Optimizing Unconditional Jumps and Function Calls
Optimizing Unconditional Jumps and Function Calls
The commands of unconditional jumps and function calls produce a certain impact on performance as well. That is why you should reduce the number of these commands if possible. How can these commands slow down the application performance?
The commands of unconditional jumps and function calls have a complex nature and require a large number of processor microoperations. These are needed for forming the executable addresses, rearranging the command pipeline, especially if the code contains a chain of such commands.
What affects performance greatly is that the unconditional jump commands may force out other jump commands from the special processor memory buffer that stores the jump addresses available. This buffer, called Branch Target Buffer (BTB), has an extremely important role in organizing the branches and jumps in the program. The algorithm for replacing the unused buffer commands is based on random selection, and this may cause a considerable delay in programs containing a lot of branches.
Reducing Unconditional Jumps and Branches
To reduce the number of unconditional jumps and branches, you can rearrange the structure of the program code. Each specific case will have an individual solution, but still, there are some general guidelines:
-
If one jump command is followed by another, you can replace such a sequence by a single jump to the last label.
-
A jump to the return command ( ret ) can be replaced by the return command itself.
As an example, we will optimize the code for a function (we will call it myproc ), containing the following sequence of commands:
myproc PROC . . . <assembly code> . . . jmp ex . . . ex: ret myproc ENDP
This code fragment may be replaced by a more efficient one (with the changes shown in bold):
myproc PROC . . . <assembly code> . . . ret . . . ret myproc ENDP
The jmp ex command, performing a jump to the label where the program exits the myproc function, is replaced by the ret command. The use of the other ret commands is determined by the function algorithm.
Avoiding Double Returns
If you need to call a function (or procedure) from within another one, it is highly recommended that you avoid the so-called double return. This would eliminate the need for manipulations with the stack pointer, which present an obstacle to the processor prediction mechanism. For instance, it is a good idea to replace such function call command as
call myproc . . . ret
by the unconditional jump command: jmp myproc . In this case, the return from the main function would be performed by the ret command of the myproc procedure. Such manipulations may seem difficult to understand, so we will use an example to explain these matters in more detail.
We will now use C++ .NET to develop a simple console application that will contain a call of an assembly function (say, fcall ). The fcall function calculates the difference between the two integers (the i1 and i2 variables in the main program), and then calls the mul3 function that multiplies this difference by 3. This result is returned to the main program and displayed on the screen.
Listing 1.16 shows the source code of the non-optimized assembly module intended for compiling in the macroassembler environment MASM 6.14.
| |
.686 .model flat public _fcall .code _fcall PROC push EBP mov EBP, ESP ; Stores the contents of the i1 variable in the EAX register mov EAX, DWORD PTR [EBP+8] sub EAX, DWORD PTR [EBP+12] call _mul3 pop EBP ret _fcall ENDP _mul3 PROC mov EBX, 3 imul EBX ret _mul3 ENDP end
| |
The i1 and i2 variables are transferred through the stack. We find the difference between them and place it to the EAX register. These operations are performed by the following commands:
mov EAX, DWORD PTR [EBP+8] sub EAX, DWORD PTR [EBP+12]
Then we call the mul3 function that multiplies the result in EAX by 3. Note that we use the call command to call the mul3 function. To return to the main C++ program, the two ret commands are used. Now, we will optimize the assembly code as shown in Listing 1.17 (the changes are marked in bold).
| |
.686 .model flat public _fcall .code _fcall PROC push EBP mov EBP, ESP mov EAX, DWORD PTR [EBP+8] ; i1 sub EAX, DWORD PTR [EBP+12] ; i2 pop EBP jmp _mul3 _fcall ENDP _mul3 PROC mov EBX, 3 imul EBX ret _mul3 ENDP end
| |
As you can see from the listing, the call _mul3 command has been removed, and the pop EBP command is now placed before the jump to the procedure label. Before the jmp _mul3 command is performed, the stack contains the address for returning to the main program. After multiplying the contents of the EAX register by 3, there is a return, performed by the ret command of the mul3 function.
Listing 1.8 shows the source code of the console application created in C++ .NET 2003. This console application uses the result of the calculations programmed in the previous listing.
| |
// REPLACE_CALL_WITH_JMP_DEMO.cpp : Defines the entry point // for the console application #include "stdafx.h" extern "C" int fcall(int i1, int i2); int _tmain(int argc, _TCHAR* argv[]) { int i1, i2; printf("AVOIDING DOUBLE RETURN IN ASM FUNCTIONS\n"); while (true) { printf("\nEnter i1: "); scanf("%d", &i1); printf("Enter i2: "); scanf("%d", &i2); printf("(i1 i2)*3 = %d\n", fcall(i1, i2)); } return 0; } | |
Fig. 1.2 illustrates the window with this application running.
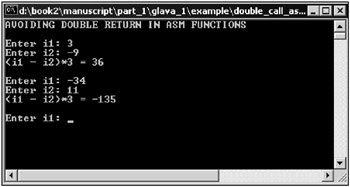
Fig. 1.2: Application that calls assembly functions and uses a single return command
Repeating the Code Fragment
Another method for eliminating redundant unconditional jumps is to repeat the needed code fragment at the point where you run into the jmp command. We will consider a practical example.
Suppose you have an array of integers. The task is to select all its positive numbers and save them in one array, and also to select all the negative numbers and save them in another array. Suppose the original array contains 8 elements. To simplify the task, suppose that half of the numbers are positive, and half are negative. So, the two supplementary arrays have the dimension of 4. In Listing 1.19, you can see the source code of the assembly function that performs the required manipulations.
| |
. . . push EBX ; Places the address of the original array to the ESI register, ; the address of the array for negative numbers to the EDI register, ; and the address of the array for positive numbers to EBX lea ESI, i1 lea EDI, ineg lea EBX, ipos ; Places the size of the original array (i1) to the EDX register mov EDX, 8 next_int: ; Checks if the element of the i1 array is equal to 0 cmp DWORD PTR [ESI], 0 ; If the element is equal or greater than 0, ; writes it to the ipos array jge store_pos ; Otherwise, writes it to the ineg array for negative numbers: mov EAX, DWORD PTR [ESI] mov DWORD PTR [EDI], EAX add EDI, 4 ; Jumps to the common branch of the program jmp next store_pos: mov EAX, DWORD PTR [ESI] mov DWORD PTR [EBX], EAX add EBX, 4 next: dec EDX jz ex add ESI, 4 jmp next_int ex: pop EBX . . .
| |
In this code fragment, the optimization can be achieved by eliminating the unconditional jump command ” jmp next (shown in bold). Instead of this command, you can repeat the needed code fragment. The source code of the modified version of the program is shown in Listing 1.20.
| |
. . . push EBX lea ESI, i1 lea EDI, ineg lea EBX, ipos mov EDX, 8 next_int: cmp DWORD PTR [ESI], 0 jge store_pos mov EAX, DWORD PTR [ESI] mov DWORD PTR [EDI], EAX add EDI, 4 dec EDX jz ex add ESI, 4 jmp next_int store_pos: mov EAX, DWORD PTR [ESI] mov DWORD PTR [EBX], EAX add EBX, 4 dec EDX jz ex add ESI, 4 jmp next_int ex: pop EBX . . .
| |
The changes made to the original program are shown in bold. As you can see from the original listing, removing the jmp next command required us to insert several commands from the common branch, which is marked as next in Listing 1.19.
Replacing Loop Commands by Jumps and Comparisons
There is another important note concerning loop calculations. The existing loop commands and their modifications ( loope , loopne , loopz , loopnz ) slow down the overall performance of the program and are indeed an anachronism to the modern processor models. To create fast applications, it is better to replace them with the combination of cmp/jmp commands.
For example, the loop that uses the ECX register as a counter and contains the loop command (one of the most frequently used) is the least efficient:
. . . mov ECX, counter . . . label_1: . . . <assembly commands> . . . loop label_1 . . .
There are two drawbacks to this loop. First, the loop command cannot be optimized by the processor well enough, and further, only the ECX register can be used as the loop counter. The second disadvantage is that the ECX register is decremented by 1, making it difficult to unroll the loop by expanding to the next step.
You can replace the loop command with the following sequence:
. . . mov ECX, counter . . . label_1: . . . <assembly commands> . . . dec ECX jnz label_1 . . .
In this code fragment, you can decrement the ECX counter by a value other than 1, which provides you with certain options for optimizing the code.
A somewhat worse variant, yet faster than the one with the loop , may look like this:
. . . xor EDX, EDX . . . label_1: . . . <assembly commands> . . . inc EDX cmp EDX, counter jb label_1 . . .
In this case, you need to use the cmp command to check the loop exit condition, and this requires additional processor cycles. This loop is easy to unroll, too.
EAN: 2147483647
Pages: 50