vmem's performance (fragmentation, latency, and scalability) under both benchmarks and real-world conditions. 11.3.1. BackgroundAlmost all versions of UNIX have a resource map allocator called rmalloc() [45]. A resource map can be any set of integers, though it's most often an address range like [0xe0000000, 0xf0000000). The interface is simple: rmalloc(map, size) allocates a segment of the specified size from map, and rmfree(map, size, addr) gives it back. The old allocator suffered from serious flaws in both design and implementation:
11.3.2. Vmem Objectives
We begin by discussing the vmem interface considerations, then drill down to the implementation details. 11.3.3. Interface DescriptionThe vmem interfaces do three basic things: create and destroy arenas to describe resources, allocate and free resources, and allow arenas to dynamically import new resources. This section describes the key concepts and the rationale behind them. The complete vmem interface specification is shown on the following page. 11.3.3.1. Creating ArenasThe first thing we need is the ability to define a resource collection, or arena. An arena is simply a set of integers. Vmem arenas most often represent virtual memory addresses (hence the name vmem), but in fact they can represent any integer resource, from virtual addresses to minor device numbers to process IDs. The integers in an arena can usually be described as a single contiguous range, or span, such as [100, 500), so we specify this initial span to vmem_create(). For noncontiguous resources we can use vmem_add() to piece together the arena one span at a time. vmem_t *vmem_create( char *name, /* descriptive name */ void *base, /* start of initial span */ size_t size, /* size of initial span */ size_t quantum, /* unit of currency */ void *(*afunc)(vmem_t *, size_t, int), /* import alloc function */ void (*ffunc)(vmem_t *, void *, size_t), /* import free function */ vmem_t *source, /* import source arena */ size_t qcache_max, /* maximum size to cache */ int vmflag); /* VM_SLEEP or VM_NOSLEEP */ Creates a vmem arena called name whose initial span is [base, base + size). The arena's natural unit of currency is quantum, so vmem_alloc() guarantees quantum's aligned results. The arena may import new spans by invoking afunc on source, and may return those spans by invoking ffunc on source. Small allocations are common, so the arena provides high-performance caching for each integer multiple of quantum up to qcache_max. vmflag is either VM_SLEEP or VM_NOSLEEP depending on whether the caller is willing to wait for memory to create the arena. vmem_create() returns an opaque pointer to the arena. void vmem_destroy(vmem_t *vmp); Destroys arena vmp. void *vmem_alloc(vmem_t *vmp, size_t size, int vmflag); Allocates size bytes from vmp. Returns the allocated address on success, NULL on failure. vmem_alloc() fails only if vmflag specifies VM_NOSLEEP and no resources are currently available. vmflag may also specify an allocation policy (VM_BESTFIT, VM_ INSTANTFIT, or VM_NEXTFIT) as described in 4.3.2. If no policy is specified, the default is VM_INSTANTFIT, which provides a good approximation to best-fit in guaranteed constant time. void vmem_free(vmem_t *vmp, void *addr, size_t size); Frees size bytes at addr to arena vmp. void *vmem_xalloc(vmem_t *vmp, size_t size, size_t align, size_t phase, size_t nocross, void *minaddr, void *maxaddr, int vmflag); Allocates size bytes at offset phase from an align boundary such that the resulting segment [addr, addr + size) is a subset of [minaddr, maxaddr) that does not straddle a nocross-aligned boundary. vmflag is as above. One performance caveat: if either minaddr or maxaddr is non-NULL, vmem may not be able to satisfy the allocation in constant time. If allocations within a given [minaddr, maxaddr) range are common, it is more efficient to declare that range to be its own arena and use unconstrained allocations on the new arena. void vmem_xfree(vmem_t *vmp, void *addr, size_t size); Frees size bytes at addr, where addr was a constrained allocation. vmem_xfree() must be used if the original allocation was a vmem_xalloc() because both routines bypass the quantum caches. void *vmem_add(vmem_t *vmp, void *addr, size_t size, int vmflag); Adds the span [addr, addr + size) to arena vmp. Returns addr on success, NULL on failure. vmem_add() will fail only if vmflag is VM_NOSLEEP and no resources are currently available. For example, to create an arena to represent the integers in the range [100, 500) we can say: foo = vmem_create("foo", 100, 400, ...); vmem_add(foo, 600, 200, VM_SLEEP); (Note: 100 is the start, 400 is the size.) If we want foo to represent the integers [600, 800) as well, we can add the span [600, 800) by using vmem_add(). The vmem_create() function specifies the arena's natural unit of currency, or qu, which is typically either 1 (for single integers like process IDs) or PAGESIZE (for virtual addresses). Vmem rounds all sizes to quantum multiples and guarantees quantum-aligned allocations. 11.3.3.2. Allocating and Freeing ResourcesThe primary interfaces to allocate and free resources are simple: vmem_alloc(vmp, size, vmflag) allocates a segment of size bytes from arena vmp, and vmem_free(vmp, addr, size) gives it back. We also provide a vmem_xalloc() interface that can specify common allocation constraints: alignment, phase (offset from the alignment), address range, and boundary-crossing restrictions (e.g., "don't cross a page boundary"). vmem_xalloc() is useful for things like kernel DMA code, which allocates kernel virtual addresses, using the phase and alignment constraints to ensure correct cache coloring. For example, to allocate a 20-byte segment whose address is 8 bytes away from a 64-byte boundary and which lies in the range [200, 300), we can say addr = vmem_xalloc(foo, 20, 64, 8, 0, 200, 300, VM_SLEEP); In this example, addr will be 262: It is 8 bytes away from a 64-byte boundary (262 mod 64 = 8), and the segment [262, 282) lies within [200, 300). Each vmem_[x]alloc() can specify one of three allocation policies through its vmflag argument:
We also offer an arena-wide allocation policy called quantum caching. The idea is that most allocations are for just a few quanta (e.g., one or two pages of heap or one minor device number), so we employ high-performance caching for each multiple of the quantum up to qcache_max, specified in vmem_create(). We make the caching threshold explicit so that each arena can request the amount of caching appropriate for the resource it manages. Quantum caches provide perfect-fit, very low latency, and linear scalability for the most common allocation sizes. 11.3.3.3. Importing from Another ArenaVmem allows one arena to import its resources from another. vmem_create() specifies the source arena and the functions to allocate and free from that source. The arena imports new spans as needed and gives them back when all their segments have been freed. The power of importing lies in the side effects of the import functions and is best understood by example. In Solaris, the function segkmem_alloc() invokes vmem_alloc() to get a virtual address and then backs it with physical pages. Therefore, we can create an arena of mapped pages by simply importing from an arena of virtual addresses, using segkmem_alloc() and segkmem_free(). 11.3.4. Vmem ImplementationIn this section we describe how vmem actually works. Figure 11.6 illustrates the overall structure of an arena. Figure 11.6. Structure of a Vmem Arena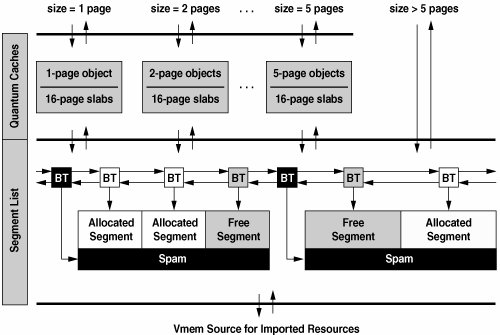 11.3.4.1. Keeping Track of Segments
Most implementations of malloc() prepend a small amount of space to each buffer to hold information for the allocator. These boundary tags, invented by Knuth in 1962 [18], solve two major problems:
Unfortunately, resource allocators can't use traditional boundary tags because the resource they're managing may not be memory (and therefore may not be able to hold information). In vmem we address this by using external boundary tags. For each segment in the arena we allocate a boundary tag to manage it, as shown in Figure 11.6. We'll see shortly that external boundary tags enable constant-time performance. 11.3.4.2. Allocating and Freeing SegmentsEach arena has a segment list that links all of its segments in address order, as shown in Figure 11.6. Every segment also belongs to either a free list or an allocation hash chain, as described below. (The arena's segment list also includes span markers to keep track of span boundaries, so we can easily tell when an imported span can be returned to its source.) We keep all free segments on power-of-two free lists; that is, free list[n] contains all free segments whose sizes are in the range [2n, 2n+1). To allocate a segment we search the appropriate free list for a segment large enough to satisfy the allocation. This approach, called segregated fit, actually approximates best-fit because any segment on the chosen free list is a good fit [49]. (Indeed, with power-of-two free lists, a segregated fit is necessarily within 2x of a perfect fit.) Approximations to best-fit are appealing because they exhibit low fragmentation in practice for a wide variety of workloads [15]. The algorithm for selecting a free segment depends on the allocation policy specified in the flags to vmem_alloc() as follows (in all cases, assume that the allocation size lies in the range [2n, 2n+1)):
Once we've selected a segment, we remove it from its free list. If the segment is not an exact fit, we split the segment, create a boundary tag for the remainder, and put the remainder on the appropriate free list. We then add the boundary tag of our newly allocated segment to a hash table so that vmem_free() can find it quickly. vmem_free() is straightforward: It looks up the segment's boundary tag in the allocated-segment hash table, removes it from the hash table, tries to coalesce the segment with its neighbors, and puts it on the appropriate free list. All operations are constant-time. Note that the hash lookup also provides a cheap and effective sanity check: The freed address must be in the hash table, and the freed size must match the segment size. This helps catch bugs such as duplicate frees. The key feature of the algorithm described above is that its performance is independent of both transaction size and arena fragmentation. Vmem appears to be the first resource allocator that performs allocations and frees of any size in guaranteed constant-time. 11.3.4.3. Locking StrategyFor simplicity, we protect each arena's segment list, free lists, and hash table with a global lock. We rely on the fact that large allocations are relatively rare and allow the arena's quantum caches to provide linear scalability for all the common allocation sizes. 11.3.4.4. Quantum CachingThe slab allocator can provide object caching for any vmem arena, so vmem's quantum caches are actually implemented as object caches. For each small integer multiple of the arena's quantum we create an object cache to service requests of that size. vmem_alloc() and vmem_free() simply convert each small request (size Example Assume the arena shown in Figure 11.6. A 3-page allocation would proceed as follows: vmem_alloc(foo, 3 * PAGESIZE) would call kmem_cache_alloc(foo->vm_qcache[2]). In most cases the cache's magazine layer would satisfy the allocation, and we would be done. If the cache needed to create a new slab it would call vmem_alloc(foo, 16 * PAGESIZE), which would be satisfied from the arena's segment list. The slab allocator would then divide its 16-page slab into five 3-page objects and use one of them to satisfy the original allocation. When we create an arena's quantum caches we pass to kmem_cache_create() a flag, KMC_QCACHE, that directs the slab allocator to use a particular slab size: the next power of 2 above 3 * qcache_max. We use this particular value for three reasons. (1) The slab size must be larger than qcache_max to prevent infinite recursion. (2) By numerical luck, this slab size provides near-perfect slab packing (e.g., five 3-page objects fill 15/16 of a 16-page slab). (3) We see below that using a common slab size for all quantum caches helps to reduce overall arena fragmentation. 11.3.4.5. Fragmentation
Fragmentation is the disintegration of a resource into unusably small, noncontiguous segments. To see how this can happen, imagine allocating a 1-Gbyte resource one byte at a time, then freeing only the even-numbered bytes. The arena would then have 500 Mbytes free, yet it could not even satisfy a 2-byte allocation. We observe that it is the combination of different allocation sizes and different segment lifetimes that causes persistent fragmentation. If all allocations are the same size, then any freed segment can obviously satisfy another allocation of the same size. If all allocations are transient, the fragmentation is transient. We have no control over segment lifetime, but quantum caching offers some control over allocation sizenamely, all quantum caches have the same slab size, so most allocations from the arena's segment list occur in slab-sized chunks. At first it may appear that all we've done is move the problem: The segment list won't fragment as much, but now the quantum caches themselves can suffer fragmentation in the form of partially used slabs. The critical difference is that the free objects in a quantum cache are of a size that's known to be useful, whereas the segment list can disintegrate into useless pieces under hostile workloads. Moreover, prior allocation is a good predictor of future allocation [48], so free objects are likely to be used again. It is impossible to prove that prior allocation helps,[2] but it seems to work well in practice. We have never had a report of severe fragmentation since vmem's introduction (we had many such reports with the old resource map allocator), and Solaris systems often stay up for years.
11.3.5. Vmem PerformanceSeveral performance studies were performed to validate Vmem's design. 11.3.5.1. Microbenchmark PerformanceWe've stated that vmem_alloc() and vmem_free() are constant-time operations regardless of arena fragmentation, whereas rmalloc() and rmfree() are linear-time. We measured alloc/free latency as a function of fragmentation to verify this. Figure 11.7 illustrates the results. Figure 11.7. Latency vs. Fragmentation rmalloc() has a slight performance edge at very low fragmentation because the algorithm is so naïve. At zero fragmentation, vmem's latency without quantum caching was 1560 ns, vs. 715 ns for rmalloc(). Quantum caching reduces vmem's latency to just 482 ns, so for allocations that go to the quantum caches (the common case) vmem is faster than rmalloc() even at very low fragmentation. 11.3.5.2. System-Level PerformanceVmem's low latency and linear scaling remedied serious pathologies in the performance of kernel virtual address allocation under rmalloc(), yielding dramatic improvements in system-level performance. LADDIS Veritas reported a 50% improvement in LADDIS peak throughput with the new virtual memory allocator [40]. Web Service On a large Starfire system running 2700 Netscape servers under the fair-share scheduler, vmem reduced system time from 60% to 10%, roughly doubling system capacity [37]. I/O Bandwidth An internal I/O benchmark on a 64-CPU Starfire generated such heavy contention on the old rmalloc() lock that the system was essentially useless. Contention was exacerbated by very long hold times due to rmalloc()'s linear search of the increasingly fragmented kernel heap. lockstat(1M) revealed that threads were spinning for an average of 48 milliseconds to acquire the rmalloc() lock, thus limiting I/O bandwidth to just 1000/48 = 21 I/O operations per second per CPU. With vmem, the problem completely disappeared and performance improved by several orders of magnitude. 11.3.6. SummaryThe vmem interface supports both simple and highly constrained allocations, and its importing mechanism can build complex resources from simple components. The interface is sufficiently general that we've been able to eliminate over 30 special-purpose allocators in Solaris since vmem's introduction. The vmem implementation has proven to be very fast and scalable, improving performance on system-level benchmarks by 50% or more. It has also proven to be very robust against fragmentation in practice. Vmem's instant-fit policy and external boundary tags appear to be new concepts. They guarantee constant-time performance regardless of allocation size or arena fragmentation. Vmem's quantum caches provide very low latency and linear scalability for the most common allocations. They also present a particularly friendly workload to the arena's segment list, which helps to reduce overall arena fragmentation. |
 qcache_max) into a kmem_cache_alloc() or kmem_cache_free() on the appropriate cache, as illustrated in Figure 11.6. Because it is based on object caching, quantum caching provides very low latency and linear scalability for the most common allocation sizes.
qcache_max) into a kmem_cache_alloc() or kmem_cache_free() on the appropriate cache, as illustrated in Figure 11.6. Because it is based on object caching, quantum caching provides very low latency and linear scalability for the most common allocation sizes.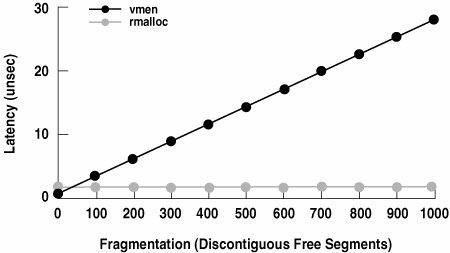
EAN: 2147483647
Pages: 244
- Article 220 Branch-Circuit, Feeder, and Service Calculations
- Article 424: Fixed Electric Space Heating Equipment
- Article 504 Intrinsically Safe Systems
- Example No. D2(c) Optional Calculation for One-Family Dwelling with Heat Pump(Single-Phase, 240/120-Volt Service) (See 220.82)
- Example No. D3 Store Building
- Chapter II Information Search on the Internet: A Causal Model
- Chapter VIII Personalization Systems and Their Deployment as Web Site Interface Design Decisions
- Chapter XI User Satisfaction with Web Portals: An Empirical Study
- Chapter XIV Product Catalog and Shopping Cart Effective Design
- Chapter XVII Internet Markets and E-Loyalty