INTERNET FOOTPRINTING
| | ||
| | ||
| | ||
Although many footprinting techniques are similar across technologies (Internet and intranet), this chapter focuses on footprinting an organization's Internet connection(s). Remote access is covered in detail in Chapter 8.
It is difficult to provide a step-by-step guide on footprinting because it is an activity that may lead you down several paths. However, this chapter delineates basic steps that should allow you to complete a thorough footprint analysis. Many of these techniques can be applied to the other technologies mentioned earlier.
Step 1: Determine the Scope of Your Activities
The first item of business is to determine the scope of your footprinting activities. Are you going to footprint the entire organization, or limit your activities to certain subsidiaries or locations? What about business partner connections (extranets), or disaster-recovery sites? Are there other relationships or considerations? In some cases, it may be a daunting task to determine all the entities associated with an organization, let alone properly secure them all. Unfortunately, hackers have no sympathy for our struggles. They exploit our weaknesses in whatever forms they manifest themselves . You do not want hackers to know more about your security posture than you do!
Step 2: Get Proper Authorization
One thing hackers can usually disregard that you must pay particular attention to is what we techies affectionately refer to as layers eight and nine of the seven-layer OSI ModelPolitics and Funding. These layers often find their way into our work in one way or another, but when it comes to authorization, they can be particularly tricky. Do you have authorization to proceed with your activities? For that matter, what exactly are your activities? Is the authorization from the right person(s)? Is it in writing? Are the target IP addresses the right ones? Ask any penetration tester about the "get-out-of-jailfree-card" and you're sure to get a smile.
Step 3: Publicly Available Information
After all these years on the Web, I still regularly find myself in a moment of awed reverence to the sheer vastness of the Internetand to think it's still quite young!
Publicly Available Information
| Popularity: | 9 |
| Simplicity: | 9 |
| Impact: | 2 |
| Risk Rating: | 7 |
The amount of information that is readily available about you, your organization, its employees , and anything else you can image is nothing short of amazing.
So what are the needles in the proverbial haystack that we're looking for?
-
Company web pages
-
Related organizations
-
Location details
-
Phone numbers , contact names , e-mail addresses, and personal details
-
Current events (mergers, acquisitions, layoffs, rapid growth, etc.)
-
Privacy or security policies, and technical details indicating the types of security mechanisms in place
-
Archived information
-
Disgruntled employees
-
Search engines, Usenet, and resumes
-
Other information of interest
Company Web Pages
Perusing the target organization's web page will often get you off to a good start. Many times, a website will provide excessive amounts of information that can aid attackers . We have actually seen organizations list security configuration details directly on their Internet web servers.
In addition, try reviewing the HTML source code for comments. Many items not listed for public consumption are buried in HTML comment tags, such as <, !, and . Viewing the source code offline may be faster than viewing it online, so it is often beneficial to mirror the entire site for offline viewing. Having a copy of the site locally may allow you to programmatically search for comments or other items of interest, thus making your footprinting activities more efficient. Wget (http://www.gnu.org/software/wget/wget.html) for UNIX and Teleport Pro (http://www.tenmax.com) for Windows are great utilities to mirror entire websites .
Be sure to investigate other sites beyond the main "www" sites as well. Many organizations have sites to handle remote access to internal resources via a web browser. Microsoft's Outlook Web Access is a very common example. It acts as a proxy to the internal Microsoft Exchange servers from the Internet. Typical URLs for this resource are https://owa.company.com or https ://outlook.company.com. Similarly, organizations that make use of mainframes or AS/400s may offer remote access via a web browser via services like OpenConnect (http://www.openconnect.com), which serves up a Javabased 3270 emulator and allows for "green screen" access to the internal mainframes and/or AS/400s via the client's browser.
VPNs are very common in most organizations as well, so looking for sites like http://vpn.company.com or http://www.company.com/vpn will often reveal sites designed to help end users connect to their companies' VPNs. You may find VPN vendor and version details as well as detailed instructions on how to download and configure the VPN client software. These sites may even include a phone number to call for assistance if the hackerer, I mean, employeehas any trouble getting connected.
Related Organizations
Be on the lookout for references or links to other organizations that are somehow related to the target organization. Even if an organization keeps a close eye on what it posts about itself, its partners may not be as security-minded. They may reveal additional details that, when combined with your other findings, could result in a more sensitive aggregate than your sites revealed on their own. Taking the time to check out all the "leads" will often pay nice dividends in the end.
Location Details
A physical address can prove very useful to a determined attacker. It may lead to dumpsterdiving, surveillance, social-engineering, and other nontechnical attacks. Physical addresses could also lead to unauthorized access to buildings , wired and wireless networks, computers, etc. It is even possible for attackers to attain detailed satellite imagery of your location from various sources on the Internet. My personal favorite is http://www. keyhole .com (see Figure 1-1), a Google company. It essentially puts the world (or at least most major metro areas around the world) in your hands and lets you zoom in on addresses with amazing clarity and detail via a well-designed client application. Another popular source is http://terraserver.microsoft.com.
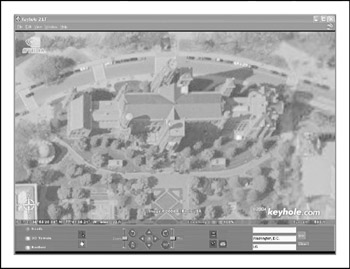
Figure 1-1: With http://www.heyhole.com, someone can footprint your physical presence with remarkable detail and clarity.
Phone Numbers, Contact Names, E-mail Addresses, and Personal Details
Attackers can use phone numbers to look up your physical address via sites like http://www.phonenumber.com, http://www.411.com, and http://www.yellowpages.com. They may also use your phone number to help them target their war-dialing ranges, or to launch social-engineering attacks to gain additional information and/or access.
Contact names and e-mail addresses are particularly useful items. Most organizations use some derivative of the employee's name for their username and e-mail address (for example, John Smith's username is jsmith, johnsmith, or smithj, and his e-mail address is jsmith@company.com or something similar). If we know one of these items, we can probably figure out the others. Having a username is very useful later in the methodology when we try to gain access to system resources. All of these items can be useful in social engineering as well.
Other personal details can be readily found on the Internet using any number of sites like http://www.crimetime.com/online.htm, which links to several resources, and http://www.peoplesearch.com, which can give hackers personal details ranging from home phone numbers and addresses to social security numbers, credit histories, and criminal records, among other things. Attackers might use any of this information to assist them in their questsextortion is still alive and well. An attacker might also be interested in an employee's home computer, which probably has some sort of remote access to the target organization. A keystroke logger on an employee's home machine or laptop may very well give a hacker a free ride to the organization's inner sanctum. Why bang one's head against the firewalls, IDS, IPS, etc., when the hacker can simply impersonate a trusted user ?
Current Events
Current events are often of significant interest to attackers. Mergers, acquisitions, scandals, layoffs, rapid hiring, reorganizations, outsourcing, extensive use of temporary contractors, and other events may provide clues, opportunities, and situations that didn't exist before. For instance, one of the first things to happen after a merger or acquisition is a blending of the organizations' networks. Security is often placed on the back burner in order to expedite the exchange of data. How many people have heard , "I know it isn't the most secure way to do it, but we need to get this done A.S.A.P. We'll fix it later." In reality, "later" often never comes, thus allowing an attacker to exploit a weaker subsidiary in order to access a back-end connection to the primary target.
The human factor comes into play during these events, too. Morale is often low during times like these, and when morale is low, people may be more interested in updating their resumes than watching the security logs or applying the latest patch. At best, they are somewhat distracted. There is usually a great deal of confusion and change during these times, and most people don't want to be perceived as uncooperative or as inhibiting progress. This provides for increased opportunities for exploitation by a skilled social engineer.
The reverse can also be true. When a company experiences rapid growth, often times their processes and procedures lag behind. Who's making sure there isn't an unauthorized guest at the new-hire orientation? Is that another new employee walking around the office, or is it an unwanted guest? Who's that with the laptop in the conference room? Is that the normal paper-shredder company? Janitor?
If the company is a publicly traded company, current events are widely available on the Internet. In fact, publicly traded companies are required to file certain periodic reports to the Securities and Exchange Commission (SEC) on a regular basis; these reports provide a wealth of information. Two reports of particular interest are the 10-Q (quarterly) and the 10-K (annual) reports, and you can search the EDGAR database at http://www.sec.gov (see Figure 1-2) to view them. When you find one of these reports , search for keywords like "merger," "acquisition," "acquire," and " subsequent event." With a little patience, you can build a detailed organizational chart of the entire organization and its subsidiaries. Business-information and stock-trading sites can provide similar data. Comparable sites exist for major markets around the world. An attacker can use this information to target weak points in the organization. Most hackers will choose the path of least resistanceand why not?
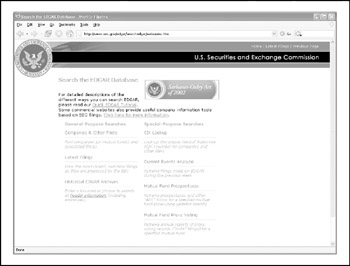
Figure 1-2: Publicly traded companies must file regular reports with the SEC. These reports provide interesting information regarding current events and organizational structure.
Privacy or Security Policies, and Technical Details Indicating the Types of Security Mechanisms in Place
Any piece of information that provides insight into the target organization's privacy or security policies, or technical details regarding hardware and software used to protect the organization, can be useful to an attacker for obvious reasons. Opportunities will most likely present themselves when this information is acquired .
Archived Information
It's important to be aware that there are sites on the Internet where you can retrieve archived copies of information that may no longer be available from the original source. This could allow an attacker to gain access to information that has been deliberately removed for security reasons. Some examples of this are the Wayback Machine at http://www.archive.org (see Figure 1-3), http://www.thememoryhole.org, and the cached results you see under Google's cached results (see Figure 1-4).
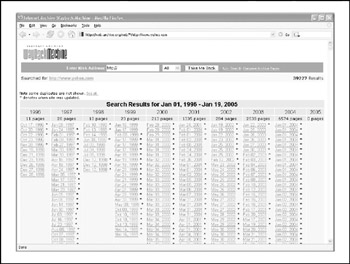
Figure 1-3: A search at http://www.archive.org reveals many years of archived pages from http://www.yahoo.com.
Figure 1-4: The very nature of a search engine can easily allow anyone access to cached content from sites that it has crawled. Here we see a cached version of http://www.yahoo.com from Google's archive.
Disgruntled Employees
Another real threat to an organization's security can come from disgruntled employees, ex-employees, or sites that distribute sensitive information about organizations' internal dealings. A quick perusal of sites like http://www.f**kedcompany.com or http://www.internalmemo.com should give you an idea of what I'm referring to. If you ask anyone about disgruntled employee stories, you are likely to hear some pretty amazing tales of revenge . It's not uncommon for people to steal, sell, and give away company secrets, damage equipment, destroy data, set logic bombs to go off at predetermined times, leave backdoors for easy access later, or any number of other dubious acts. This is one of the reasons today's dismissal procedures often include security guards , HR personnel, and a personal escort out of the building. One of Google's advanced searches, "link: http://www.company.com," reveals any site that Google knows about with a link to the target organization. This can prove to be a good way to find nefarious sites with information about the target organization.
Search Engines, Usenet, and Resumes
The search engines available today are truly fantastic. Within seconds, you can find just about anything you could ever want to know. Many of today's popular search engines provide for advanced searching capabilities that can help you home in on that tidbit of information that makes the difference. Some of our favorite search engines are http://www.google.com, http://search.yahoo.com, http://www. altavista .com, and http://www.dogpile.com (sends your search to multiple search engines). It is worth the effort to become familiar with the advanced searching capabilities of these sites. There is so much sensitive information available through these sites that there have even been books written on how to "hack" with search enginesfor example, Google Hacking for Penetration Testers, by Johnny Long (Syngress, 2004).
Here is a simple example: If you search Google for "allinurl:tsweb/default.htm", Google will reveal Microsoft Windows servers with Remote Desktop Web Connection exposed. This could eventually lead to full graphical console access to the server via the Remote Desktop Protocol (RDP) using only Internet Explorer and the ActiveX RDP client that the target Windows server offers to the attacker when this feature is enabled. There are literally hundreds of other searches that reveal everything from exposed web cameras to remote admin services to passwords to databases. We won't attempt to reinvent the wheel here, but instead will refer you to one of the definitive Google hacking sites available at http://johnny.ihackstuff.com. Johnny Long has worked to compile the Google Hacking Database (GHDB) and continually updates it with new and interesting searches.
Of course, just having the database of searches isn't good enough, right? A few tools have been released recently that take this concept to the next level: Athena, by Steve at snakeoillabs; SiteDigger, by http://www.foundstone.com; and Wikto, by Roelof and the crew at http://www.sensepost.com/research/wikto. They search Google's cache to look for the plethora of vulnerabilities, errors, configuration issues, proprietary information, and interesting security nuggets hiding on websites around the world. SiteDigger (Figure 1-5) allows you to target specific domains, uses the GHDB or the streamlined Foundstone list of searches, allows you to submit new searches to be added to the database, allows for raw searches, andbest of allhas an update feature that downloads the latest GHDB and/or Foundstone searches right into the tool so you never miss a beat.
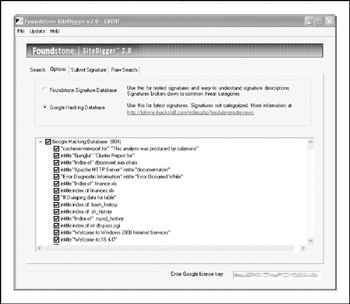
Figure 1-5: Foundstone's SiteDigger searches Google's cache using the Google Hacking Database (GHDB) to look for vulnerable systems.
The Usenet discussion forums or news groups are a rich resource of sensitive information, as well. One of the most common uses of the news groups among IT professionals is to get quick access to help with problems they can't easily solve themselves. Google provides a nice web interface to the Usenet news groups, complete with its now-famous advanced searching capabilities. For example, a simple search for "pix firewall config help" yields hundreds of postings from people requesting help with their Cisco PIX firewall configurations, as shown in Figure 1-6. Some of these postings actually include cut-and-pasted copies of their production configuration, including IP addresses, ACLs, password hashes, network address translation (NAT) mappings, etc. This type of search can be further refined to home in on postings from e-mail addresses at specific domains (in other words, @company.com) or other interesting search strings.
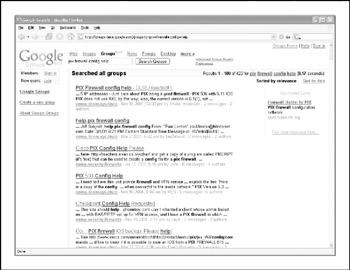
Figure 1-6: Again, Google's advanced search options can help you home in on important information quickly.
If the person in need of help knows not to post his or her configuration details to a public forum like this, he or she might still fall prey to a social engineering attack. An attacker could respond with a friendly offer to assist the weary admin with his or her issue but will definitely need more details to be of any real use. If the attacker can finagle a position of trust, he or she may end up with the same sensitive information despite the initial caution of the admin.
Another interesting source of information lies in the myriad of resumes available online. With the IT profession being as vast and diverse as it is, finding a perfect employee-to-position match can be quite difficult. One of the best ways to reduce the large number of false positives is to provide very detailed, often sensitive, information in both the job postings and in the resumes.
Imagine that an organization is in need of a seasoned IT security professional to assume very specific roles and job functions. He or she needs to be proficient with this, that, and the other thing, as well as able to program this and that you get the idea. The company must provide those details in order to get qualified leads ( vendors , versions, specific responsibilities, level of experience required, etc.). So if the organization is posting for a security professional with, say, five or more years' experience working with CheckPoint firewalls and Snort IDS, what kind of firewall and IDS do you think they use? Maybe they are advertising for an intrusion-detection expert to develop and lead their IR team. What does this say about their current incident detection and response capabilities? Could they be in a bit of disarray? Do they even have one currently? If the posting doesn't provide the details, maybe a phone call will. The same is true for an interesting resumeimpersonate a headhunter and start asking questions. These kinds of details can help an attacker paint a detailed picture of security posture of the target organizationvery important to know when planning an attack!
If you do a search on Google for something like " company resume firewall," where company is the name of the target organization, you will most likely find a number of resumes from current and/or past employees of the target that include very detailed information about technologies they use and initiatives they are working on. Job sites like http://www.monster.com and http://www.carearbuilder.com contain tens of millions of resumes and job postings. Searching on organization names may yield amazing technical details. In order to tap into the vast sea of resumes on these sites, you have to be a registered organization and pay access fees. However, it is not too hard for an attacker to front a fake company and pay the fee in order to access the millions of resumes.
Other Information of Interest
The aforementioned ideas and resources are not meant to be exhaustive but should serve as a springboard to launch you down the information-gathering path. Sensitive information could be hiding in any number of places around the world and may present itself in many forms. Taking the time to do creative and thorough searches will most likely prove to be a very beneficial exerciseboth for the attackers and the defenders.
Public Database Security Countermeasures
Much of the information discussed earlier must be made publicly available and, therefore, is difficult to remove; this is especially true for publicly traded companies. However, it is important to evaluate and classify the type of information that is publicly disseminated. The Site Security Handbook (RFC 2196), found at http://www.faqs.org/rfcs/rfc2196.html, is a wonderful resource for many policy-related issues. Periodically review the sources mentioned in this section and work to remove sensitive items wherever you can. The use of aliases that don't map back to you or your organization is advisable as well, especially when using newsgroups, mailing lists, or other public forums.
Step 4: WHOIS & DNS Enumeration
| Popularity: | 9 |
| Simplicity: | 9 |
| Impact: | 5 |
| Risk Rating: | 8 |
While much of the Internet's appeal stems from its lack of centralized control, in reality several of its underlying functions must be centrally managed in order to ensure interoperability, to prevent IP conflicts, and to ensure "universal resolvability" across geographical and political boundaries. This means that someone is managing a vast amount of information. If you understand a little about how this is actually done, you can effectively tap into this wealth of information! The Internet has come a long way since its inception. The particulars of how all this information is managed, and by whom, is still evolving as well.
So who is "managing" the Internet today, you ask? These core functions of the Internet are "managed" by a nonprofit organization named the Internet Corporation for Assigned Names and Numbers (ICANN; http://www.icann.org).
ICANN is a technical coordination body for the Internet. Created in October 1998 by a broad coalition of the Internet's business, technical, academic, and user communities, ICANN is assuming responsibility for a set of technical functions previously performed under U.S. government contract by the Internet Assigned Numbers Authority (IANA; http://www.iana.org) and other groups. (In practice, IANA still handles much of the day-to-day operations, but these will eventually be transitioned to ICANN.)
Specifically, ICANN coordinates the assignment of the following identifiers that must be globally unique for the Internet to function:
-
Internet domain names
-
IP address numbers
-
Protocol parameters and port numbers
In addition, ICANN coordinates the stable operation of the Internet's root DNS server system.
As a nonprofit, private-sector corporation, ICANN is dedicated to preserving the operational stability of the Internet; to promoting competition; to achieving broad representation of global Internet communities; and to developing policy through private-sector, bottom-up, consensus-based means. ICANN welcomes the participation of any interested Internet user, business, or organization.
Figure 1-7 illustrates ICANN's overall organizational structure as a result of its Evolution and Reform Process, conducted in 2002. Transition to this new structure began on December 15, 2002, when ICANN's new bylaws came into effect.
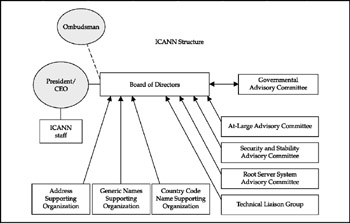
Figure 1-7: ICANN manages many of the underlying core functions of the Internet.
While there are many parts to ICANN, three of the suborganizations are of particular interest to us at this point:
-
Address Supporting Organization (ASO) http://www.aso.icann.org
-
Generic Names Supporting Organization (GNSO) http://www.gnso.icann.org
-
Country Code Domain Name Supporting Organization (CCNSO) http://www.ccnso.icann.org
The ASO reviews and develops recommendations on IP address policy and advises the ICANN Board on these matters. The ASO allocates IP address blocks to various Regional Internet Registries (RIRs) who manage, distribute, and register public Internet number resources within their respective regions (Figure 1-8). These RIRs then allocate IPs to organizations, Internet service providers (ISPs), or, in some cases, National Internet Registries (NIRs) or Local Internet Registries (LIRs) if particular governments require it (mostly in communist countries , dictatorships, etc.):
-
APNIC (http://www.apnic.net) Asia-Pacific region
-
ARIN (http://www.arin.net) North and South America, Sub-Sahara Africa regions
-
LACNIC (http://www.lacnic.net) Latin America and portions of the Caribbean
-
RIPE (http://www.ripe.net) Europe, parts of Asia, Africa north of the equator, and the Middle East regions
-
AfriNIC (http://www.afrinic.net, currently in "observer status") Eventually, both regions of Africa currently handled by ARIN and RIPE
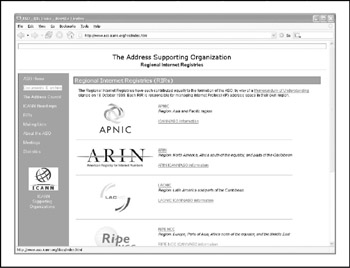
Figure 1-8: Currently there are five Regional Internet Registries (RIRs), four active and one in "observer" status.
The GNSO reviews and develops recommendations on domain-name policy for all generic top-level domains (gTLDs) and advises the ICANN Board on these matters (Figure 1-9). It's important to note that the GNSO is not responsible for domain-name registration, but rather is responsible for the generic top-level domains (for example, .com,.net, .edu, .org, and . info ), which can be found at http://www.iana.org/gtld/gtld.htm.
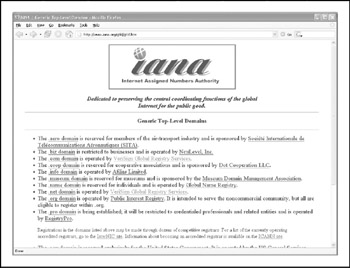
Figure 1-9: The GNSO manages the generic top-level domains (gTLDs).
The CCNSO reviews and develops recommendations on domain-name policy for all country-code top-level domains (ccTLDs) and advises the ICANN Board on these matters. Again, ICANN does not handle domain-name registrations. The definitive list of country-code top-level domains can be found at http://www.iana.org/cctld/cctldwhois.htm (and in Figure 1-10).
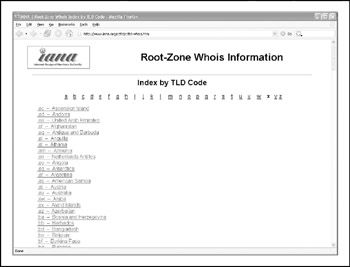
Figure 1-10: The CCNSO manages the country-code top-level domains (ccTLDs).
Here are some other links you may find useful:
-
http://www.iana.org/assignments/ipv4-address-space IP v4 allocation
-
http://www.iana.org/ipaddress/ ip-addresses .htm IP address services
-
http://www.rfc-editor.org/rfc/rfc3330.txt Special-use IP addresses
-
http://www.iana.org/assignments/port-numbers Registered port numbers
-
http://www.iana.org/assignments/protocol-numbers Registered protocol numbers
So, with all of this centralized management in place, mining for information should be as simple as querying a central super-server farm somewhere, right? Not exactly. While the management is fairly centralized, the actual data is spread across the globe in numerous WHOIS servers for technical and political reasons. To further complicate matters, the WHOIS query syntax, type of permitted queries, available data, and the formatting of the results can vary widely from server to server. Furthermore, many of the registrars are actively restricting queries to combat spammers, hackers, and resource overload; and to top it all off, information for .mil and .gov have been pulled from public view entirely due to national security concerns.
So you may ask, "How do I go about finding the data I'm after?" With a few tools, a little know-how, and some patience, you should be able to mine successfully for domainor IP-related registrant details for nearly any registered entity on the planet!
Domain-Related Searches
It's important to note that domain-related items (such as http://www.hackingexposed.com) are registered separately from IP-related items (such as IP net-blocks, BGP autonomous system numbers, etc.). This means we will have two different paths in our methodology for finding these details. Let's start with domain-related details, using http://keyhole.com as an example.
The first order of business is to determine which one of the many WHOIS servers contains the information we're after. The general process flows like this: the authoritative R egistry for a given TLD, ".com" in this case, contains information about which Registrar the target entity registered its domain with. Then you query the appropriate R egistrar to find the R egistrant details for the particular domain name you're after. We refer to these as the "Three Rs" of WHOISRegistry, Registrar, and Registrant.
There are many places on the Internet that offer one-stop -shopping for WHOIS information, but it's important to understand how to find the information yourself for those times that the "auto-magic" tools don't work. Since the WHOIS information is based on a hierarchy, the best place to start is the top of the treeICANN. As mentioned above, ICANN (IANA) is the authoritative registry for all of the TLDs and is great starting point for all manual WHOIS queries.
| Note | You can perform WHOIS lookups from any of the command-line WHOIS clients (requires outbound TCP/43 access) or via the ubiquitous web browser. Our experience shows that the web browser method is usually more intuitive and is nearly always allowed out of most security architectures. |
If we surf to http://whois.iana.org, we can search for the authoritative registry for all of .com. This search (Figure 1-11) shows us that the authoritative registry for .com is Verisign Global Registry Services, at http://www.verisign-grs.com. If we go to that site (Figure 1-12), we can search for http://keyhole.com to find that it is registered through http://www.markmonitor.com. If we go to that site (Figure 1-13), we can query this registrar's WHOIS server via their web interface to find the registrant details for http://www.keyhole.comvoil!
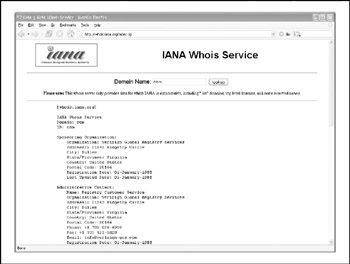
Figure 1-11: We start our domain lookup at http://whois.iana.org.
Figure 1-12: Verisign Global Registry Services shows us which registrar http://keyhole.com is registered with.
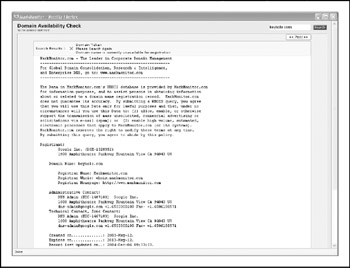
Figure 1-13: We find the registrant details for http://keyhole.com at the appropriate registrar's site.
This registrant detail provides physical addresses, phone numbers, names, e-mail addresses, DNS server names, IPs, and so on. If you follow this process carefully , you shouldn't have too much trouble finding registrant details for any (public) domain name on the planet. Remember, some domains like .gov and .mil may not be accessible to the public via WHOIS.
To be thorough, we could have done the same searches via the command-line WHOIS client with the following three commands:
[bash]$ whois com -h whois.iana.org [bash]$ whois keyhole.com -h whois.verisign-grs.com [bash]$ whois keyhole.com -h whois.omnis.com
There are also several websites that attempt to automate this process with varying degrees of success:
-
http://www.allwhois.com
-
http://www.uwhois.com
-
http://www.internic.net/whois.html
Last but not least, there are several GUIs available that will assist you in your searches too:
-
SamSpade http://www.samspade.org
-
SuperScan http://www.foundstone.com
-
NetScan Tools Pro http://www.nwpsw.com
Once you've homed in on the correct WHOIS server for your target, you may be able to perform other searches if the registrar allows it. You may be able to find all the domains that a particular DNS server hosts , for instance, or any domain name that contains a certain string. These types of searches are rapidly being disallowed by most WHOIS servers, but it is still worth a look to see what the registrar permits . It may be just what you're after.
IP-Related Searches
That pretty well takes care of the domain-related searches, but what about IP-related registrations? As explained earlier, IP-related issues are handled by the various RIRs under ICANN's ASO. Let's see how we go about querying this information.
The WHOIS server at ICANN (IANA) does not currently act as an authoritative registry for all the RIRs as it does for the TLDs, but each RIR does know which IP ranges it manages. This allows us to simply pick any one of them to start our search. If we pick the wrong one, it will tell us which one we need to go to.
Let's say that while perusing your security logs (as I'm sure you do religiously , right?), you run across an interesting entry with a source IP of 61.0.0.2. We start by entering this IP into the WHOIS search at http://www.arin.net (Figure 1-14), which tells us that this range of IPs is actually managed by APNIC. We then go to APNIC's site to continue our search (Figure 1-15). Here we find out that this IP address is actually managed by the National Internet Backbone of India.
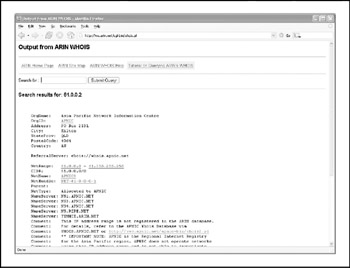
Figure 1-14: ARIN tells us which RIR we need to search.
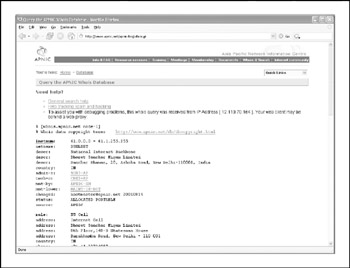
Figure 1-15: It turns out that the IP address is owned by India's National Internet Backbone.
This process can be followed to trace back any IP address in the world to its owner, or at least to a point of contact that may be willing to provide the remaining details. As with anything else, cooperation will vary as you deal with different companies and different governments. Always keep in mind that there are many ways for a hacker to masquerade their true IP. The IP that shows up in your logs may be what we refer to as a "laundered" IP address.
We can also find out IP ranges and BGP autonomous system numbers that an organization "owns" by searching the RIR WHOIS servers for the organization's literal name. For example, if we search for "Google" at http://www.arin.net, we see the IP ranges that Google owns under its name as well as its AS number, AS15169 (Figure 1-16).
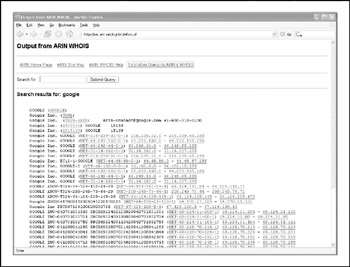
Figure 1-16: Here we see the IP ranges and BGP AS number that Google owns under its name.
Table 1-2 shows a variety of available tools for WHOIS lookups.
| Mechanism | Resources | Platform |
|---|---|---|
| Web interface | http://whois.iana.org | Any platform with a web client |
| WHOIS client | WHOIS is supplied with most versions of UNIX. | UNIX |
| Fwhois was created by Chris Cappuccio <ccappuc@santefe.edu> | ||
| WS_Ping ProPack | http://www.ipswitch.com/ | Windows 95/NT/2000/XP |
| Sam Spade | http://www.samspade.org/ssw | Windows 95/NT/2000/XP |
| Sam Spade Web Interface | http://www.samspade.org/ | Any platform with a web client |
| Netscan tools | http://www. netscantools .com/nstpromain.html | Windows 95/NT/2000/XP |
| Xwhois | http://c64.org/<126>nr/xwhois/ | UNIX with X and GTK+ GUI toolkit |
| Jwhois | http://www.gnu.org/software/jwhois/jwhois.html | UNIX |
The administrative contact is an important piece of information, because it may tell you the name of the person responsible for the Internet connection or firewall. Our query also returns voice and fax numbers. This information is an enormous help when you're performing a dial-in penetration review. Just fire up the war-dialers in the noted range, and you're off to a good start in identifying potential modem numbers. In addition, an intruder will often pose as the administrative contact, using social engineering on unsuspecting users in an organization. An attacker will send spoofed e-mail messages posing as the administrative contact to a gullible user. It is amazing how many users will change their passwords to whatever you like, as long as it looks like the request is being sent from a trusted technical support person.
The record creation and modification dates indicate how accurate the information is. If the record was created five years ago but hasn't been updated since, it is a good bet some of the information (for example, administrative contact) may be out of date.
The last piece of information provides us with the authoritative DNS servers. The first one listed is the primary DNS server; subsequent DNS servers will be secondary, tertiary , and so on. We will need this information for our DNS interrogation , discussed later in this chapter. Additionally, we can try to use the network range listed as a starting point for our network query of the ARIN database.
Public Database Security Countermeasures
Much of the information contained in the various databases discussed thus far is geared for public disclosure. Administrative contacts, registered net blocks, and authoritative nameserver information is required when an organization registers a domain on the Internet. However, security considerations should be employed to make the job of attackers more difficult.
Many times, an administrative contact will leave an organization and still be able to change the organization's domain information. Therefore, first ensure that the information listed in the database is accurate. Update the administrative, technical, and billing contact information as necessary. Consider the phone numbers and addresses listed. These can be used as a starting point for a dial-in attack or for social engineering purposes. Consider using a toll-free number or a number that is not in your organization's phone exchange. In addition, we have seen several organizations list a fictitious administrative contact, hoping to trip up a would-be social engineer. If any employee has e-mail or telephone contact with the fictitious contact, it may tip off the information security department that there is a potential problem.
Another hazard with domain registration arises from how some registrars allow updates. For example, the current Network Solutions implementation allows automated online changes to domain information. Network Solutions authenticates the domain registrant's identity through the Guardian method, which uses three different types of authentication methods : the FROM field in an e-mail, a password, and a Pretty Good Privacy (PGP) key. The weakest authentication method is the FROM field via e-mail. The security implications of this authentication mechanism are prodigious. Essentially, anyone can simply forge an e-mail address and change the information associated with your domain, better known as domain hijacking. This is exactly what happened to AOL on October 16, 1998, as reported by the Washington Post. Someone impersonated an AOL official and changed AOL's domain information so that all traffic was directed to http://www.autonete.net.
AOL recovered quickly from this incident, but it underscores the fragility of an organization's presence on the Internet. It is important to choose a more secure solution, such as a password or PGP authentication, to change domain information. Moreover, the administrative or technical contact is required to establish the authentication mechanism via Contact Form from Network Solutions.
Step 5: DNS Interrogation
After identifying all the associated domains, you can begin to query the DNS. DNS is a distributed database used to map IP addresses to hostnames, and vice versa. If DNS is configured insecurely, it is possible to obtain revealing information about the organization.
Zone Transfers
| Popularity: | 9 |
| Simplicity: | 9 |
| Impact: | 3 |
| Risk Rating: | 7 |
One of the most serious misconfigurations a system administrator can make is allowing untrusted Internet users to perform a DNS zone transfer.
A zone transfer allows a secondary master server to update its zone database from the primary master. This provides for redundancy when running DNS, should the primary name server become unavailable. Generally, a DNS zone transfer needs to be performed only by secondary master DNS servers. Many DNS servers, however, are misconfigured and provide a copy of the zone to anyone who asks. This isn't necessarily bad if the only information provided is related to systems that are connected to the Internet and have valid hostnames, although it makes it that much easier for attackers to find potential targets. The real problem occurs when an organization does not use a public/private DNS mechanism to segregate its external DNS information (which is public) from its internal, private DNS information. In this case, internal hostnames and IP addresses are disclosed to the attacker. Providing internal IP address information to an untrusted user over the Internet is akin to providing a complete blueprint, or roadmap, of an organization's internal network.
Let's take a look at several methods we can use to perform zone transfers and the types of information that can be gleaned. Although many different tools are available to perform zone transfers, we are going to limit the discussion to several common types.
A simple way to perform a zone transfer is to use the nslookup client that is usually provided with most UNIX and Windows implementations . We can use nslookup in interactive mode, as follows :
[bash]$ nslookup Default Server: ns1.example.net Address: 10.10.20.2 > 216.182.1.1 Server: ns1.example.net Address: 10.10.20.2 Name: gate.tellurian.net Address: 216.182.1.1 > set type=any > ls -d Tellurian.net. >\> /tmp/zone_out
We first run nslookup in interactive mode. Once started, it will tell us the default name server that it is using, which is normally the organization's DNS server or a DNS server provided by an ISP. However, our DNS server (10.10.20.2) is not authoritative for our target domain, so it will not have all the DNS records we are looking for. Therefore, we need to manually tell nslookup which DNS server to query. In our example, we want to use the primary DNS server for Tellurian Networks (216.182.1.1). Recall that we found this information from our domain WHOIS lookup performed earlier.
Next we set the record type to "any." This will allow us to pull any DNS records available (man nslookup) for a complete list.
Finally, we use the ls option to list all the associated records for the domain. The -dswitch is used to list all records for the domain. We append a period (.) to the end to signify the fully qualified domain namehowever, you can leave this off most times. In addition, we redirect our output to the file /tmp/zone_out so that we can manipulate the output later.
After completing the zone transfer, we can view the file to see whether there is any interesting information that will allow us to target specific systems. Let's review simulated output, as Tellurian Networks does not allow zone transfers:
[bash]$ more zone_out acct18 1D IN A 192.168.230.3 1D IN HINFO "Gateway2000" "WinWKGRPS" 1D IN MX 0 tellurianadmin-smtp 1D IN RP bsmith.rci bsmith.who 1D IN TXT "Location:Telephone Room" ce 1D IN CNAME aesop au 1D IN A 192.168.230.4 1D IN HINFO "Aspect" "MS-DOS" 1D IN MX 0 andromeda 1D IN RP jcoy.erebus jcoy.who 1D IN TXT "Location: Library" acct21 1D IN A 192.168.230.5 1D IN HINFO "Gateway2000" "WinWKGRPS" 1D IN MX 0 tellurianadmin-smtp 1D IN RP bsmith.rci bsmith.who 1D IN TXT "Location:Accounting"
We won't go through each record in detail, but we will point out several important types. We see that for each entry we have an "A" record that denotes the IP address of the system name located to the right. In addition, each host has an HINFO record that identifies the platform or type of operating system running (see RFC 952). HINFO records are not needed, but they provide a wealth of information to attackers. Because we saved the results of the zone transfer to an output file, we can easily manipulate the results with UNIX programs such as grep, sed, awk, or perl.
Suppose we are experts in SunOS or Solaris. We could programmatically find out the IP addresses that had an HINFO record associated with Sparc, Sun, or Solaris:
[bash]$ grep -i solaris zone_out wc -l 388
We can see that we have 388 potential records that reference the word "Solaris." Obviously, we have plenty of targets.
Suppose we wanted to find test systems, which happen to be a favorite choice for attackers. Why? Simple: they normally don't have many security features enabled, often have easily guessed passwords, and administrators tend not to notice or care who logs in to them. They're a perfect home for any interloper. Thus, we can search for test systems as follows:
[bash]$ grep -i test /tmp/zone_out wc -l 96
So we have approximately 96 entries in the zone file that contain the word "test." This should equate to a fair number of actual test systems. These are just a few simple examples. Most intruders will slice and dice this data to zero in on specific system types with known vulnerabilities.
Keep a few points in mind. First, the aforementioned method queries only one nameserver at a time. This means you would have to perform the same tasks for all nameservers that are authoritative for the target domain. In addition, we queried only the http://www.tellurian.net domain. If there were subdomains, we would have to perform the same type of query for each subdomain (for example, http://www.greenhouse.tellurian.net). Finally, you may receive a message stating that you can't list the domain or that the query was refused . This usually indicates that the server has been configured to disallow zone transfers from unauthorized users. Therefore, you will not be able to perform a zone transfer from this server. However, if there are multiple DNS servers, you may be able to find one that will allow zone transfers.
Now that we have shown you the manual method, there are plenty of tools that speed the process, including host, Sam Spade, axfr, and dig.
The host command comes with many flavors of UNIX. Some simple ways of using host are as follows:
host -l tellurian.net and host -l -v -t any tellurian.net
If you need just the IP addresses to feed into a shell script, you can just "cut" out the IP addresses from the host command:
host -l tellurian.net cut -f 4 -d" " >\> /tmp/ip_out
Not all footprinting functions must be performed through UNIX commands. A number of Windows products, such as Sam Spade, provide the same information.
The UNIX dig command is a favorite with DNS administrators and is often used to troubleshoot DNS architectures. It too can perform the various DNS interrogations mentioned in this section. It has too many command-line options to list here. The man page explains its features in detail.
Finally, you can use one of the best tools for performing zone transfers: axfr (http://packetstormsecurity.nl/groups/ADM/axfr-0.5.2.tar.gz), by Gaius. This utility will recursively transfer zone information and create a compressed database of zone and host files for each domain queried. In addition, you can even pass top-level domains such as com and edu to get all the domains associated with com and edu, respectively. However, this is not recommended due to the vast number of domains within each of these TLDs.
To run axfr, you would type the following:
[bash]$ axfr tellurian.net axfr: Using default directory: /root/axfrdb Found 2 name servers for domain 'tellurian.net.': Text deleted. Received XXX answers (XXX records).
To query the axfr database for the information just obtained, you would type the following:
[bash]$ axfrcat tellurian.net
Determine Mail Exchange (MX) Records
Determining where mail is handled is a great starting place to locate the target organization's firewall network. Often in a commercial environment, mail is handled on the same system as the firewall, or at least on the same network. Therefore, we can use the host command to help harvest even more information:
[bash]$ host tellurian.net tellurian.net has address 216.182.1.7 tellurian.net mail is handled (pri=10) by mail.tellurian.net tellurian.net mail is handled (pri=20) by smtp-forward.tellurian.net
DNS Security Countermeasure
DNS information provides a plethora of data to attackers, so it is important to reduce the amount of information available to the Internet. From a host-configuration perspective, you should restrict zone transfers to only authorized servers. For modern versions of BIND, the allow-transfer directive in the named.conf file can be used to enforce the restriction. To restrict zone transfers in Microsoft's DNS, you can use the Notify option (see http://www.microsoft.com/technet/prodtechnol/windows2000serv/maintain/optimize/c19w2kad.mspx for more information). For other nameservers, you should consult the documentation to determine what steps are necessary to restrict or disable zone transfers.
On the network side, you could configure a firewall or packet-filtering router to deny all unauthorized inbound connections to TCP port 53. Because name lookup requests are UDP and zone transfer requests are TCP, this will effectively thwart a zone-transfer attempt. However, this countermeasure is a violation of the RFC, which states that DNS queries greater than 512 bytes will be sent via TCP. In most cases, DNS queries will easily fit within 512 bytes. A better solution would be to implement cryptographic transaction signatures (TSIGs) to allow only "trusted" hosts to transfer zone information. For a great primer on TSIG security in Bind 9, see http://www.linux-mag.com/2001-11/bind9_01.html.
Restricting zone transfers will increase the time necessary for attackers to probe for IP addresses and hostnames. However, because name lookups are still allowed, attackers could manually perform reverse lookups against all IP addresses for a given net block. Therefore, you should configure external nameservers to provide information only about systems directly connected to the Internet. External nameservers should never be configured to divulge internal network information. This may seem like a trivial point, but we have seen misconfigured nameservers that allowed us to pull back more than 16,000 internal IP addresses and associated hostnames. Finally, we discourage the use of HINFO records. As you will see in later chapters, you can identify the target system's operating system with fine precision. However, HINFO records make it that much easier to programmatically cull potentially vulnerable systems.
Step 6: Network Reconnaissance
Now that we have identified potential networks, we can attempt to determine their network topology as well as potential access paths into the network.
Tracerouting
| Popularity: | 9 |
| Simplicity: | 9 |
| Impact: | 2 |
| Risk Rating: | 7 |
To accomplish this task, we can use the traceroute (ftp://www.ee.lbl.gov/traceroute.tar.gz) program that comes with most flavors of UNIX and is provided in Windows. In Windows, it is spelled tracert due to the 8.3 legacy filename issues.
traceroute is a diagnostic tool originally written by Van Jacobson that lets you view the route that an IP packet follows from one host to the next. traceroute uses the time-tolive (TTL) option in the IP packet to elicit an ICMP TIME_EXCEEDED message from each router. Each router that handles the packet is required to decrement the TTL field. Thus, the TTL field effectively becomes a hop counter. We can use the functionality of traceroute to determine the exact path that our packets are taking. As mentioned previously, traceroute may allow you to discover the network topology employed by the target network, in addition to identifying access control devices (such as an applicationbased firewall or packet-filtering routers) that may be filtering our traffic.
Let's look at an example:
[bash]$ traceroute tellurian.net traceroute to tellurian.net (216.182.1.7), 30 hops max, 38 byte packets 1 (205.243.210.33) 4.264 ms 4.245 ms 4.226 ms 2 (66.192.251.0) 9.155 ms 9.181 ms 9.180 ms 3 (168.215.54.90) 9.224 ms 9.183 ms 9.145 ms 4 (144.232.192.33) 9.660 ms 9.771 ms 9.737 ms 5 (144.232.1.217) 12.654 ms 10.145 ms 9.945 ms 6 (144.232.1.173) 10.235 ms 9.968 ms 10.024 ms 7 (144.232.8.97) 133.128 ms 77.520 ms 218.464 ms 8 (144.232.18.78) 65.065 ms 65.189 ms 65.168 ms 9 (144.232.16.252) 64.998 ms 65.021 ms 65.301 ms 10 (144.223.15.130) 82.511 ms 66.022 ms 66.170 11 www.tellurian.net (216.182.1.7) 82.355 ms 81.644 ms 84.238 ms
We can see the path of the packets traveling several hops to the final destination. The packets go through the various hops without being blocked. We can assume this is a live host and that the hop before it (10) is the border router for the organization. Hop 10 could be a dedicated application-based firewall, or it could be a simple packet-filtering devicewe are not sure yet. Generally, once you hit a live system on a network, the system before it is a device performing routing functions (for example, a router or a firewall).
This is a very simplistic example. In a complex environment, there may be multiple routing pathsthat is, routing devices with multiple interfaces (for example, a Cisco 7500 series router) or load balancers. Moreover, each interface may have different access control lists (ACLs) applied. In many cases, some interfaces will pass your traceroute requests, whereas others will deny them because of the ACL applied. Therefore, it is important to map your entire network using traceroute. After you "traceroute" to multiple systems on the network, you can begin to create a network diagram that depicts the architecture of the Internet gateway and the location of devices that are providing access control functionality. We refer to this as an access path diagram.
It is important to note that most flavors of traceroute in UNIX default to sending User Datagram Protocol (UDP) packets, with the option of using Internet Control Messaging Protocol (ICMP) packets with the -I switch. In Windows, however, the default behavior is to use ICMP echo request packets. Therefore, your mileage may vary using each tool if the site blocks UDP versus ICMP, and vice versa. Another interesting item of traceroute is the -g option, which allows the user to specify loose source routing. Therefore, if you believe the target gateway will accept source-routed packets (which is a cardinal sin), you might try to enable this option with the appropriate hop pointers (see man trace-route in UNIX for more information).
Several other switches that we need to discuss may allow us to bypass access control devices during our probe. The -p n option of traceroute allows us to specify a starting UDP port number (n) that will be incremented by 1 when the probe is launched. Therefore, we will not be able to use a fixed port number without some modification to traceroute. Luckily, Michael Schiffman has created a patch (http://www.packetfactory.net/Projects/ firewalk /traceroute.diff) that adds the -S switch to stop port incrementation for traceroute version 1.4a5 (ftp://ftp.cerias.purdue.edu/pub/tools/unix/ netutils /traceroute/old). This allows us to force every packet we send to have a fixed port number, in the hopes that the access control device will pass this traffic. A good starting port number would be UDP port 53 (DNS queries). Because many sites allow inbound DNS queries, there is a high probability that the access control device will allow our probes through.
[bash]$ traceroute 10.10.10.2 traceroute to (10.10.10.2), 30 hops max, 40 byte packets 1 gate (192.168.10.1) 11.993 ms 10.217 ms 9.023 ms 2 rtr1.bigisp.net (10.10.12.13)37.442 ms 35.183 ms 38.202 ms 3 rtr2.bigisp.net (10.10.12.14) 73.945 ms 36.336 ms 40.146 ms 4 hssitrt.bigisp.net (10.11.31.14) 54.094 ms 66.162 ms 50.873 ms 5 * * * 6 * * *
We can see in this example that our traceroute probes, which by default send out UDP packets, were blocked by the firewall.
Now let's send a probe with a fixed port of UDP 53, DNS queries:
[bash]$ traceroute -S -p53 10.10.10.2 traceroute to (10.10.10.2), 30 hops max, 40 byte packets 1 gate (192.168.10.1) 10.029 ms 10.027 ms 8.494 ms 2 rtr1.bigisp.net (10.10.12.13) 36.673 ms 39.141 ms 37.872 ms 3 rtr2.bigisp.net (10.10.12.14) 36.739 ms 39.516 ms 37.226 ms 4 hssitrt.bigisp.net (10.11.31.14)47.352 ms 47.363 ms 45.914 ms 5 10.10.10.2 (10.10.10.2) 50.449 ms 56.213 ms 65.627 ms
Because our packets are now acceptable to the access control devices (hop 4), they are happily passed. Therefore, we can probe systems behind the access control device just by sending out probes with a destination port of UDP 53. Additionally, if you send a probe to a system that has UDP port 53 listening, you will not receive a normal ICMP unreachable message back. Therefore, you will not see a host displayed when the packet reaches its ultimate destination.
Most of what we have done up to this point with traceroute has been command-line oriented. For the graphically inclined, you can use VisualRoute (http://www.visualroute.com), NeoTrace (http://www.neotrace.com), or Trout (http://www.foundstone.com) to perform your tracerouting. VisualRoute and NeoTrace provide a graphical depiction of each network hop and integrate this with WHOIS queries. Trout's multithreaded approach makes it one of the fastest traceroute utilities. VisualRoute is appealing to the eye but does not scale well for large-scale network reconnaissance.
It's important to note that because the TTL value used in tracerouting is in the IP header, we are not limited to UDP or ICMP packets. Literally any IP packet could be sent. This provides for alternate tracerouting techniques to get our probes through firewalls that are blocking UDP and ICMP packets. Two tools that allow for TCP tracerouting to specific ports are the aptly named tcptraceroute (http://michael.toren.net/code/tcptraceroute) and Cain & Abel (http://www.oxid.it). Additional techniques allow you to determine specific ACLs that are in place for a given access control device. Firewall protocol scanning is one such technique as well as a tool called firewalk; both are covered in Chapter 11.
Thwarting Network Reconnaissance Countermeasure
In this chapter, we touched on only network reconnaissance techniques. You'll see more intrusive techniques in the following chapters. However, several countermeasures can be employed to thwart and identify the network reconnaissance probes discussed thus far. Many of the commercial network intrusion-detection systems (NIDS) and intrusionprevention systems (IPS) will detect this type of network reconnaissance. In addition, one of the best free NIDS programsSnort (http://www.snort.org), by Marty Roeschcan detect this activity. For those who are interested in taking the offensive when someone traceroutes to you, Humble from Rhino9 developed a program called RotoRouter (http://www.ussrback.com/UNIX/loggers/rr.c.gz). This utility is used to log incoming traceroute requests and generate fake responses. Finally, depending on your site's security paradigm, you may be able to configure your border routers to limit ICMP and UDP traffic to specific systems, thus minimizing your exposure.
EAN: N/A
Pages: 127