Step 1: Crawling the Web Site
Step 1: Crawling the Web Site
Crawling a Web site begins with the first page and involves following every link found. For the mathematically inclined, crawling a site is the same as performing a breadth first search on a connected directional graph. A crawler is a program that automates this process. Think of it as a browser that can click on each link of the Web page by itself and traverse all the pages in the Web site. The crawler sends an HTTP "GET" request to a page, parses the HTML received, extracts all the hyperlinks from it, and recursively performs the same action on each link.
Crawlers can be quite sophisticated. Instead of simply following links, they can also mirror an entire Web site on the local hard drive and extract other elements such as comments, client-side scripts, and HTML comments. We discussed some of these techniques in Chapter 7.
Crawling a Site Manually
If a Web site doesn't contain many pages, you can follow the hyperlinks by simply using a browser to making a list of them. This technique is more accurate than using a crawler to gather links. One of the main drawbacks of automated crawling is that crawlers can't interpret client-side scripts, such as JavaScript, and the hyperlinks they contain.
A Closer Look at the HTTP Response Header
Each HTTP response has two parts namely, the HTTP response header and data content. Usually, data content is presented in HTML, but it also can be a byte block representing a GIF image or another object. Crawlers rely heavily on HTTP response headers while crawling a site. Consider this HTTP response header:
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Date: Sat, 16 Mar 2002 18:08:35 GMT
Connection: Keep-Alive
Content-Length: 496
Content-Type: text/html
Set-Cookie: ASPSESSIONIDQQGGGRHQ=DPHDNEMBEEHDNFMOPNPKIPHN; path=/
Cache-control: private
The first item to be inspected in the HTTP response header is the HTTP response code, which appears in the first line of the HTTP response header. In the preceding code snippet, the HTTP response code is "200," which signifies that the HTTP request was processed properly and that the appropriate response was generated. If the response code indicates an error, the error occurred when requesting the resource. A "404" response code indicates that the resource doesn't exist. A "403" response code signifies that the resource is blocked from requests, but nonetheless is present. Other HTTP response codes indicate that the resource may have relocated or that some extra privileges are required to request that resource. A crawler has to pay attention to these response codes and determine whether to crawl farther.
The next bit of important information returned in the HTTP response header, from a crawler's perspective, is the Content-Type field. It indicates the type of a resource represented by the data in the HTTP content that follows the HTTP response header. Again, the crawler has to pay attention to the Content-Type. A crawler attempting to extract links from a GIF file makes no sense, and crawlers usually pay attention only to "text/html" content.
Some Popular Tools for Site Linkage Analysis
Several commercial tools are available for use with crawling Web applications. We describe a few of the tools and discuss some of their key features in this section.
GNU wget
GNU wget is a simple command-line crawler and is available along with source code on http://www.wget.org/. Although wget was primarily intended for Unix platforms, a Windows binary is also available. Recall that we took a look at wget in Chapter 7, where we used it for mirroring a Web site locally and searching for patterns within the retrieved HTML data for source sifting. The advantages offered by wget are that it is simple to use, a command-line tool, and available on both Unix and Windows platforms. It also is very easy to use in shell scripts or batch files to further automate linkage analysis tasks.
Because wget offers the ability to mirror Web site content, we can run several commands or scripts on the mirrored content for various types of analysis.
BlackWidow from SoftByteLabs
SoftByteLabs' BlackWidow is a very fast Web site crawler for the Windows platform. The crawling engine is multithreaded and retrieves Web pages in parallel. BlackWidow also performs some basic source sifting techniques such as those discussed in Chapter 7. Figure 8-2 shows BlackWidow crawling http://www.foundstone.com/. On its tabs, you can view the progress of the crawling, thread by thread.
Figure 8-2. Blackwidow crawling one site with multiple threads
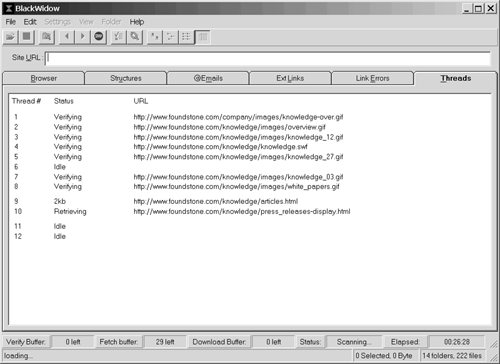
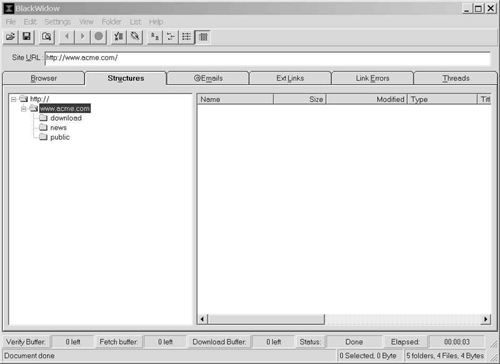
Figure 8-3 shows the site structure in a collapsible tree format. It helps us analyze how resources are grouped on the Web site. The BlackWidow GUI has other tabs that show e-mail addresses that are present on the pages, external links, and errors in retrieving links, if any. As with GNU wget, BlackWidow also can be used to mirror a Web site where URLs occurring within hyperlinks are rewritten for accessibility from the local file system.
Figure 8-3. Structure of http://www.acme.com/
Funnel Web Profiler from Quest Software
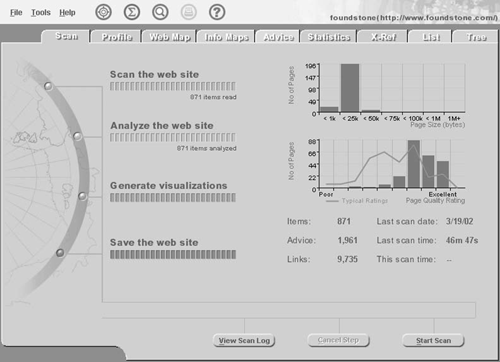
Funnel Web Profiler from Quest Software can perform an exhaustive analysis of a Web site. Quest Software has a trial version of Funnel Web Profiler available for download from http://www.quest.com. Figure 8-4 shows a Funnel Web Profiler in action running on http://www.foundstone.com/. This tool has a nice graphical user interface, which provides information such as content grouping, a Web site map, cross-references, a crawled statistics list view, and a tree view, among other things.
Figure 8-4. Funnel Web Profiler, showing scan statistics for http://www.foundstone.com/
After the Web site scan is completed, Funnel Web Profiler aggregates the information gathered and presents various representations and statistics about the site information. For example, clicking on the Web Map tab shows a graphical layout of the Web site and the pages in it. Figure 8-5 shows the Web map of http://www.foundstone.com/. Each Web resource is represented as a node, and the entire Web map shows how each node is linked with other nodes. The Web map presents a visual representation of the Web site and reveals the layout and linking of resources.
Figure 8-5. Funnel Web Profiler's Web map for http://www.foundstone.com/
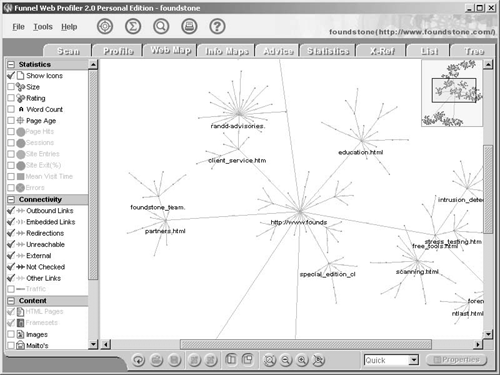
The Web map contains a cluster of linked nodes, with each node's starting point identified. The top right corner gives a thumbnail representation of the full Web map. It also allows the user to zoom in for a more detailed view.
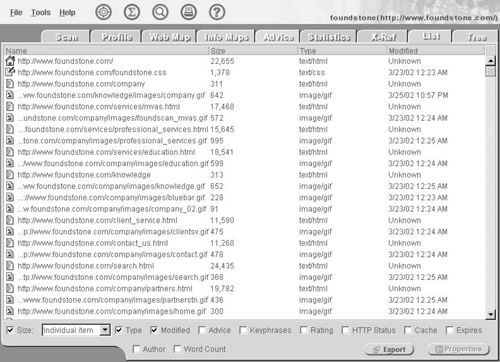
If we click on the List tab, we get a tabular list of all the Web resources on http://www.foundstone.com/, along with other information such as the type of resource, its size in bytes, and when it was modified. Figure 8-6 displays the list view of http://www.foundstone.com/.
Figure 8-6. List view of Web resources on http://www.foundstone.com/
Step-1 Wrap-Up
Some other tools which we haven't covered in detail but are worth mentioning are Teleport Pro from Tennyson Maxwell (http://www.tenmax.com/) and Sam Spade (http://www.samspade.org/). Teleport Pro runs on the Windows platform and is primarily used for mirroring Web sites. Teleport Pro allows users to define individual projects for mirroring sites. Site mirroring is quite fast with Teleport Pro's multithreaded mirroring engine. Sam Spade is also a Windows-based tool that allows basic site crawling and source-sifting. We now have quite a lot of information for performing thorough analysis. Let's see what we can do with all this information.
Crawlers and RedirectionAutomated Web crawlers sometimes get thrown off track when they encounter unusual linking techniques and page redirection. A few "smart" crawlers, however, can interpret these anomalies accurately and provide good crawled results. For example, a crawler may get confused when a redirection is encountered in a client-side script, because crawlers don't usually interpret client-side scripts such as JavaScript or VBScript. The following JavaScript code snippet has a redirection directive, which gets interpreted and executed on the browser: <SCRIPT LANGUAGE="JavaScript"> location.replace("./index.php3");</script> It instructs the browser to request index.php3. It will do so only if the JavaScript execution is enabled within the browser. When a crawler encounters this instruction, it won't be able to interpret and execute the location.replace() statement and it will fail to crawl index.php3. However, if the redirection is performed by techniques such as a Content-Location header response or an HTML <META> tag, the crawler could look for them and crawl the pages accordingly. The following two examples illustrate redirection with the HTTP response header and the <META> tag, respectively. |
Redirection by Content-LocationThe code snippet for this procedure is: HTTP/1.1 200 OKServer: Microsoft-IIS/5.0Date: Wed, 27 Mar 2002 08:13:01 GMTConnection: Keep-AliveContent-Location: http://www.example.com/example/index.aspSet-Cookie: ASPSESSIONIDQQGQGIWC=LNDJBOLAIFDAKJDBNDINOABF; path=/Cache-control: private Here we sent a GET request to a server, www.example.com, and requested the default Web resource on its root directory. Examining the header of the HTTP response, we see that it has a special field, Content-Location. This particular field forces the browser to request the URL http://www.example.com/example/index.asp. |
Redirection by HTTP-EQUIVWe can insert <META> tags of several types in the HTML header section The most common use of <META> tags is to list keywords associated with the HTML document. However, <META> tags can also be used for redirection. Using the HTTP-EQUIV clause within a <META> tag redirects the browser to a URL contained in it. The following <META> tag instructs the browser to refresh to http://www.yahoo.com/ after two seconds: <META HTTP-EQUIV=Refresh CONTENT="2; url=http://www.yahoo.com/"> Smart crawlers implement methods to parse redirection responses such as those shown in the preceding examples. However, some crawlers such as GNU wget are unable to handle tags with HTTP redirection. |
EAN: 2147483647
Pages: 156