COMMON EXPLOIT TECHNIQUES
| | ||
| | ||
| | ||
Every three to five years , a brand-new hacking technique comes out that catches everyone off guard. Although the concept of buffer overflows had been known for years, in the mid-1990s its popularity and the devastation caused by attacks taking advantage of buffer overruns really began to materialize. A couple years later it was attacks against libc vulnerabilities. A couple years after that it was format string vulnerabilities, off-by one buffer overruns, and database vulnerabilities. Then there were web-based attacks. Now we have integer overflow vulnerabilities. You get the picture. And with each release of these new types of vulnerabilities and attack vectors come new products to prevent hackers from taking advantage of those vulnerabilities. But the reality is that these problems cannot be solved by any one product or service. They need to be solved at the source: the developer or administrator.
In this section, we will discuss the techniques of the past ten years and address how each of these attacks came from a human being human.
Buffer Overflows and Design Flaws
Innumerable developer flaws creep into our world every day. Whether it be commercial code or open -source projects, these flaws can do tremendous damage to confidentiality, availability, and integrity. We will be discussing a number of developer flaws, including a number of overflow attacks in this section.
Two of the earliest papers about overflows came in 1995 from Mudge, with his paper "How to write Buffer Overflows" (http://www.subterrain.net/overflow-papers/bufero.txt), and in 1996 from Aleph1, with his paper "Smashing The Stack For Fun And Profit" (http://www.phrack.org/show.php?p=49&a=14). Both publicly discussed the concept at length and provided proof-of-concept code. The funny thing about papers like these is they raise the overall level of knowledge in the hacker underground . This has a massive domino effect, as other hackers learn the new tricks, the light bulb goes on, and then they contribute to the collective IQ. It's really important you realize what you're up against!
Let's discuss some specific buffer-overflow and design-flaw attacks and talk about how they could have been avoided.
Stack Buffer Overflows
| Popularity: | 10 |
| Simplicity: | 7 |
| Impact: | 10 |
| Risk Rating: | 9 |
A stack-based buffer overrun is the easiest and most devastating buffer overrun and tends to make hackers go all gooey! Here's how it works. The stack is simply computer memory used when functions call other functions. The goal of a hacker when attacking a system with a buffer overrun is to change the flow of execution from what would be the normal function-to-function execution to a flow determined by the attacker. Now here's the crux: The stack contains data, including variables private to the function (called local variables), function arguments, and most dangerously, the address of the instruction to return to when the function finishes. When FunctionA calls FunctionB, the CPU needs to know where to go back to when FunctionB finishes; this data is held on the stack, right after the local variables.
Consider the following code sample:
void functionB(char *title) { char tmp_array[12]; strcpy(tmp_array, data); } void functionA() { functionB( ReadDataFromNetwork(socket) ); } In this example, functionA passes a string read from the network to functionB, and the string argument is named title . Note, a string in C and C++ is a series of bytes followed by a zero character, often called the NULL-terminator. The problem here is that the data comes from the network, which means it could come from a bad guy, and possibly be any length! The local variable tmp_array is allocated 12 bytes on the stack ( char tmp_array[12] ) to store its data. Then the code calls the strcpy() function, which keeps copying the characters from title (remember, the bad guy controls this data) into tmp_array until it hits the NULL-terminator at the end of title, but because title could be longer than the length of tmp_array (24 bytes, plus the trailing NULL-terminator, for a total of 25 bytes versus 12 bytes) the data will overflow past the end of tmp_array into other parts of memory. Now remember we said that one of the values on the stack is the address where functionB must return to. If the buffer overrun overwrites that value on the stack, when functionB returns it will take that value off the stack and continue execution from that point onward. But the attacker can just set this value to any value he wants, hence he can change the normal execution flow to anything he wants. The classic attack includes malicious assembly language in the buffer, so the attacker returns to the start of his buffer and executes the code in the buffer. This is, of course, very bad! Very, very bad.
Since 1995 there have been over a thousand buffer overflow vulnerabilities exposed to the public. Many buffer overrun bugs have come and gone without much public hoopla, whereas others have been turned into viscous worms that have laid waste to many networks and systemsNimda (Windows), Slammer (SQL Server), Scalper (FreeBSD), Slapper (Apache and OpenSSL), Witty (ISS RealSecure), and so on. Even though a buffer overrun does not always lead to a worm, we know of numerous one-off attacks against users that take advantage of an unpatched buffer overrun bug.
Stack Buffer Overflow Countermeasures
The only real prevention to this insidious problem is managing the data being received from users (and attackers ). As a programmer, you need to check both the quantity and quality of the data being sent to your program and ensure that no unsanitized data passes to buffer manipulation functions. Here's a list of proven techniques for managing this insidious threat:
-
Practice safe and secure coding standards, especially when dealing with buffers from C and C++. Educate and enforce proper coding standards with your development staff. Ensure proper use of function calls, and presume that the data coming in from the user will not be bounds-checked prior to being received.
-
Check your code. Perform regular source code audits looking for commonly misused functions such as (but not limited to) sprintf(), vsprintf(), strcat(), strcpy(), gets(), scanf(), and so on. Numerous tools are available, such as CodeSurfer and PREfast (included in Microsoft's Visual Studio.NET 2005), that will review your source code and find unsafe function usage.
| Caution | Be wary of tools that simply grep for commonly misused function calls. They are brain dead and cannot weed out real bugs from noise. |
-
Seriously consider prohibiting the use of old C runtime buffer functions that do not bound the copy by the size of the destination buffer. For example, strcpy should be replaced with strncpy (C runtime), strcpy_s (SafeCRT in Visual Studio .NET 2005), or strlcpy (BSD).
-
Employ stack execution protection. On many platforms, such as Windows XP SP2, Windows Server 2003, Solaris, Linux, and OpenBSD, you can reduce the chance these attacks are successful by setting memory to not allow execution. Windows XP SP2 (with appropriate hardware) and OpenBSD do this by default, but you must set this manually on Solaris. Linux support is available through PaX. Commercial solutions include McAfee's Entercept.
-
Use compiler tools. Numerous tools can be used to detect stack overruns at runtime. For example, the Microsoft Visual C++ product now has the /GS option, and for GCC you can use StackShield (http://www.angelfire.com/sk/stackshield/index.html) and StackGuard (http://www.immunix.org). One other freeware/open-source product worth looking at is Libsafe (http://www.research.avayalabs.com/project/libsafe).
Heap/BSS/Data Overflows
| Popularity: | 8 |
| Simplicity: | 5 |
| Impact: | 9 |
| Risk Rating: | 7 |
Heap/BSS/data overflows are a little different from stack overflows, and up until only recently they have been incredibly difficult to write. For the last couple years there has been a great deal of research in this area, and now heap-based overflows are commonplace. Instead of overwriting the stack, they overwrite the heap. The heap is used by programs to allocate dynamic memory at runtime. There are no return function addresses to overwrite on the heap; these attacks depend on overwriting important variables or sensitive heap block structures that contain addresses. If an attacker could overwrite a permission with an "Access Allowed" setting, he could gain unauthorized access to the service or computer system. Alternatively, heap overflows can potentially take advantage of a function pointer stored after the overflowed buffer, allowing the attacker to overwrite the function pointer and point it to his own code. This tends to be much more random than stack overflows due to the randomness of the memory layout, but don't let this fool you. Many heap-based attacks have led to compromised computer systems.
There are numerous examples of heap overflows today, and we discuss many of them in this book. One such vulnerability was found in the Titan FTP Server for Windows. The Bugtraq ID is 11069 and was released August 30, 2004. The basic vulnerability is simple. An attacker passes an overly long directory name to the FTP server's CWD (change working directory) command, where the directory name is greater than 20,480 bytes long. This causes a heap-based buffer overrun, allowing the attacker to pass in arbitrary commands of his choosing. There is at least one public proof-of-concept exploit for this vulnerability, and it can be found at http://www.cnhonker.com. When you take a look at the source code, you can see how simple and elegant the code is.
An old but good analysis of heap/BSS/data overflow attacks can be found at http://www.w00w00.org/files/articles/heaptut.txt.
Heap/BSS/Data Overflow Countermeasures
The coding countermeasures for stack-based buffer overflows apply to heap-based overruns as well. By checking both the size and type of input, you can ensure that only valid data is being sent to your programs. Refer to the first input validation countermeasure for stack buffer overflows, earlier in the chapter. The more you can do to sanitize the input you receive from your end users, the more you will be able to prevent heap overflow attacks.
Some operating systems also add countermeasures to the heap. For example, Windows Server 2003 and Windows XP SP2 check whether sensitive data in the heap blocks is correctly formed .
| Caution | There is no better countermeasure than writing good, secure code. Mitigations such as StackGuard, /GS, heap protection, and so on are simply extra defensive mechanisms, and they should not be seen as a replacement for good code. |
Format String Attacks
| Popularity: | 6 |
| Simplicity: | 7 |
| Impact: | 9 |
| Risk Rating: | 7 |
Like overflow vulnerabilities, the idea behind format string attacks is to overwrite portions of memory to give the hacker control over the CPU's execution flow (in other words, to do something evil with it). Format string attacks take advantage of a programmer's misuse of certain functionsmost notably, the printf() family of functions, which simply prints something to the screen. For example,
printf("Hello world. My name is: %s\n", my_name); would print out this:
Hello world. My name is: Stuart McClure
Presuming, of course, that the variable my_name is properly set to the string "Stuart McClure". The %s characters are a placeholder for a string to be printed by the printf() function. Now, consider how many real-world applications incorrectly use printf() . Many programmers will utilize the shortcut version of this function by writing the following:
printf(my_name);
The problem with this is that the programmer assumes that the my_name string is a legitimate string to be printed verbatim and trusted completely. Oh the pain! What actually happens with the printf() function in this case is that it will scan the my_name string for format characters such as %s and %n, looking for ways to properly print out the variables. Then, as each special format character is found, it will retrieve a variable number of argument values from the stack. Now, what do you think would happen in this scenario if an attacker passed in three format characters %s %d %urather than his name? Most likely, the printf() function would print out the random location in memory where those variables are supposed to reside. So what if you can view memory locations, you say? Well, this is the best-case scenario. The worst case is that we can pick out an arbitrary address in memory and write a value into it. And if you can overwrite a portion of memory, you can potentially overwrite a function pointer and run arbitrary code.
Another example of a format string bug occurs when calling sprintf(), which rather than printing the string to the console copies the results into a buffer. The following code shows this. If the length of my_name plus the length of the format string ("My name is", or 11 characters) is greater than the destination buffer size, 32 bytes, then you get a classic stack smash.
char temp[32]; sprintf(temp,"My name is %s.",my_name);
One of the simplest explanations of a format string vulnerability can be found at Tim Newsham's website (http://www.lava.net/~newsham/format-string-attacks.pdf).
Format String Countermeasures
The best ways to remove format string vulnerabilities are as follows :
-
Hard code the format specifier in your functions. In other words, be sure to utilize the complete printf() function:
printf("Hello world. My name is: %s\n", my_name); -
For sprintf() functions, use snprintf (), which bounds the copy to the destination buffer size.
Also, refer to the first input validation countermeasure for stack buffer overflows, earlier in the chapter. The more you can do to sanitize the input you receive from your end users, the more you will be able to prevent format string attacks.
Off-by-One Errors
| Popularity: | 5 |
| Simplicity: | 9 |
| Impact: | 7 |
| Risk Rating: | 7 |
Programmers are human, right? We keep saying that. And the programming off-by one error is yet another example of this problem, because it's such an easy mistake to make. Basically, an off-by-one error occurs when a programmer miscounts something in his conditional statement. For example, an OpenSSH vulnerability discovered in 2002 demonstrated this problem magnificently. When the programmer wrote
if (id < 0 id > channels_alloc)
he expected to say that given the condition where id is less than 0 or greater than the number of channels allocated, then error out. This works fine in normal circumstances, in that it would deny access to the SSH tunnel because the channel number is out of range. However, he missed a key conditionwhen id is equal to the variable ( channels_ alloc ). If this condition occurs, an attacker could pretend to be a normal user, log in, and gain administrative-level access to the system.
Off-by-One Countermeasures
The proper implementation of this particular logic would be the following:
if (id < 0 id >= channels_alloc)
This way, if id is ever equal to the channels_alloc value, it would still execute, and be handled properly, rather than passed through.
As a side issue, about two years before this bug was found, another bug was found in the same code. It wasn't a security bug, but it does highlight another common coding defectmixing "and" and "or" operators. Here is how the code used to read:
if (id < 0 && id > channels_alloc)
The moral of this story is that you should check all logic operations, regardless of programming language, to determine their correctness.
Input Validation Attacks
Input validation attacks occur in much the same way buffer overflows do. Effectively, a programmer has not sufficiently reviewed the input from a user (or attacker, remember!) before passing it onto the application code. In other words, the program will choke on the input or, worse , allow something through that shouldn't get through. The results can be devastating, including denial of service, identity spoofing, and outright compromise of the system, as is the case with buffer overruns. In this section, we take a look at a few input validation attacks and discuss how programmers can resolve the fundamental issues.
Canonicalization Attacks
| Popularity: | 5 |
| Simplicity: | 9 |
| Impact: | 7 |
| Risk Rating: | 7 |
In the web world, few other attacks have given so much pause to so many developers. When the first expression of this vulnerability was unearthed, people thought it was another simple "breaking web root" exercise. As discussed in Chapter 12, this attack manifested itself in the Unicode (ISO 10646) and Double Decode attacks in 2001/2002.
Canonicalization is the process for determining how various forms or characters of a word are resolved to a single name or character, otherwise called the canonical form. For example, the backslash character is / in ASCII and %2f in hex. When represented in UTF-8 (the ACSII preserving encoding method for Unicode), it is also %2f, because UTF8 requires characters be represented in the smallest number of legal bytes. However, the backslash character can also be represented as %c0%af, which is the 2-byte UTF-8 escape. You could also use 3-byte and 4-byte representations. Technically, these multibyte variations are invalid, but some applications don't treat them as invalid. And if a web server canonicalizes that character after the rules for directory traversal are checked, you could have a mess on your hands.
For example, the following URL would normally be blocked at the web server URL parser and not allowed because it includes dot-dot characters and backslashes, as shown in Figure 11-1:
http://10.1.1.3/scripts/../../../../winnt/system32/cmd.exe?/c+dir
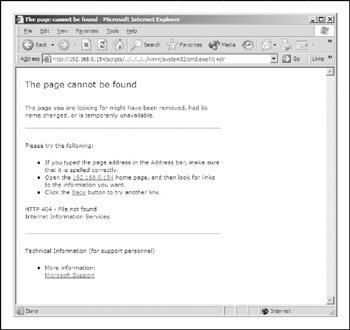
Figure 11-1: A directory traversal attempt that would be blocked by a web server
This attempt is to break web root, crawl up the drive's directory, and then go down the/winnt/system32 directory to execute the cmd.exe command. The command shell then would execute the dir command, which is an internal DOS command within cmd. exe . Now, if we were to change out the backslash characters ( / ) for the overlong UTF-8 representation of that character ( %c0%af ) or any of a number of similar representations, the vulnerable version of IIS4 would not spot the backslash characters and allow the directory traversal, as shown in Figure 11-2:
http://10.1.1.3/scripts/..%c0%af..%c0%af..%c0%af../winnt/system32/cmd.exe?/c+dir
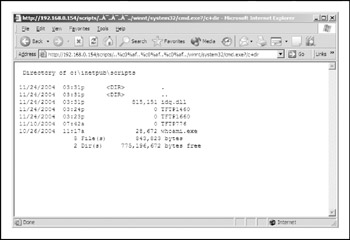
Figure 11-2: A directory traversal attempt that would not be blocked by a vulnerable web server
There are other kinds of canonical-form defects, including double-escapes and Unicode escapes . Table 11-1 shows a small sample.
| Escape | Comment |
|---|---|
| %c0%af | 2-byte overlong UTF-8 escape |
| %e0%80%af | 3-byte overlong UTF-8 escape |
| %252f | Double-escape; %25 is an escaped % character |
| %%35c | Double-escape; %35 is an escaped 5 character |
| %25%35%63 | Double-escape, where every character in %5c is escaped |
| %%35%63 | %, then escaped 5 and escaped c |
| %255c | Escape %, then 5c |
| %u005c | 2-byte Unicode escape |
Again, this type of attack takes advantage of the lack of proper translation of characters into their normalized form before being handled. This attack can take many forms and must be thoroughly addressed in all your running applications.
In recent years, there have been numerous canonicalization issues with web servers, such as IIS and Apache and their technologies, including PHP and ASP.NET.
Canonicalization Countermeasures
The best way to mitigate canonicalization attacks is to address the problem with the language you are writing in. For example, for ASP.NET applications, Microsoft recommends that you insert the following in the global.asax file, which mitigates some forms of path canonicalization:
<script language="vb" runat="server"> Sub Application_BeginRequest(Sender as Object, E as EventArgs) If (Request.Path.IndexOf(chr(92)) >= 0 OR _ System.IO.Path.GetFullPath(Request.PhysicalPath) <> Request. PhysicalPath) then Throw New HttpException(404, "Not Found") End If End Sub </script>
Effectively, this event handler in global.asax prevents invalid characters and malformed URLs by performing path verifications.
You can also mitigate these threats by being very hardcore about what data your application will accept. You can use a tool such as URLScan in front of your IIS5 web server to mitigate many of these issues. Note that URLScan can also help prevent your application sitting on top of IIS from being attacked through vulnerabilities in your code. Also note that IIS6 has the URLScan-like capability built right in.
Web Application and Database Attacks
| Popularity: | 10 |
| Simplicity: | 10 |
| Impact: | 3 |
| Risk Rating: | 8 |
As we discuss in Chapter 12, there are many ways to bypass web application security. From identity spoofing to variable stuffing , each technique can allow an attacker to either assume someone's online identity, overflow an application, or get around some controls on that application.
Web Application/Database Attack Countermeasures
The fundamental problem here, as with almost every attack discussed in this chapter, is a lack of proper input sanitization performed by the programmer. If every input data element (form fields, network packets, and so on) accepted by all network-connected software (such as browsers, database servers, and web servers) was properly validated and sanitized, most of these problems would simply disappear.
EAN: N/A
Pages: 127